日志系统架构-ELK
企业级日志系统架构-ELK
一、ELK的架构
1.1 讲在之前
当我们管理和使用的后端服务程序突破单台场景,进入到集群部署场景时,日志文件就会散落在多台后端服务器上。
这时候要查看、统计日志信息就需要到各个服务器上去取和查看,这会给我们对服务器的管理产生了极大的困难,所以我们可能很想把这些日志文件归集到一个统一的地方,统一管理,那服务器上一般有哪些日志类型呢?
一般有这么几类:异常日志、请求日志、操作日志。
异常日志是大家写代码时经常看到的日志堆栈,这类日志有很多行,详细列出了异常信息、异常名称、出错的代码调用栈、内部异常原因(Caused by),是一类多行日志。
请求日志是接口的调用日志,常见的是nginx、tomcat、weblogic等负载均衡和web容器的日志,一行里面包含了访问时间、访问路径、状态码、结果大小、响应时间等信息。也有一些自定义的信息,比如SLA统计系统或者一些性能监控系统所需的日志信息,一般来说会包含请求编号、访问路径、步骤编号、响应时间等自定义的信息。
操作日志一般是用来审计或者结果追踪的信息,这类信息一般会专门的做统一存储,这类日志也比较重要,一般用数据库专门存储。
在ELK使用的场景中,多见的是对异常日志和请求日志的统一处理。
然而,由于请求日志一般来说生成的速度比较快。是至少相当于系统访问量,通常大于访问量,因为日志记录大多还会记录系统下游接口的访问日志,缓存访问日志等。因此,对于请求日志放到ELK的可能也不是特别多见,而是通过脚本针对特定的需求进行收集和查询。
1.2 什么是ELK?
https://www.elastic.co
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。根据 Google Trend 的信息显示,ELK Stack 已经成为目前最流行的集中式日志解决方案。
1) Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
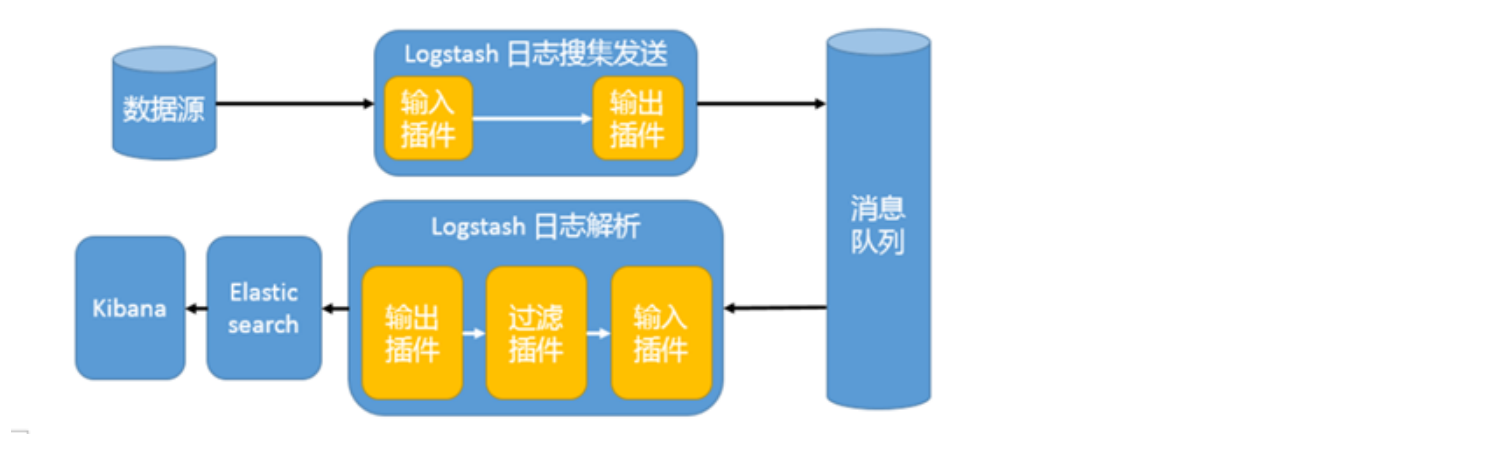
2) Logstash:数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
3) Kibana:数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
4) Filebeat:ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
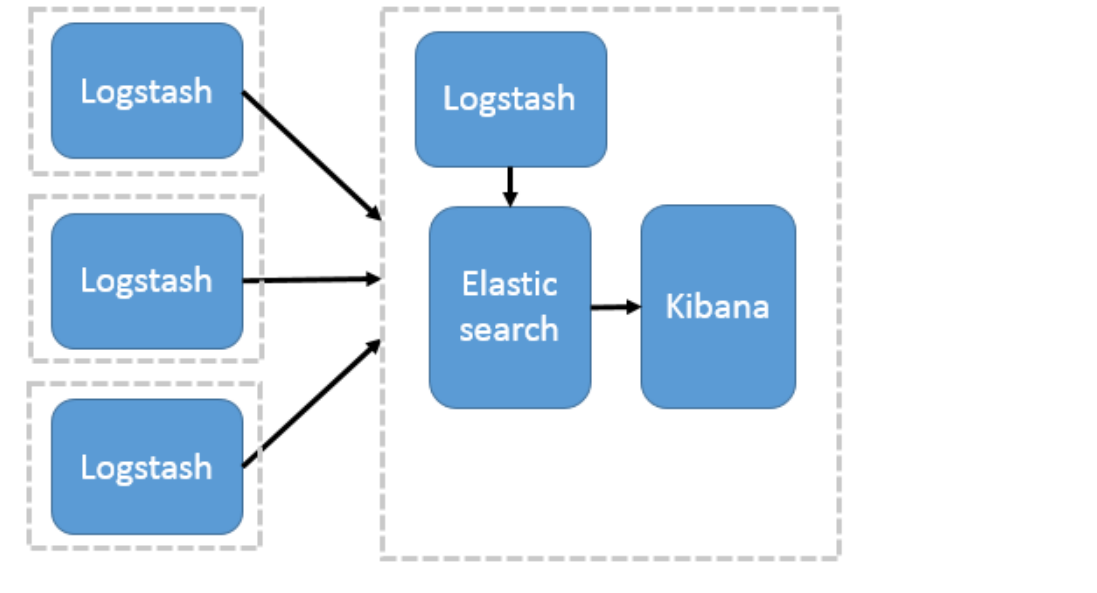
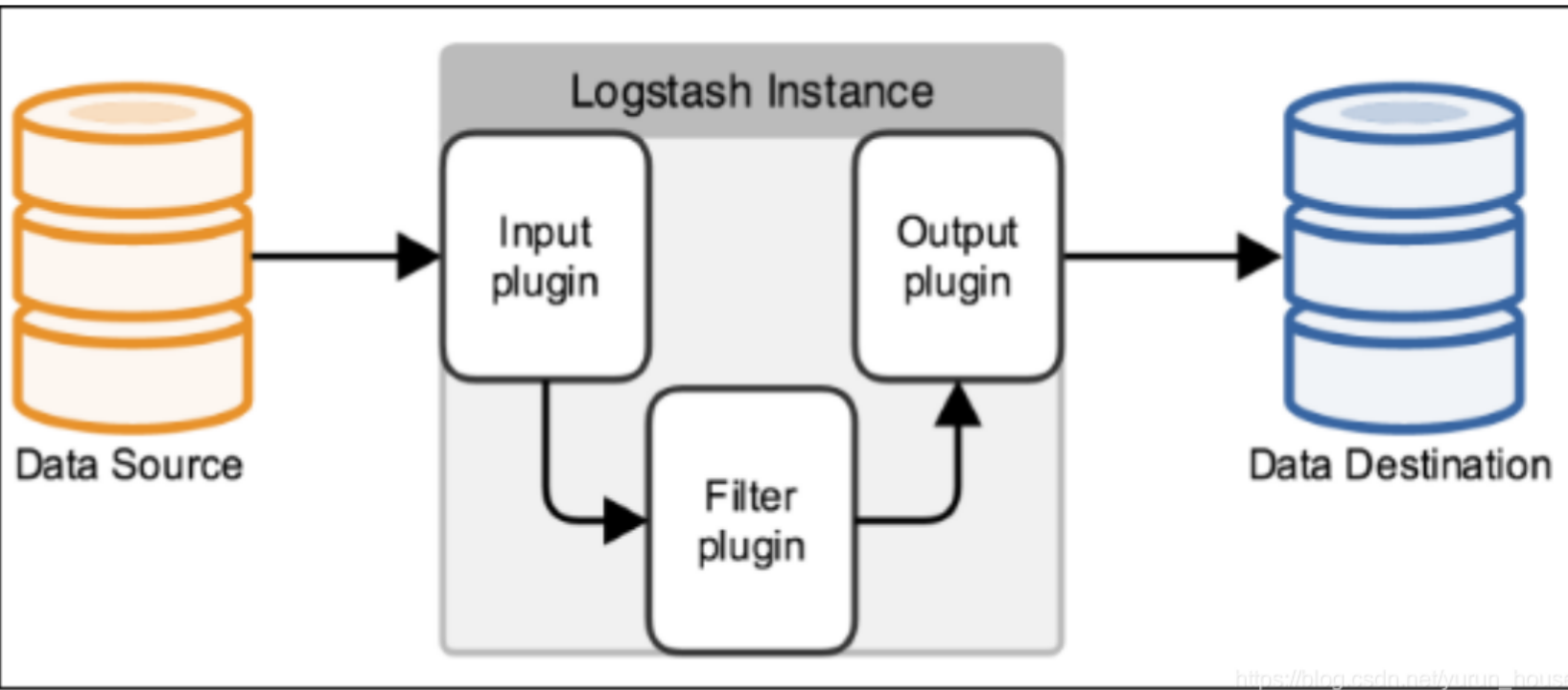
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
1.3 ELK一般用来做啥?
ELK组件在海量日志系统的运维中,可用于解决:
1、分布式日志数据集中式查询和管理
2、系统监控,包含系统硬件和应用各个组件的监控
3、故障排查
4、安全信息和事件管理
5、报表功能
1.4 ELK有何优势?
1. 强大的搜索功能,elasticsearch可以以分布式搜索的方式快速检索,而且支持DSL的语法来进行搜索,简单的说,就是通过类似配置的语言,快速筛选数据。
2. 完美的展示功能,可以展示非常详细的图表信息,而且可以定制展示内容,将数据可视化发挥的淋漓尽致。
3. 分布式功能,能够解决大型集群运维工作很多问题,包括监控、预警、日志收集解析等。
1.5 日志收集
对于日志收集来讲,目前有两种方式
1.5.1 logstash方式
1.5.2 filebeat
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括六种:
Packetbeat:网络数据(收集网络流量数据)
Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
Filebeat:日志文件(收集文件数据)
Winlogbeat:windows事件日志(收集Windows事件日志数据)
Auditbeat:审计数据(收集审计日志)
Heartbeat:运行时间监控(收集系统运行时的数据)
Functionbeat :functionbeat 即能收集、传送并监测来自您的云服务的相关数据。

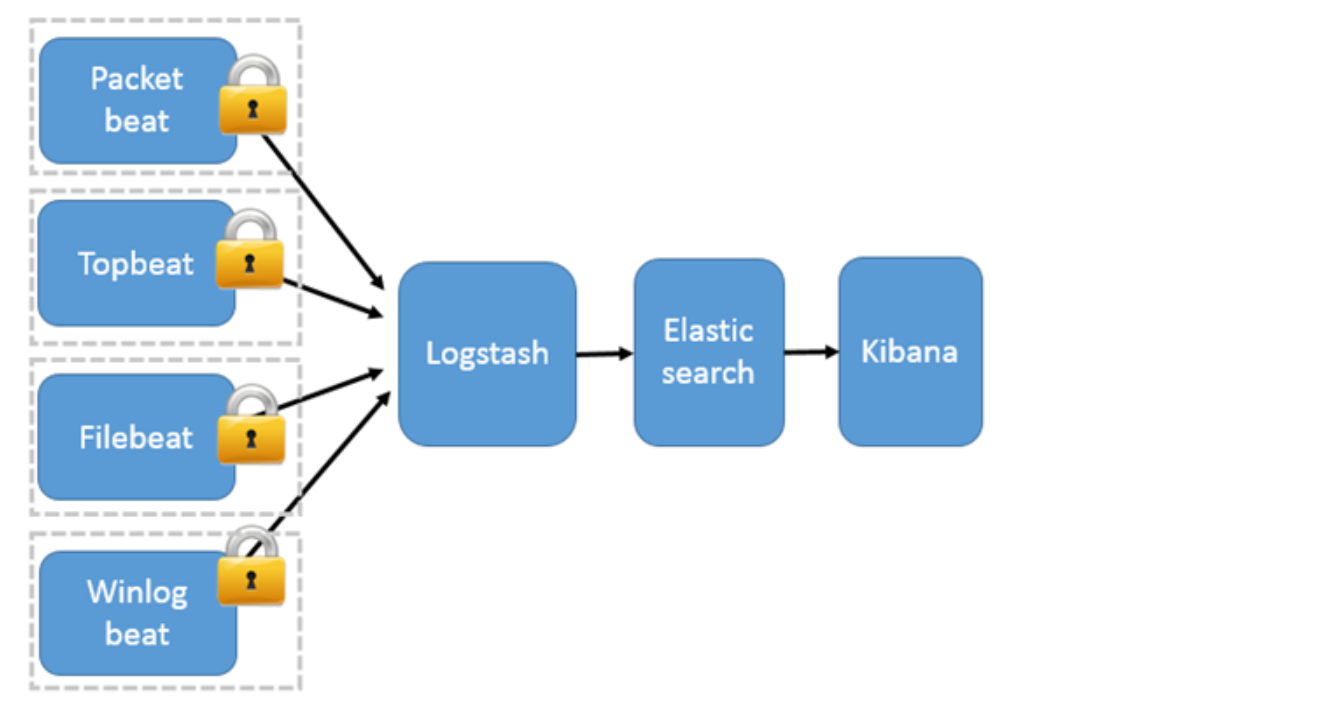
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景
Beats 还不支持输出到[消息队列](新版本除外:5.0版本及以上),所以在消息队列前后两端只能是 Logstash 实例。logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题
工作流程:
Filebeat采集—> logstash转发到redis/kafka—> logstash处理从kafka/redis缓存的数据进行分析—> 输出到es—> 显示在kibana
二、部署ELK架构
官方软件下载地址:https://www.elastic.co/cn/downloads
2.1 ELK部署的架构图
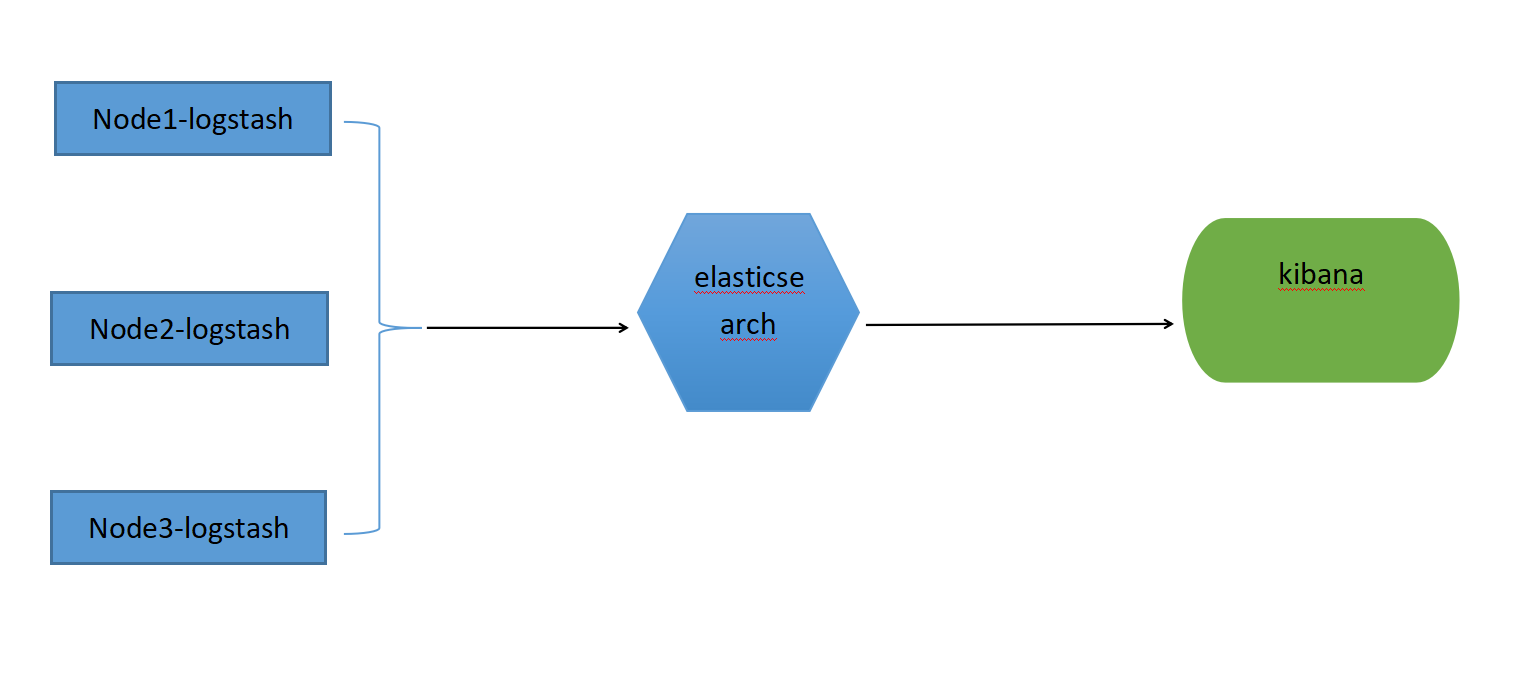
1、logstash负责收集应用写到磁盘上的日志,并将日志发送给elasticsearch,并将处理后的日志保存elasticsearch索引库。
2、kibana从elasticsearch搜索日志,并展示到页面
注意:这里我们可以使用filebeat来作为日志收集工具,filebeat收集用户应用的日志后发送给logstash,logstash将日志再传输给elasticsearch处理和存储,kibana从elasticsearch搜索日志,并展示到页面
2.2 软件要求
当前最大的版本是8.9的版本,当前我们使用的ELK的版本是6.8的版本
| 系统 | ip | 组件 |
|---|---|---|
| centos7.9 | 192.168.1.100 | elasticsearch,jdk1.8 |
| centos7.9 | 192.168.1.101 | logstash , jdk1.8 |
| centos7.9 | 192.168.1.102 | kibana, jdk1.8 |
| centos7.9 | 192.168.1.103 | elasticsearch,jdk1.8 |
2.3 安装Elasticsearch
# 配置 JAVA 环境
[root@es/usr/local/src]$ tar xf jdk-8u311-linux-x64.tar.gz
[root@es/usr/local/src]$ vim /etc/profile.d/jdk.sh
JAVA_HOME=/usr/local/src/jdk1.8.0_311
JAVA_BIN=$JAVA_HOME/bin
PATH=$JAVA_BIN:$JRE_BIN:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
# 调整文件连接数
[root@es/usr/local/src]$ cat >>/etc/security/limits.conf<<EOF
* hard nofile 65536
* soft nofile 65536
* soft nproc 65536
* hard nproc 65536
EOF
# 创建elasticsearch用户
[root@es/usr/local/src]$ useradd elasticsearch
# 创建数据存放目录并授权
[root@es/usr/local/src]$ mkdir /var/log/elasticsearch -p && chown elasticsearch.elasticsearch /var/log/elasticsearch -R
# 创建日志存放目录并授权
[root@es/usr/local/src]$ mkdir -p /var/log/elasticsearch && chown elasticsearch.elasticsearch /var/log/elasticsearch/ -R
# 对 elasticsearch 目录授权
[root@es/usr/local/src]$ chown elasticsearch.elasticsearch /usr/local/src/elasticsearch-6.8.20 -R
# 内核配置文件种修改vm.max_map_count的值
cat > /etc/sysctl.conf <<EOF
vm.max_map_count = 262144
EOF
sysctl -p
# 修改 elasticsearch.yml 配置文件
vim /usr/local/src/elasticsearch-6.8.20/config/elasticsearch.yml
cluster.name: my-es #指定集群的命中
node.name: es-1 #指定节点的名字
path.data: /data/es-data #指定数据目录
path.logs: /var/log/elasticsearch #指定日志目录
network.host: 0.0.0.0 #指定监听的IP
http.port: 9200 #指定监听的端口
discovery.zen.ping.unicast.hosts: ["host1", "host2"] # 指定主机
# 切换到 elasticsearch 用户
# -d 参数放后台启动
./elasticsearch -d
2.3.1 安装jdk
[root@es opt]# rpm -ivh jdk-8u381-linux-x64.rpm
[root@elasticsearch/var/log/elasticsearch]$ vim /etc/profile.d/jdk.sh
JAVA_HOME=/usr/local/src/jdk1.8.0_311
JAVA_BIN=$JAVA_HOME/bin
JRE_HOME=$JAVA_HOME/jre
JRE_BIN=$JRE_HOME/bin
PATH=$JAVA_BIN:$JRE_BIN:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH
[root@es opt]# java -version
java version "1.8.0_381"
Java(TM) SE Runtime Environment (build 1.8.0_381-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.381-b09, mixed mode)
2.3.2 导入elasticsearch的repo仓库
[root@es opt]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[root@es opt]# cat /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
2.3.3 安装elasticsearch
[root@es opt]# yum install --enablerepo=elasticsearch elasticsearch -y
2.3.4 开始配置elasticsearch
[root@es opt]# grep -v "^#" /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es #指定集群的名字,该名字是集群唯一的
node.name: es-1 #当前节点的名字
path.data: /var/lib/elasticsearch #数据存放路径(通常建议使用一个专门的独立磁盘存放磁盘)
path.logs: /var/log/elasticsearch #日志存放路径
network.host: 192.168.1.100 #当前主机的IP
http.port: 9200 #端口号(9200表示对外提供服务端口,9300表示集群内部通信端口)
discovery.zen.ping.unicast.hosts: ["192.168.1.100", "192.168.1.103"] #集群内组播地址
http.cors.enabled: true
http.cors.allow-origin: "*"
2.3.5 启动服务
[root@es ~]# systemctl enable --now elasticsearch
2.3.6 查看端口状态
[root@es ~]# netstat -antup|grep java
tcp6 0 0 192.168.1.100:9300 :::* LISTEN 9808/java
tcp6 0 0 192.168.1.100:9200 :::* LISTEN 9808/java
#9200端口是数据传输端口;
#9300端口是集群通信端口;
2.3.7 浏览器测试
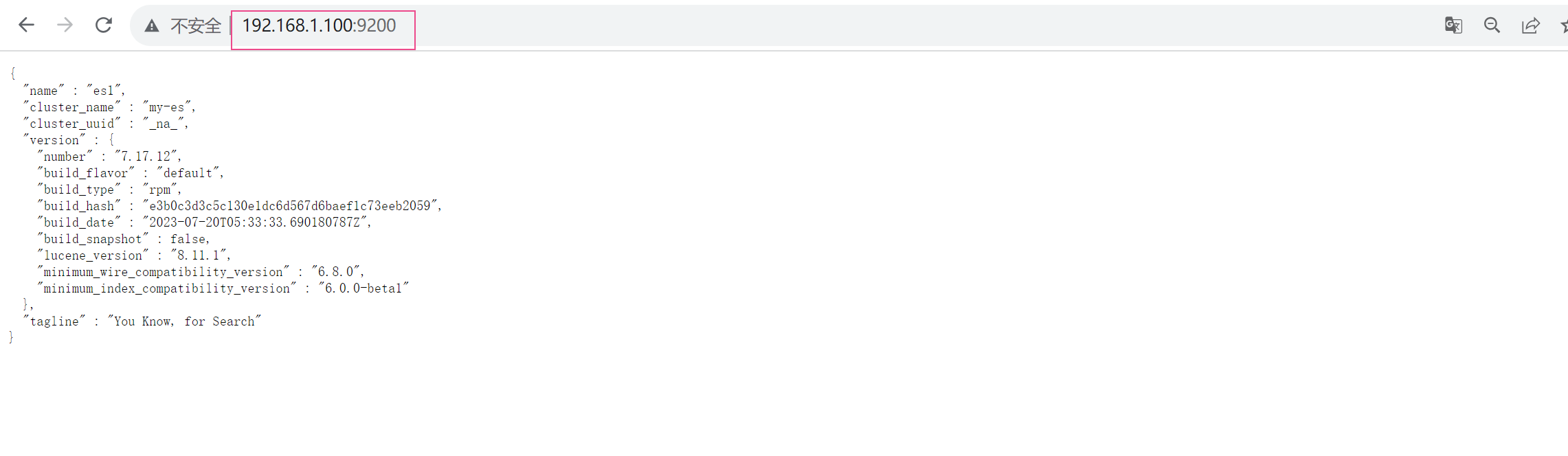
[root@elasticsearch src]# curl http://10.0.0.12:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1, ##集群节点
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
2.3.8 安装elasticsearch双节点集群
安装过程请参考上述的安装过程。
集群节点1:
#elasticsearch.yml配置
[root@es elasticsearch]# grep -v '^#' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es
node.name: es-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.1.100
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.1.100", "192.168.1.103"]
集群节点2:
#elasticsearch.yml配置
[root@es2 ~]# grep -v '^#' /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es
node.name: es-2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.1.103
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.1.100", "192.168.1.103"]
查看状态
[root@es elasticsearch]# curl http://10.0.0.12:9200/_cluster/health?pretty
{
"cluster_name" : "my-es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 6,
"active_shards" : 12,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
2.4 关于ES集群中的脑裂问题
2.4.1 集群脑裂
所谓脑裂问题,就是同一个集群中的不同节点,对于集群的状态有了不一样的理解,比如集群中存在两个master,正常情况下我们集群中只能有一个master节点。
2.4.2 集群脑裂场景举例
如果因为网络的故障,导致一个集群被划分成了两片,每片都有多个node,以及一个master,那么集群中就出现了两个master了。但是因为master是集群中非常重要的一个角色,主宰了集群状态的维护,以及shard的分配,因此如果有两个master,可能会导致数据异常。
如:
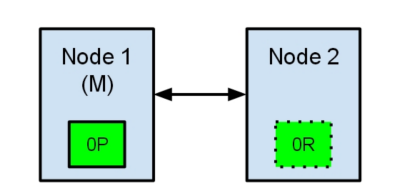
节点1在启动时被选举为主节点并保存主分片标记为0P,而节点2保存副本分片标记为0R。
现在,如果在两个节点之间的通讯中断了,会发生什么?由于网络问题或只是因为其中一个节点无响应,这是有可能发生的。
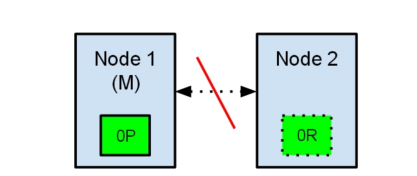
两个节点都相信对方已经挂了。节点1不需要做什么,因为它本来就被选举为主节点。但是节点2会自动选举它自己为主节点,因为它相信集群的一部分没有主节点了。
在elasticsearch集群,是有主节点来决定将分片平均的分布到节点上的。节点2保存的是复制分片,但它相信主节点不可用了。所以它会自动提升Node2节点为主节点。
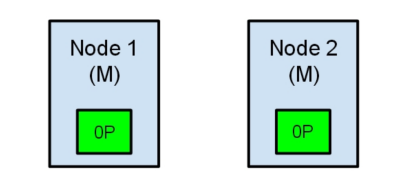
现在我们的集群在一个不一致的状态了。打在节点1上的索引请求会将索引数据分配在主节点,同时打在节点2的请求会将索引数据放在分片上。在这种情况下,分片的两份数据分开了,如果不做一个全量的重索引很难对它们进行重排序。在更坏的情况下,一个对集群无感知的索引客户端(例如,使用REST接口的),这个问题非常透明难以发现,无论哪个节点被命中索引请求仍然在每次都会成功完成。问题只有在搜索数据时才会被隐约发现:取决于搜索请求命中了哪个节点,结果都会不同。
2.4.3 脑裂解决方案
在elasticsearch.yml中配置属性:discovery.zen.minimum_master_nodes,它的值默认是1,这个参数的作用,就是告诉es直到有足够的master候选节点支持时,才可以选举出一个master,否则就不要选举出一个master。
这个参数设置有个算法就是:master候选资格节点数量 / 2 + 1,所有有资格成为master的节点都需要加上这个配置。
假设我们有10个节点,都能维护数据,也都有资格成为master节点,那么quorum就是10 / 2 + 1 = 6;假设我们有5个节点,那么quorum就是5/2 + 1 = 3。
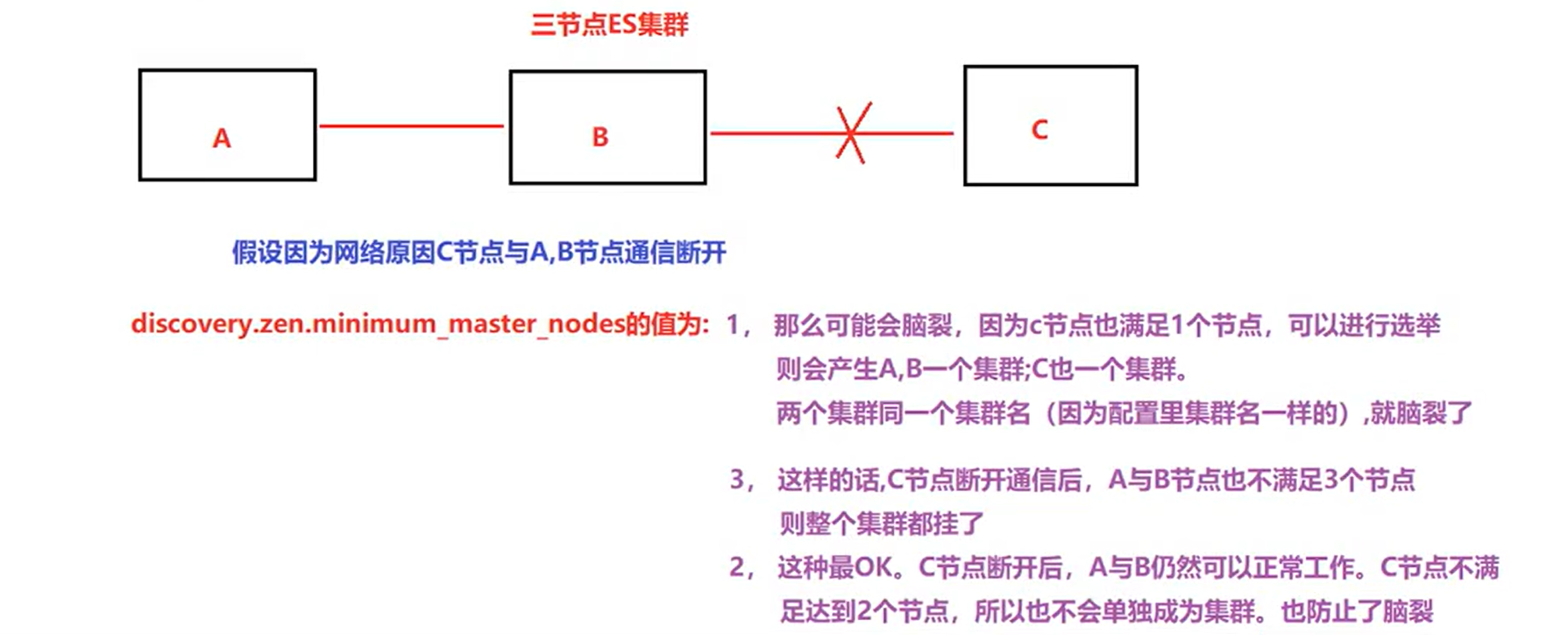
思考一下假设集群中共有2个节点,discovery.zen.minimum_master_nodes分别设置成2和1会怎么样?
如果我们有2个节点,都可以是master候选节点,那么quorum是2 / 2 + 1 = 2。此时就有问题了,因为如果一个node挂掉了,这么这时节点发生变更,那么只剩下一个master候选节点,是无法满足quorum数量的,也就无法选举出新的master,集群就彻底挂掉了。此时就只能将这个参数设置为1,但是这就无法阻止脑裂的发生了
那么思考一下三台行不行呢?
node1为主节点 node2、3是数据节点,3/2+1 = 2,也是至少两台支持才能成为master。
1)如果主节点和两个数据节点因为网络不稳定失去联系,两个数据节点是可以正常通信的,那么此时那个单独的master节点因为没有指定数量的候选master node在自己当前所在的集群内,因此就会取消当前master的角色,尝试重新选举,但是无法选举成功。然后另外一个网络区域内的node因为无法连接到master,就会发起重新选举,因为有两个master候选节点,满足了quorum,因此可以成功选举出一个master。此时集群中就会还是只有一个master,不会出现脑裂。
2)如果master和另外一个node在一个网络区域内,然后一个node单独在一个网络区域内。那么此时那个单独的node因为连接不上master,会尝试发起选举,但是因为master候选节点数量不到quorum,因此无法选举出master。而另外一个网络区域内,原先的那个master还会继续工作。这也可以保证集群内只有一个master节点。
3)如果三台相互之间都无法通信,同上分析,则也不会出现脑裂问题。
综上所述,一个生产环境的es集群,至少要有3个节点,三台主节点通过在elasticsearch.yml中配置discovery.zen.minimum_master_nodes: 2,就可以避免脑裂问题的产生。
2.5 安装head插件
2.5.1 安装head插件方法1:
elasticsearch-head是集群管理、数据可视化、增删改查、查询语句可视化工具。从ES5版本后安装方式和ES2以上的版本有很大的不同,在ES2中可以直接在bin目录下执行plugin install xxxx 来进行安装,但是在ES5以上的版本后这种安装方式变了,要想在ES5以上的版本中安装Elasticsearch Head,必须要安装Nodejs 然后通过NodejS来启动Head.
官网地址:https://github.com/mobz/elasticsearch-head
2.5.1.1 在elasticsearch.yaml配置文件结尾添加如下的配置
# 增加参数,使head插件可以访问es
http.cors.enabled: true ##开启支持跨域
http.c" ##当设置允许跨域,默认为*,表示支持所有域名
2.5.1.2 重启elasticsearch
[root@es ~]# systemctl restart elasticsearch
2.5.1.3 安装npm
[root@es ~]#git clone git://github.com/mobz/elasticsearch-head.git
[root@es ~]#unzip elasticsearch-head-master.zip
[root@es ~]#cd elasticsearch-head-master/
[root@es elasticsearch-head-master]#yum -y install npm
[root@es elasticsearch-head-master]#npm install grunt --save
[root@es elasticsearch-head-master]#ll node_modules/grunt
[root@es elasticsearch-head-master]#npm install
[root@es elasticsearch-head-master]#nohup npm run start&
2.5.1.4 查看端口
[root@es ~]# netstat -antup |grep 9100
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 19160/grunt
2.5.1.5 访问测试
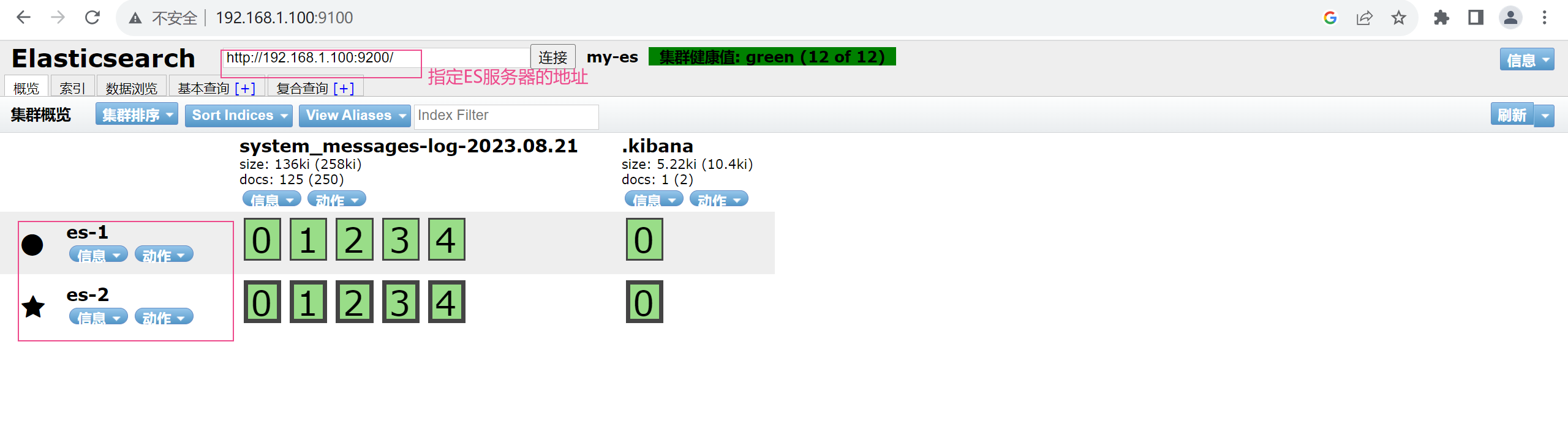
2.5.2 安装head插件方法2:
由于国内使用nodejs的安装目前存在一些问题,可能安装失败,这里我们采用容器的方式来添加这个插件,在docker容器中,使用已经定义好的镜像来操作更加的简单,具体方式如下:
默认服务器是没有安装docker的,我们可以先安装以下docker
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
# Step 4: 更新并安装Docker-CE
sudo yum makecache fast
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo service docker start
2.5.2.1 修改拉取镜像的仓库地址,便于我们快速的拉取镜像
默认的镜像拉去速度太慢,这里我们采用阿里云的镜像加速地址
登录阿里云的容器镜像服务
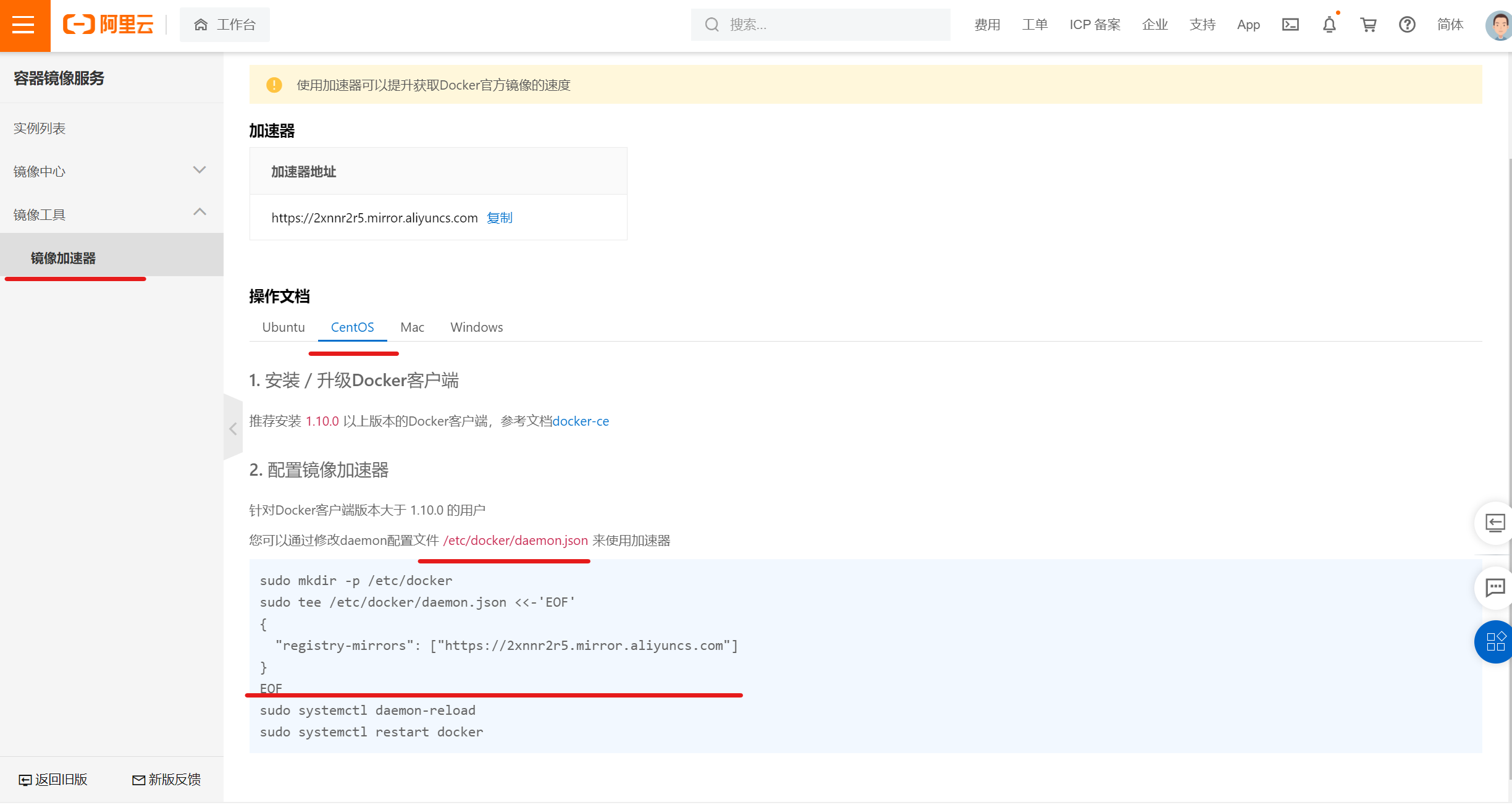
选择CentOS的版本,在/etc/docker/daemon.json文件中添加如下的配置
{
"registry-mirrors": ["https://2xnnr2r5.mirror.aliyuncs.com"]
}
完成后重载配置
systemctl daemon-reload
systemctl restart docker
2.5.2.2 拉取镜像
docker run -d --name=elasticsearch-head --restart=always -p 9100:9100 docker.io/mobz/elasticsearch-head:5-alpine
拉取完成后运行结果如下:

2.5.2.3 我们打开浏览器访问宿主机的9100端口测试是否正常
将“localhost”改成你服务器的IP地址,点击连接就可以看到你的集群的信息
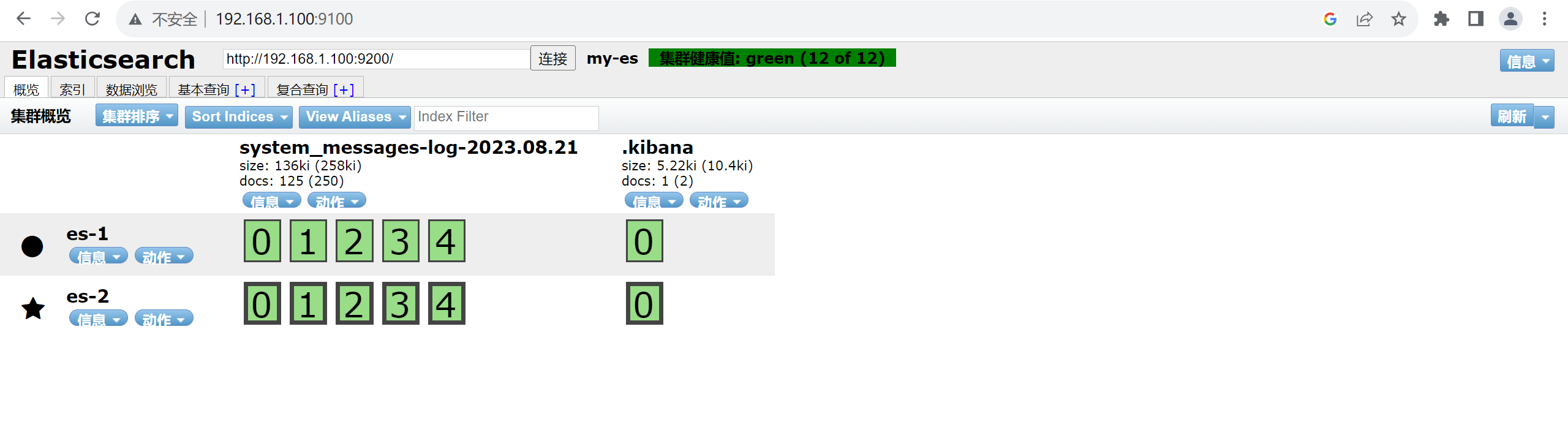
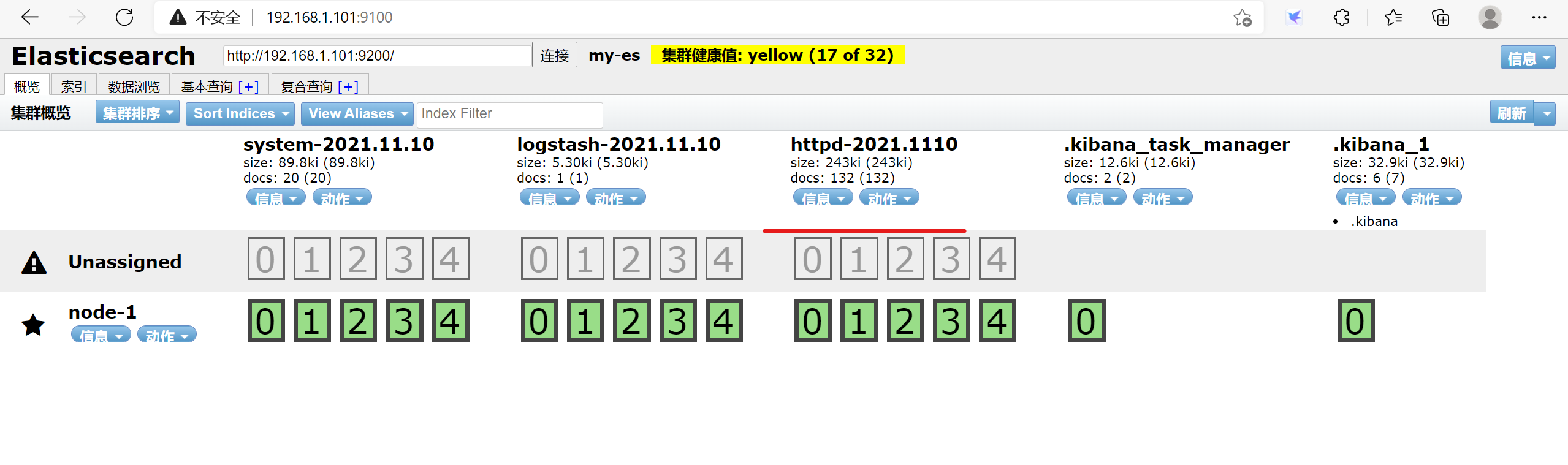
集群状态颜色说明
Green :所有数据都可用,主副分片都已经分配好
Yellow : 所有数据都可用,但尚未分配一些副本,不影响查询,可能影响恢复。如果集群中的某个节点发生故障,则在修复该节点之前,某些数据可能不可用。
Red :某些数据由于某种原因 存在主分片未分配,对查询会有影响
注意 :图形化界面的基本操作
此时的docker由于内部配置问题,还需要进行相应的修改才能正常使用图形化,因此需要按照如下修改:
1.进入head容器 docker exec -it head bash
docker exec -it head sh
2.进入_site目录 cd _site
3.编辑vendor.js文件 vim vendor.js
4.修改内容,一共两处
①. 6886行 contentType: "application/x-www-form-urlencoded
改成
contentType: "application/json;charset=UTF-8"
②. 7574行 var inspectData = s.contentType === "application/x-www-form-urlencoded" &&
改成
var inspectData = s.contentType === "application/json;charset=UTF-8" &&
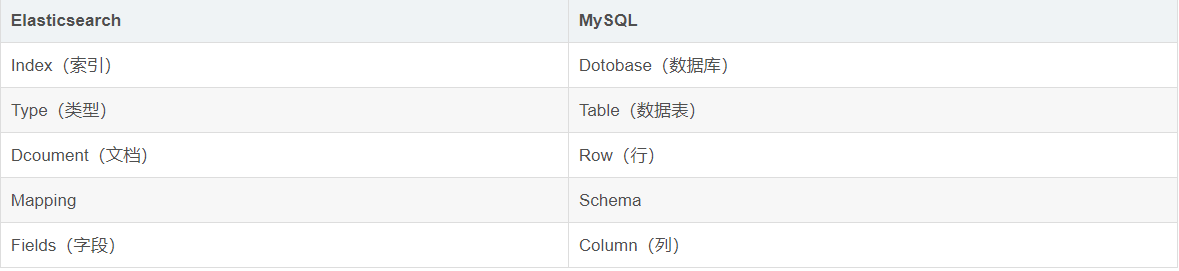
2.6 elasticsearch的一些基本概念
Cluster
集群是一个或多个节点的集合,它们一起保存数据并提供跨所有节点的联合索引和搜索功能。
Node
节点是作为集群的单台服务器,存储数据并参与集群的索引和搜索功能。
Index
索引是具有某些相似特征的文档的集合。
Type
类型是索引的逻辑逻辑分区,一个索引中可以定义一个或多个类型。
Document
文档是可以索引信息的最基本单元。
Shards&Replicas
通过分片的功能,elastic索引可以存储超过单个节点硬件限制的大量数据。当创建索引时,可以简单定义分片的数量。默认是5个分片和1个副本
分片有两个重要的原因:
允许水平分割/缩放内容卷
可以在多个节点上跨分片分布和并行操作,提供吞吐量
副本主要作用:
在节点故障情况下提供高可用性。副本分片从不分配在与从其复制的原始/主分片相同的节点上
搜索可以并行地在所有副本上执行,因此扩展了搜索量/吞吐量
为了便于理解,我们看一下mysql和es的概念对比
2.7 es的基础操作
官方API接口文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/cluster.html。
2.7.1 基本操作格式:
curl -x<VERB> ‘<PROTOCOL>://HOST:PORT/<PATH>?<QUERY_STRING> -d '<BODY>'
----
VERB :GET,PUT,DELETE等;
PROTOCOL :http,https
QUERY_STRING :查询参数,例如?pretty表示用易读的JSON格式输出。
BODY :请求的主题
2.7.2 基本例子
1、查看集群的监控状态
curl -XGET http://10.0.0.12:9200/_cluster/health?pretty
2、查看集群的版本号
curl -XGET 'http://10.0.0.12:9200/_cluster/state/version?pretty'
3、查看ES的_cluster接口的state状态
curl -XGET 'http://10.0.0.12:9200/_cluster/state/nodes?pretty'
4、查看ES集群节点信息
curl -XGET http://10.0.0.12:9200/_cat/nodes?v
5、查看ES索引
curl -XGET 'http://10.0.0.12:9200/_cat/indices'
6、创建索引,并为该文档分配 ID 为1。URL 路径显示为index/doctype/ID(索引/文档类型/ID)
curl -XPUT http://10.0.0.12:9200/hubei/city/1?pretty -d '{"id": "1", "title": "are you ok?"}'
{
"error" : "Content-Type header [application/x-www-form-urlencoded] is not supported",
"status" : 406
}
报错:Content-Type header [application/x-www-form-urlencoded] is not supported
原因: 此原因时由于ES增加了安全机制, 进行严格的内容类型检查,严格检查内容类型也可以作为防止跨站点请求伪造攻击的一层保护。
解决方案:
curl -XPUT http://10.0.0.12:9200/hubei/city/1?pretty -H 'Content-Type: application/json' -d '{"id": "1", "city": "beijing"}'
7、根据索引ID查看
curl -X GET "http://10.0.0.12:9200/hubei/city/1?pretty"
8、根据字段查询文档
curl -XGET "http://10.0.0.12:9200/hubei/city/_search?q=city:'beijing'&pretty" -H "Content-Type: application/json"
9、 更新索引内容
curl -XPOST http://10.0.0.12:9200/hubei/city/1?pretty -d '{"id": "1", "city": " wuhan"}' -H "Content-Type: application/json"
10、删除索引
curl -XDELETE http://10.0.0.12:9200/c_index
11、创建索引并添加数据
curl -X POST 'http://10.0.0.12:9200/c_index/_doc?pretty' -H 'Content-Type: application/json' -d '
{
"@timestamp": "2022-09-19T08:14:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "c_index"
}
}'
12、查看某个时间段的索引数据
curl -X GET 'http://192.168.10.100:9200/c_index/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"range" : {
"@timestamp": {
"from": "2021-11-19T08:00:00",
"to": "2030-11-19T09:00:00"
}
}
}
}'
13、查看c_index索引下的所有数据
curl -X GET 'http://10.0.0.12:9200/c_index/_search?pretty=true' -H 'Content-Type: application/json' -d '
{
"query" : {
"match_all" : {}
}
}'
返回值说明:
1、Hits
返回结果中最重要的部分是 hits ,它包含 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果的前十个文档。
在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,仅仅返回文档的ID,需要你单独去获取文档。
每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。在这个例子中,我们没有指定任何查询,故所有的文档具有相同的相关性,因此对所有的结果而言 1 是中性的 _score 。
max_score 值是与查询所匹配文档的 _score 的最大值。
2、took
took 值告诉我们执行整个搜索请求耗费了多少毫秒
3、 Shark
创建时,影响的是两个分片, 这两个分片是指的2个副本
查询时,影响五个分片(默认)
_shards 部分 告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。
如果我们遭遇到一种灾难级别的故障,在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。
4、 timeout
timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。 如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
2.7.3 导入官方测试数据(了解)
https://www.elastic.co/guide/en/kibana/6.2/tutorial-load-dataset.html
https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
[root@elasticsearch ~]# curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
通过head查看导入的数据
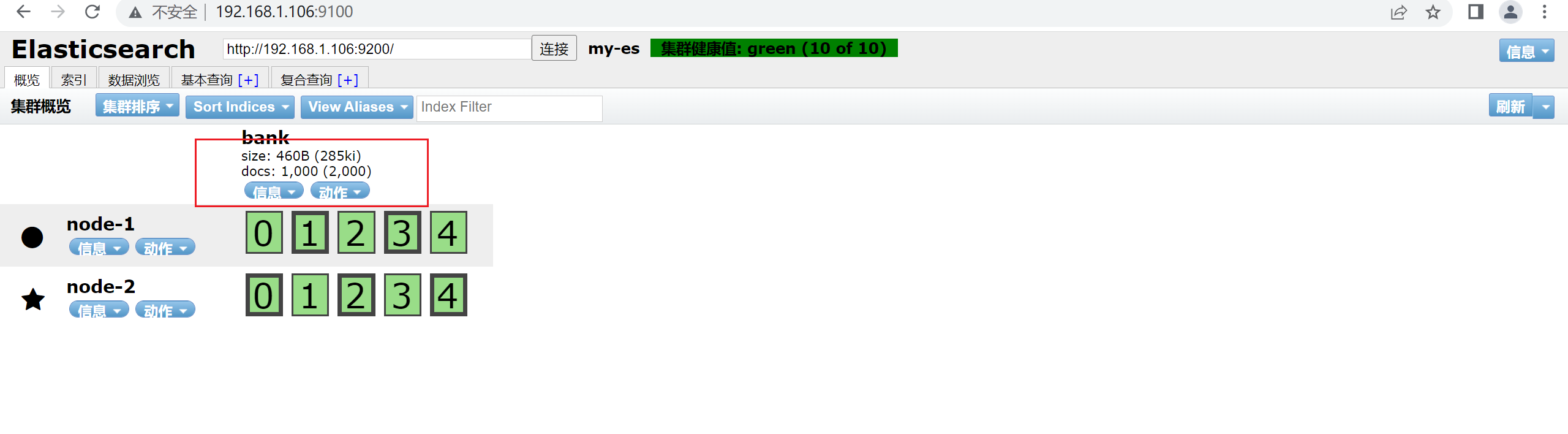
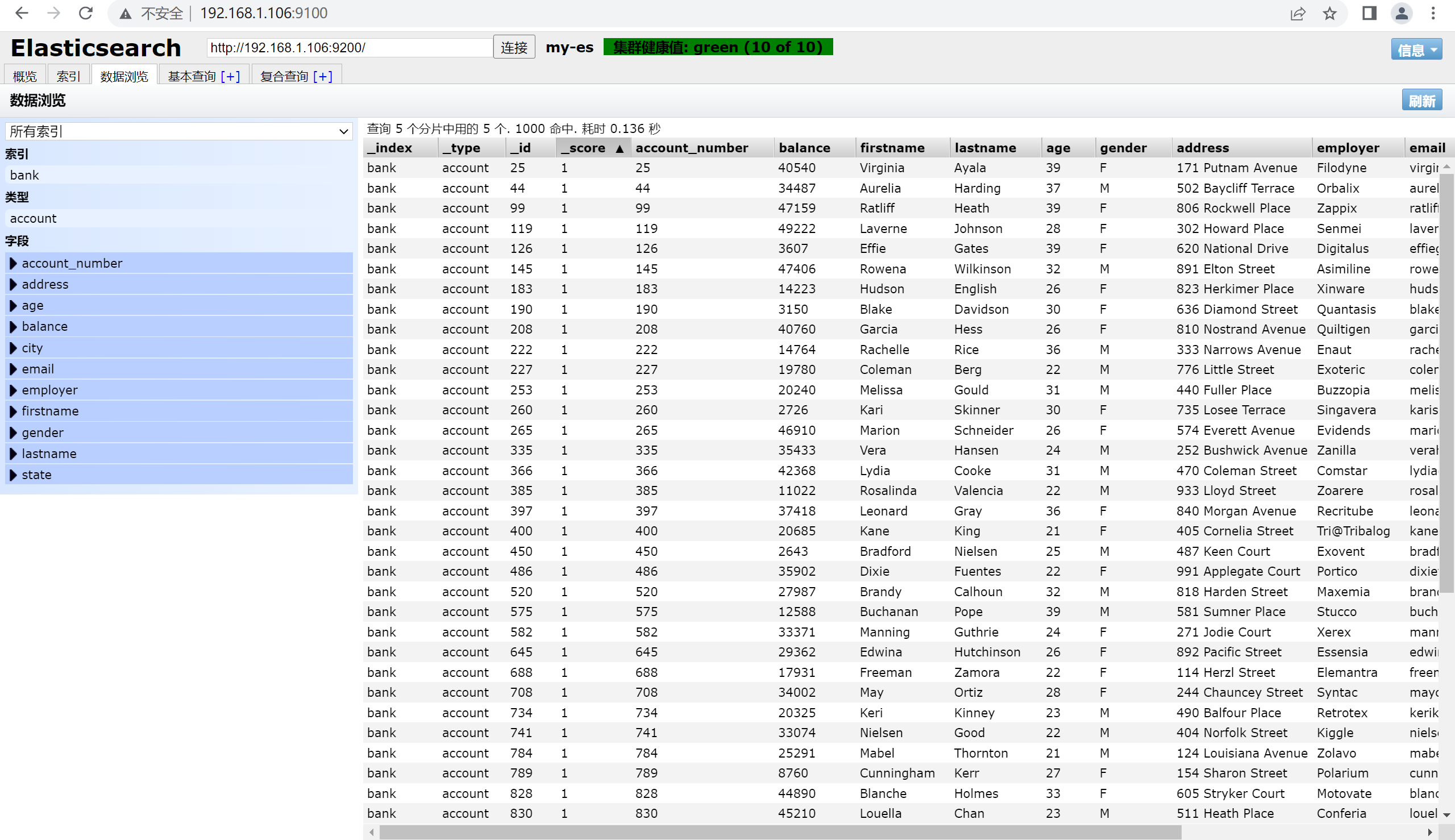
手动插入数据
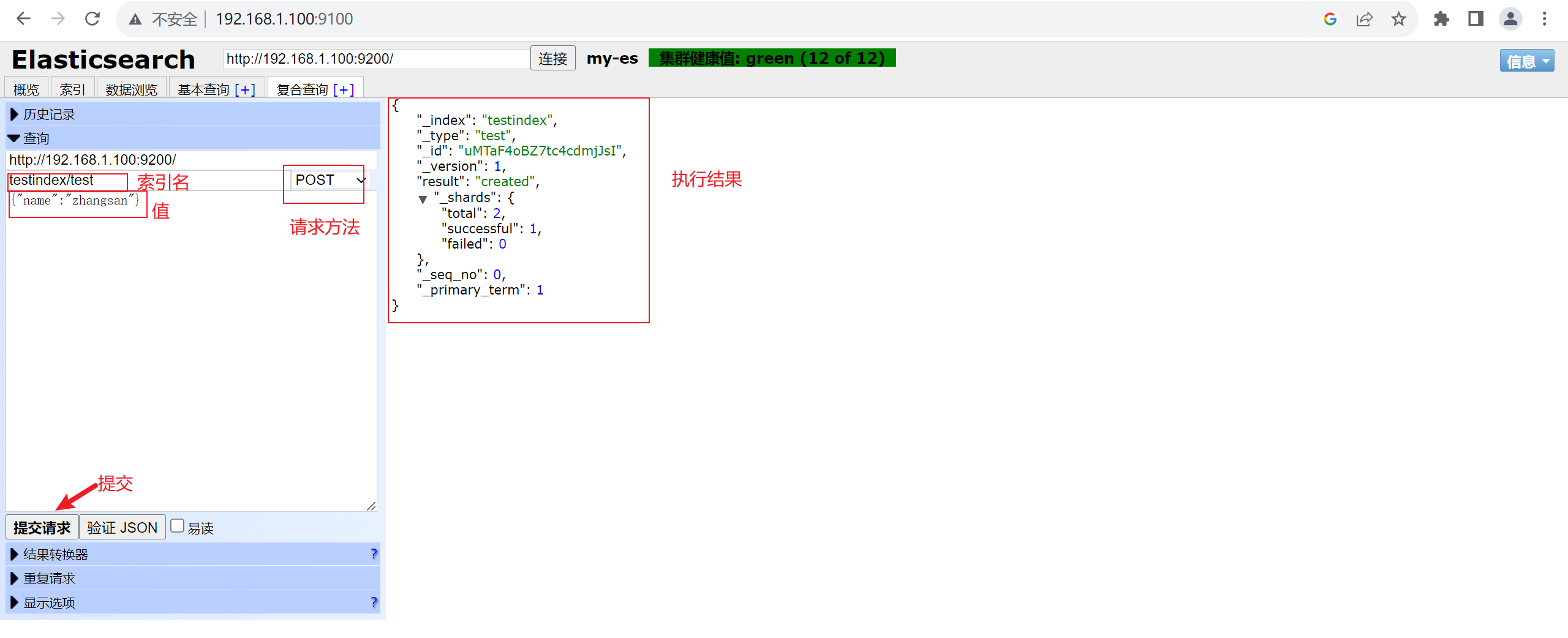
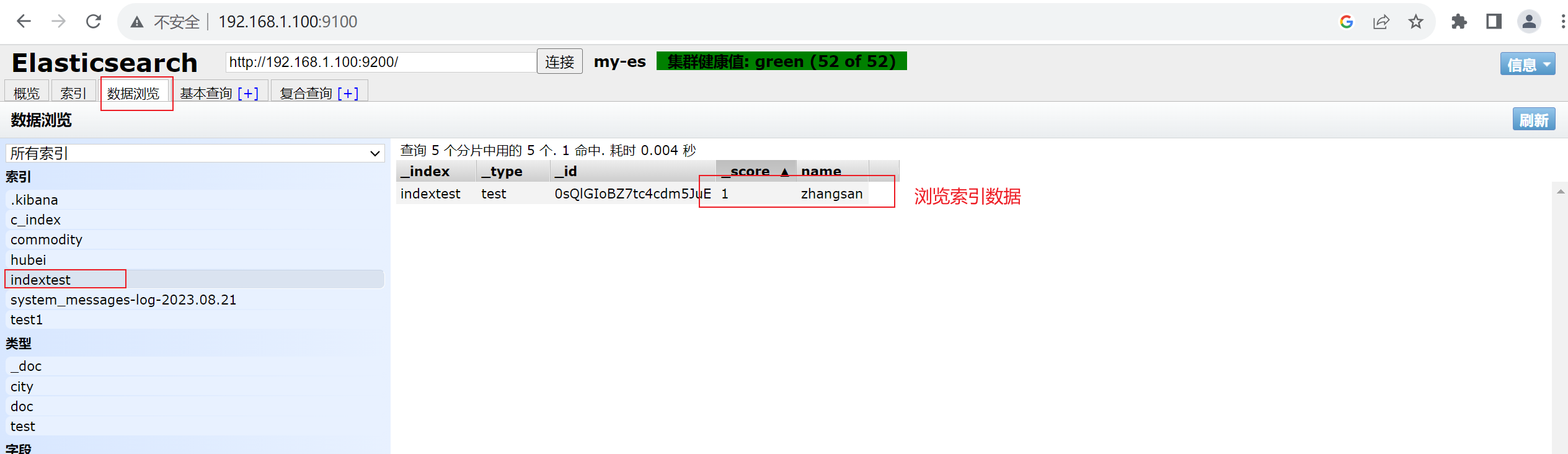
2.8 安装logstash
集中、转换和存储你的数据,是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的存储:
logstash的流程架构:
input | filter | output 如需对数据进行额外处理,filter可省略。
-------
##常用插件
input:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
插件文档:https://www.elastic.co/guide/en/logstash/6.8/input-plugins.html
filter:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
插件文档:https://www.elastic.co/guide/en/logstash/6.8/filter-plugins.html
output:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
插件文档:https://www.elastic.co/guide/en/logstash/6.8/output-plugins.html
2.8.1 安装jdk
[root@logstash opt]# rpm -ivh jdk-8u381-linux-x64.rpm
[root@logstash bin]# java -version
java version "1.8.0_381"
Java(TM) SE Runtime Environment (build 1.8.0_381-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.381-b09, mixed mode)
2.8.2 导入logstash公钥
[root@logstash opt]#sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.8.3创建logstash yum仓库
[root@logstash opt]#cat /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
2.8.4 安装
[root@logstash opt]#sudo yum install logstash -y
2.8.5 配置logstash
[root@logstash bin]# grep -v '^#' /etc/logstash/logstash.yml
node.name: logstash
path.data: /var/lib/logstash
http.host: "192.168.1.101"
http.port: 9600-9700
log.level: info
path.logs: /var/log/logstash
2.8.6 启动测试
[root@logstash bin]# ./logstash -e 'input { stdin {} } output { stdout {} }' ##测试输入和输出
Sending Logstash logs to /usr/local/src/logstash-6.8.20/logs which is now configured via log4j2.properties
[2021-11-09T20:48:38,467][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/usr/local/src/logstash-6.8.20/data/queue"}
[2021-11-09T20:48:38,490][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/local/src/logstash-6.8.20/data/dead_letter_queue"}
[2021-11-09T20:48:38,971][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-11-09T20:48:38,983][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.8.20"}
[2021-11-09T20:48:39,019][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"f592e09f-a40a-4a1a-abe0-6be057d32fd5", :path=>"/usr/local/src/logstash-6.8.20/data/uuid"}
[2021-11-09T20:48:46,084][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2021-11-09T20:48:46,198][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x14b37803 run>"}
The stdin plugin is now waiting for input:
[2021-11-09T20:48:46,270][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2021-11-09T20:48:46,584][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
hello ##输入hello
/usr/local/src/logstash-6.8.20/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"@version" => "1",
"@timestamp" => 2021-11-09T12:49:03.694Z,
"host" => "localhost.localdomain",
"message" => "hello" ##打印hello
}
best ##输入best
{
"@version" => "1",
"@timestamp" => 2021-11-09T12:52:00.190Z,
"host" => "localhost.localdomain",
"message" => "best" 输出best
}
注:
-e :执行操作
input:标准输入
{stdin} :插件
output:标准输出
{stdout}:插件
2.12.3 如果标准输出还有elasticsearch中都需要保留,可以测试如下的语法
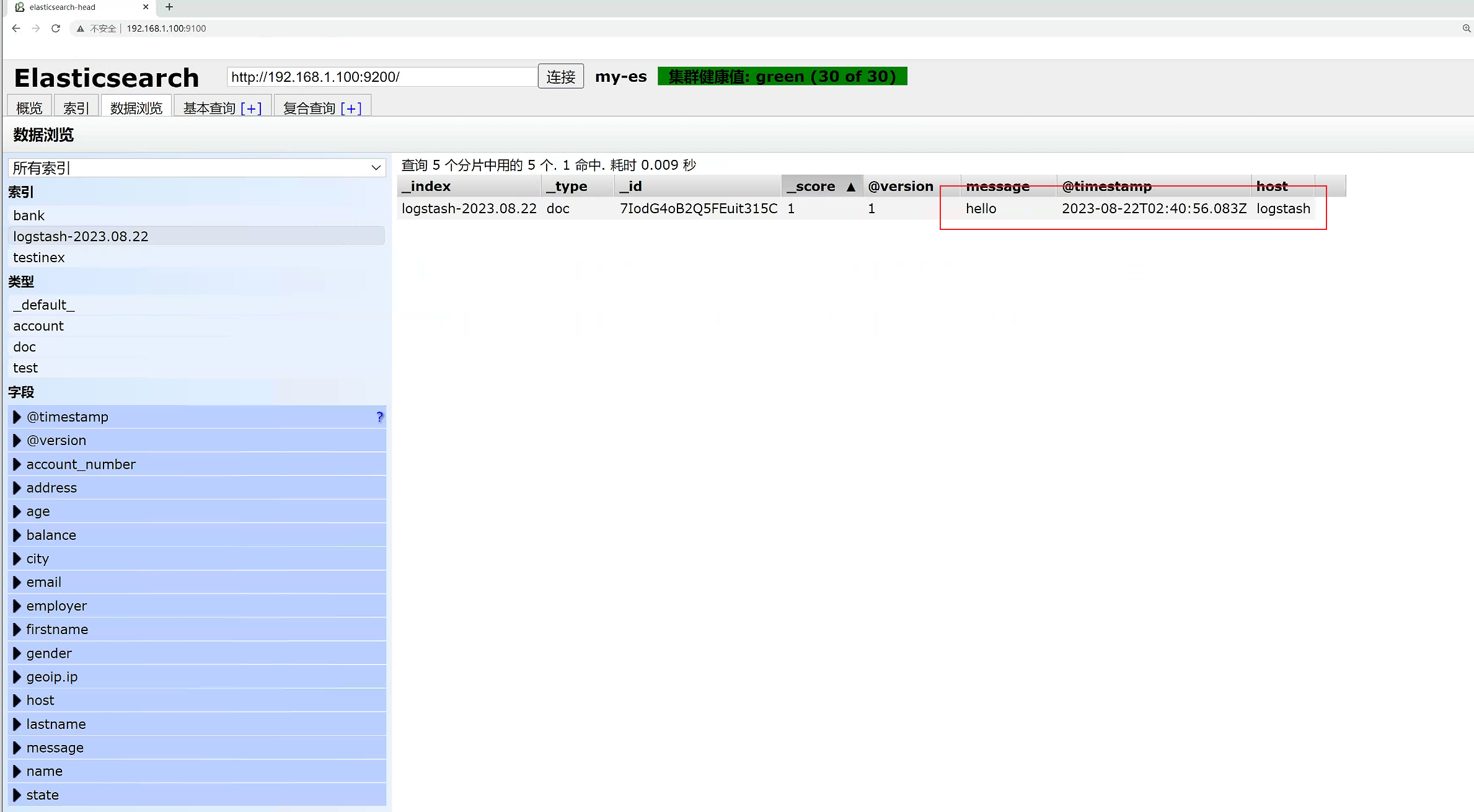
[root@logstash bin]# ./logstash -e 'input { stdin { } } output { elasticsearch { hosts => ["192.168.1.100:9200"] } stdout { codec => rubydebug }}'

2.8.4 如果标准输出还要保存在文件中,可以测试如下的语法
[root@logstash bin]# ./logstash -e 'input { stdin {} } output { file {path => "/tmp/test.txt" } stdout { codec => rubydebug} }'

[root@logstash ~]# cat /tmp/test.txt
{"message":"hello","@timestamp":"2023-08-22T02:38:11.542Z","@version":"1","host":"logstash"}
{"message":"world","@timestamp":"2023-08-22T02:38:35.906Z","@version":"1","host":"logstash"}
[root@logstash ~]#
2.9 日志收集
2.9.1 我们尝试来收集web01 的/var/log/messages的信息
在logstash的目录先新建一个配置目录:conf.d,加入如下的配置
[root@web01 logstash]# mkdir conf.d
[root@web01 conf.d]# cat elk.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.1.100:9200"] ##ES服务器的地址
index => "message-%{+YYYY.MM.dd}" ##索引的名字
}
}
2.9.2 重新运行logstash
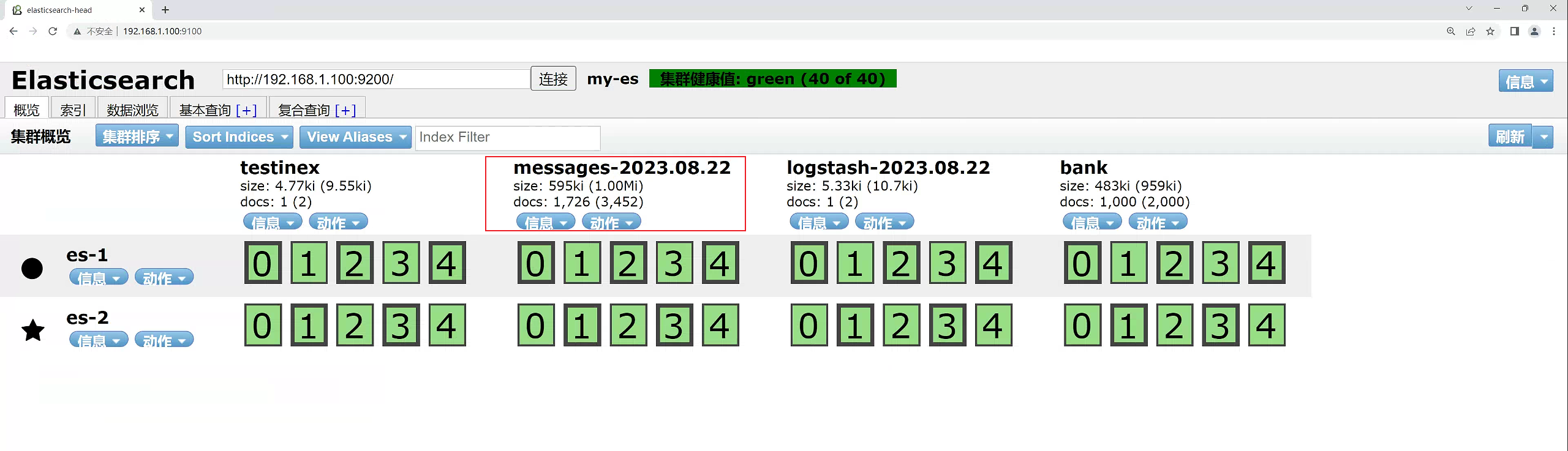
[root@web01 conf.d]# ./logstash -f /usr/local/src/logstash/conf.d/elk.conf
2.9.3 查看ES
2.9.4 日志数据模拟插入
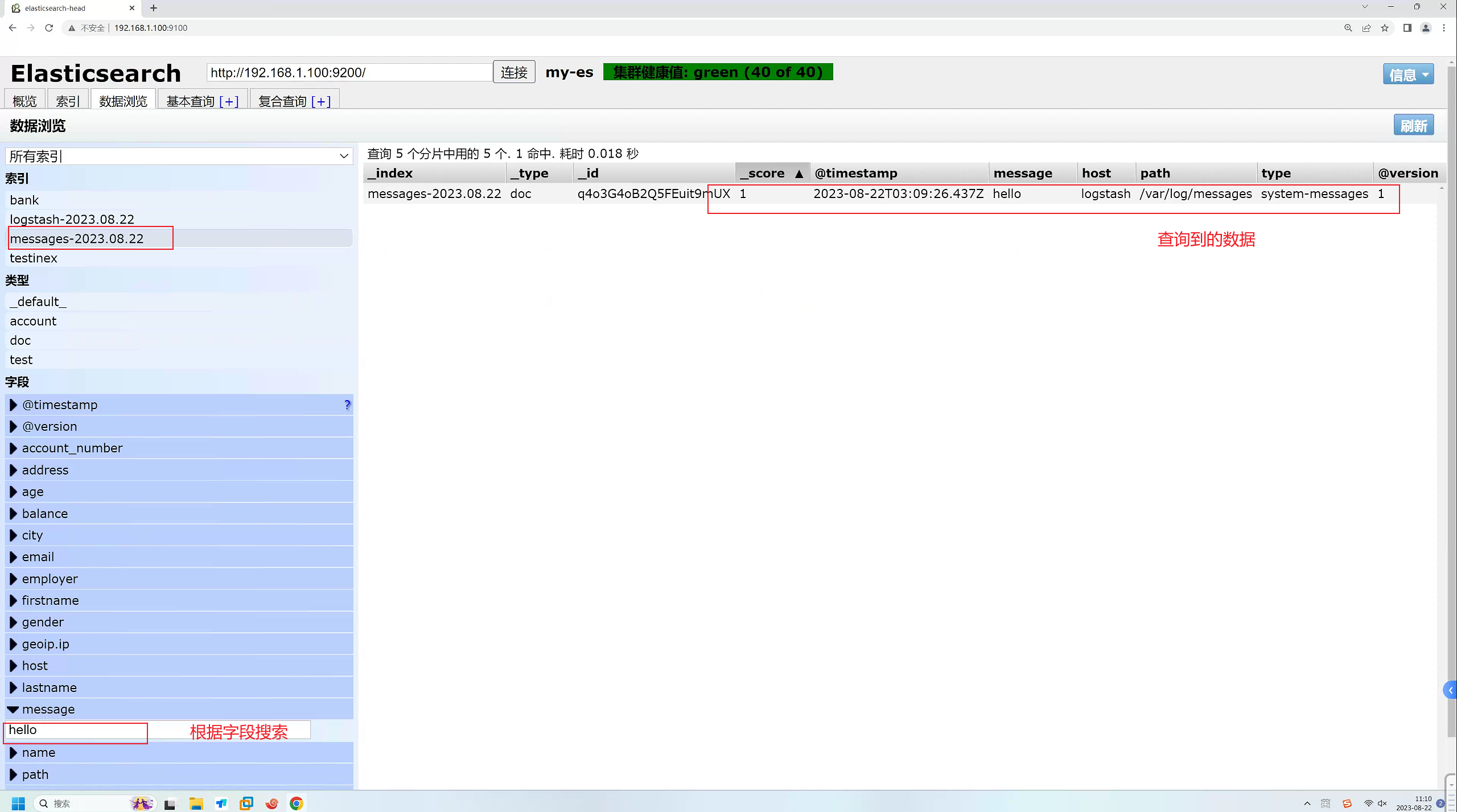
logstash会自动收集当前目标服务器的日志,我们模拟一下往/var/log/messages产生新的日志,查看日志的数据是否能传输到ES中
[root@logstash conf.d]# echo "hello" >> /var/log/messages
[root@logstash conf.d]# echo "world" >> /var/log/messages
2.9.5 练习:
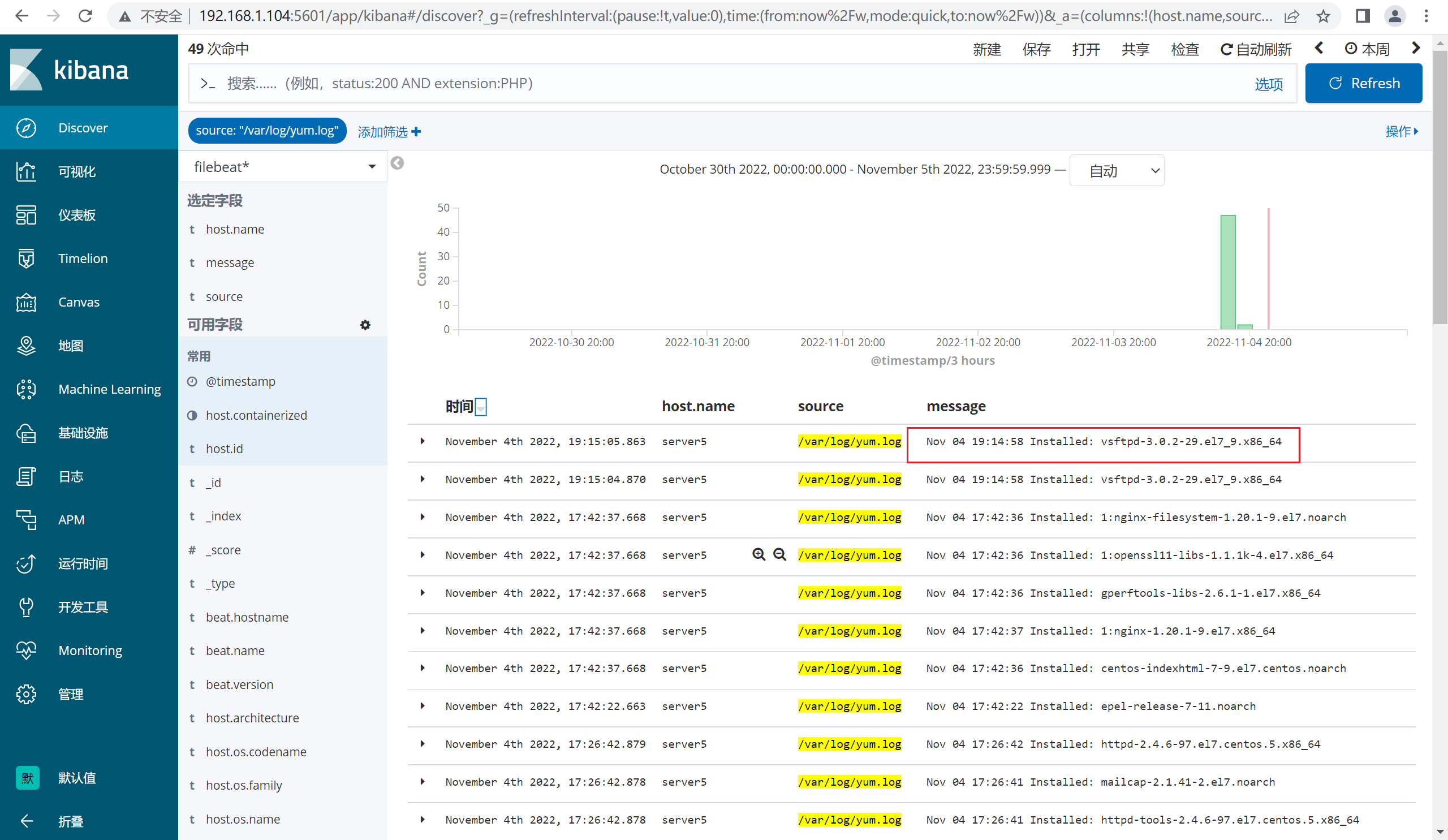
尝试收集目标服务器的yum.log的日志,并模拟尝试安装vsftpd软件和卸载软件,查看是否ES能收集到日志。
2.10 安装kibana
2.10.1 导入kibana公钥
[root@kibana yum.repos.d]#rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
2.10.2 创建仓库
[root@kibana yum.repos.d]# cat /etc/yum.repos.d/kibana.repo
[kibana-6.x]
name=Kibana repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
2.10.3 安装kibana
[root@kibana ~]# yum -y install kibana
2.10.4 修改配置kibana.yml文件
[root@kibana ~]# grep -v "^#" /etc/kibana/kibana.yml
server.port: 5601
server.host: "192.168.1.102"
server.name: "kibana"
elasticsearch.hosts: ["http://10.0.0.12:9200"]
elasticsearch.pingTimeout: 1500
elasticsearch.requestTimeout: 30000
i18n.locale: "zh-CN"
2.10.5 启动kibana
[root@kibana ~]# systemctl enable --now kibana
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
[root@kibana ~]# netstat -antup
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1421/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1510/master
tcp 0 0 192.168.1.102:5601 0.0.0.0:* LISTEN 27284/node
tcp 0 36 192.168.1.102:22 192.168.1.1:52914 ESTABLISHED 19275/sshd: root@pt
tcp6 0 0 :::9100 :::* LISTEN 1997/node_exporter
tcp6 0 0 :::22 :::* LISTEN 1421/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1510/master
2.10.6 访问kibana
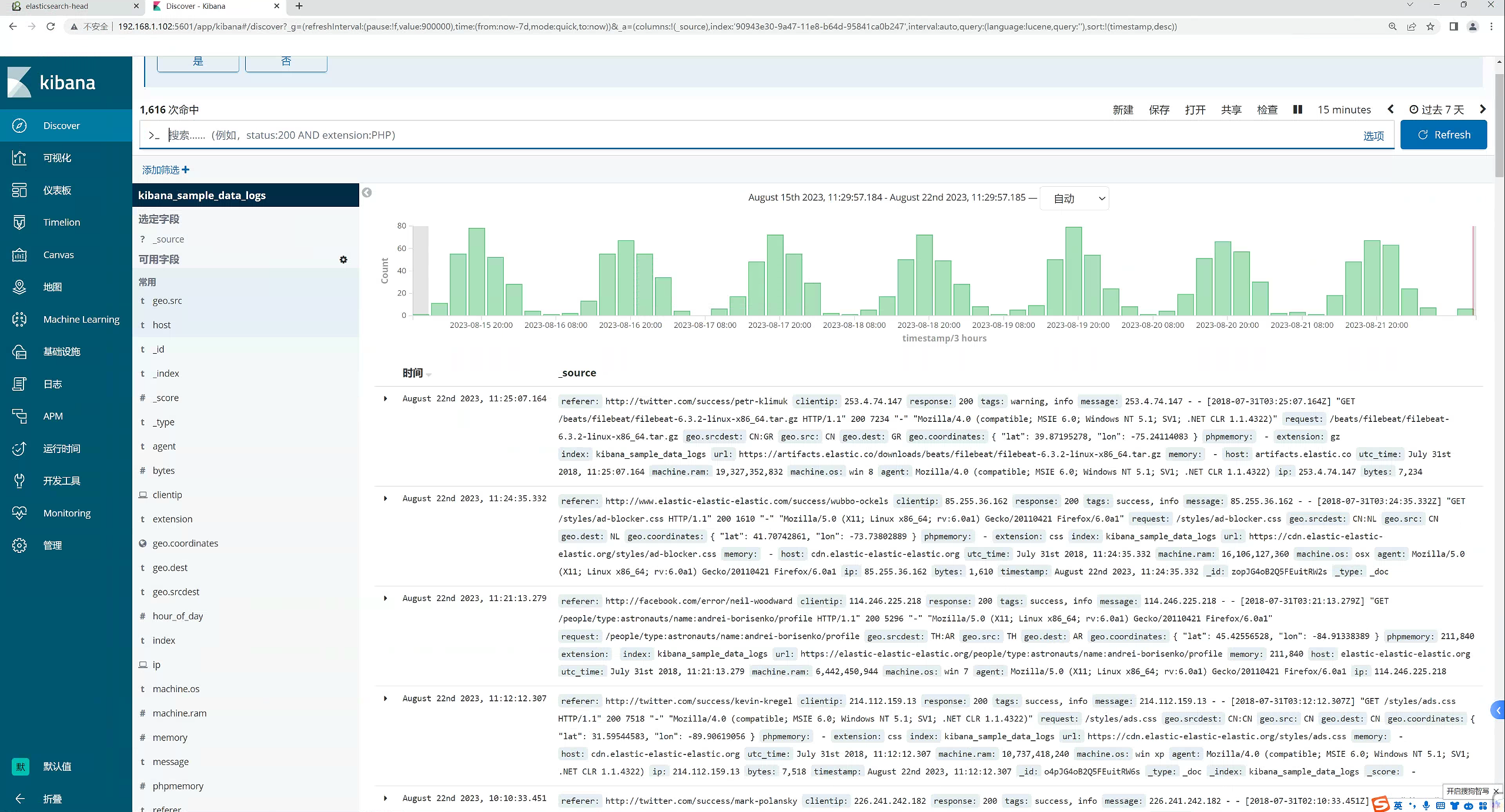
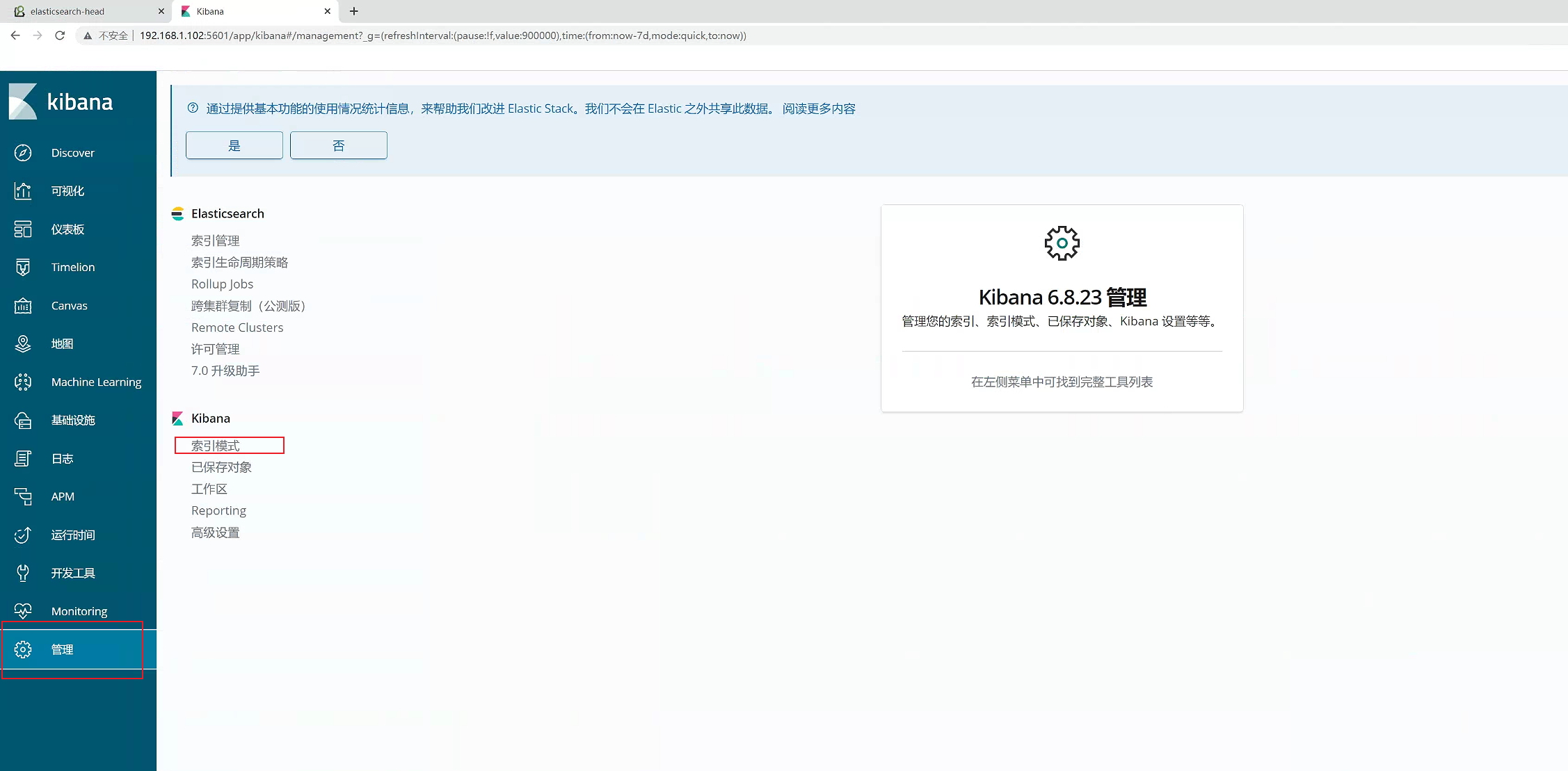
2.10.7 创建索引
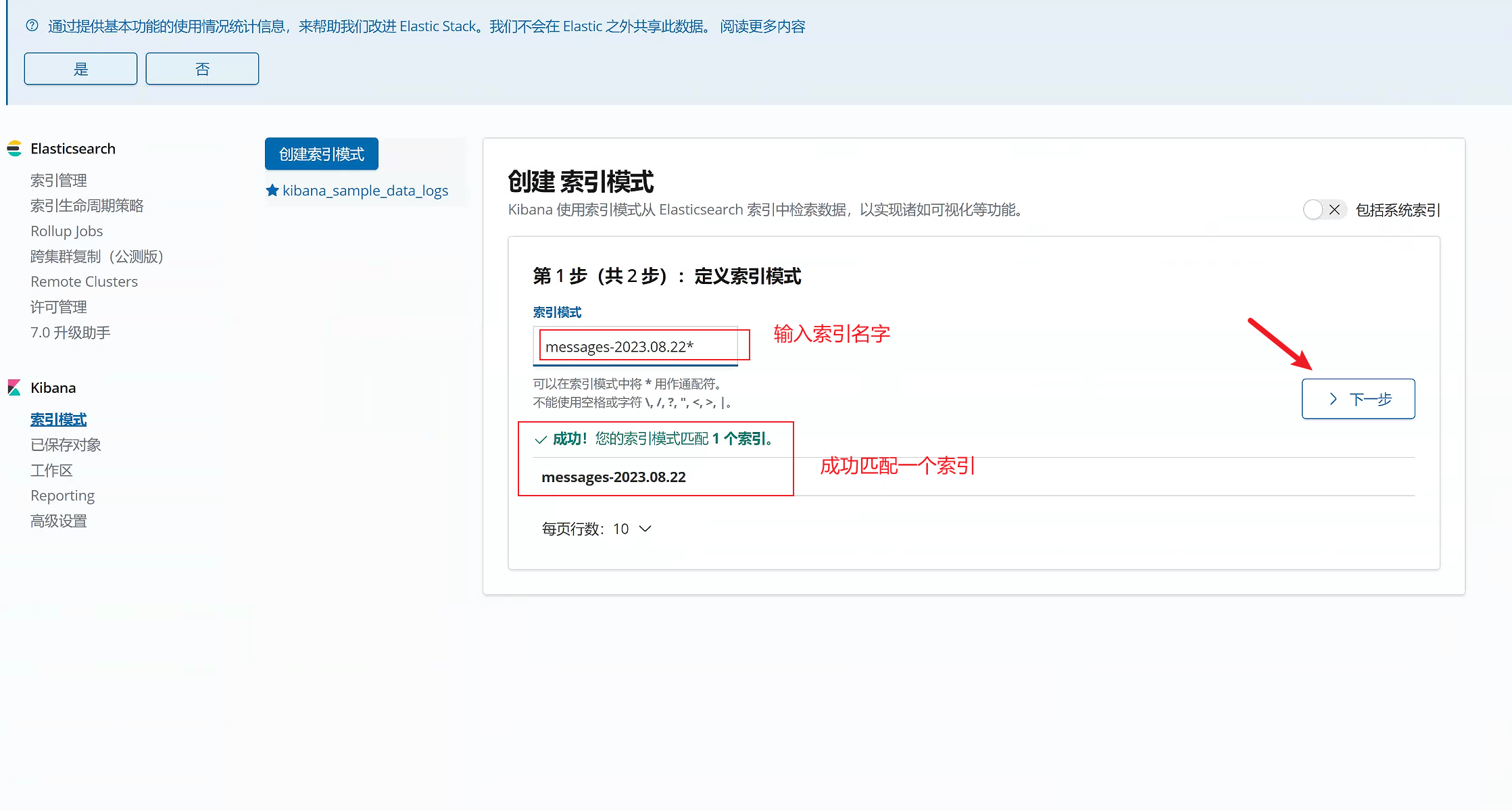
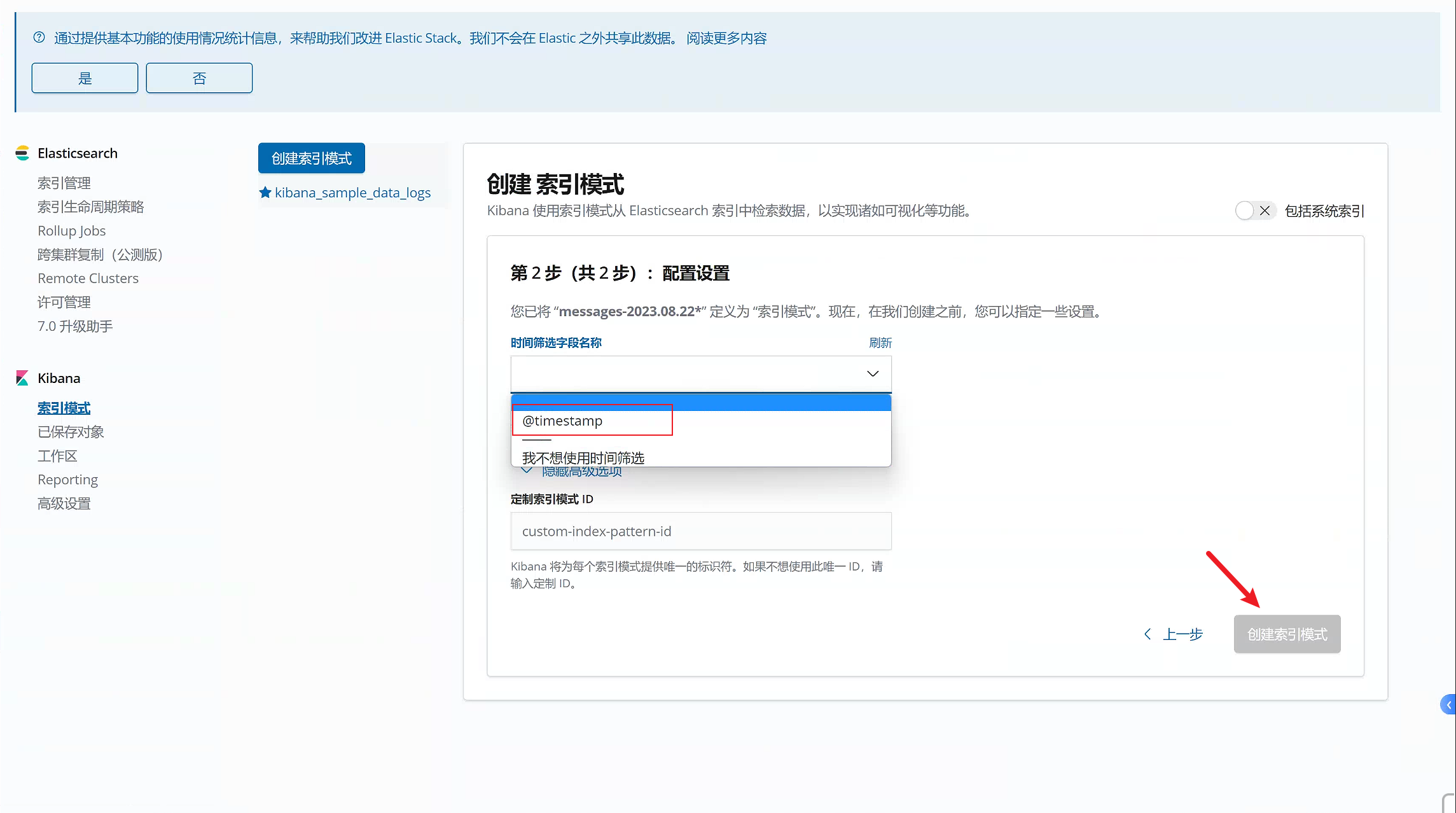
点击“管理”,那我们就开始创建索引
2.10.8 创建完成,查看视图
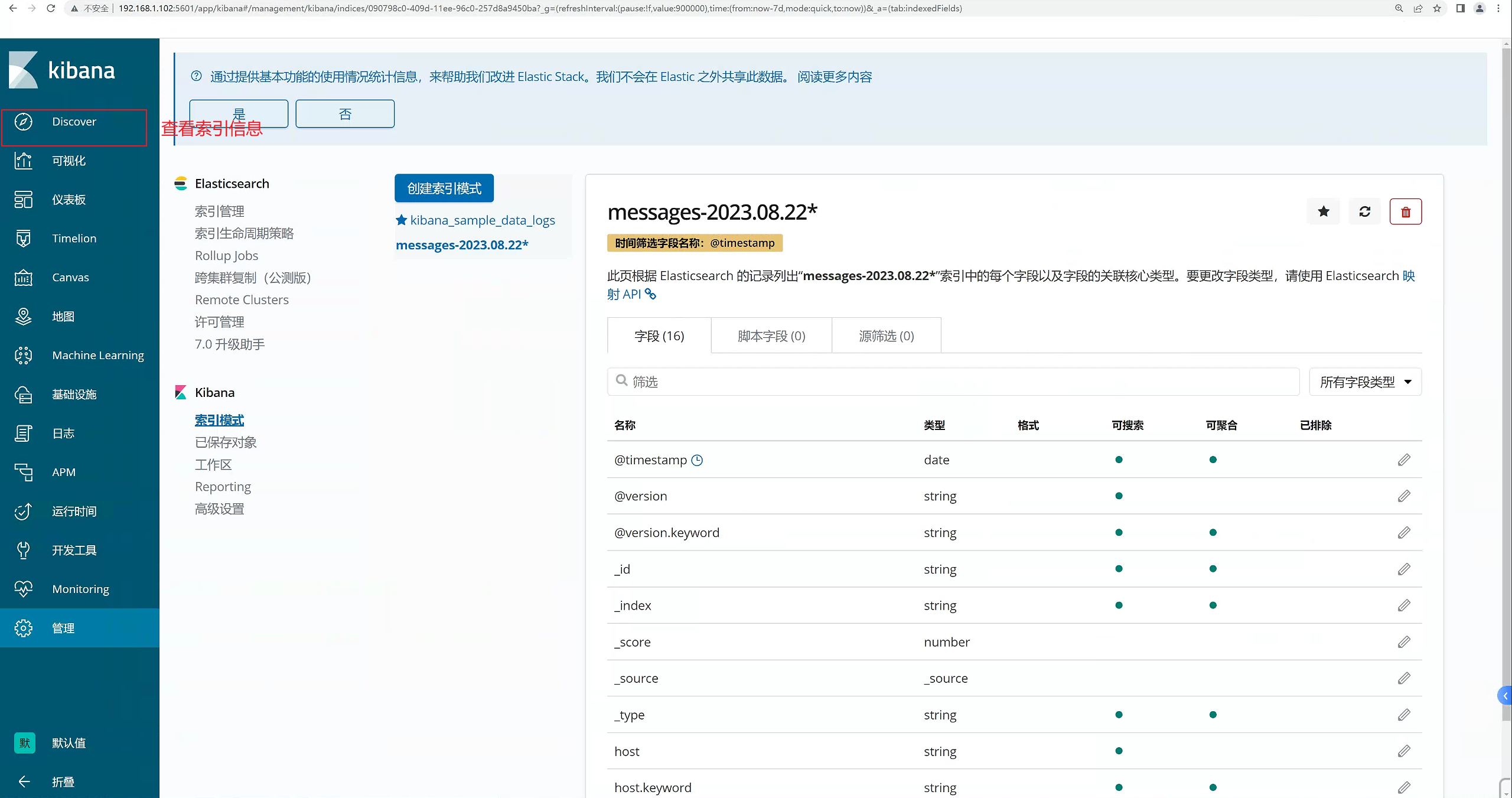
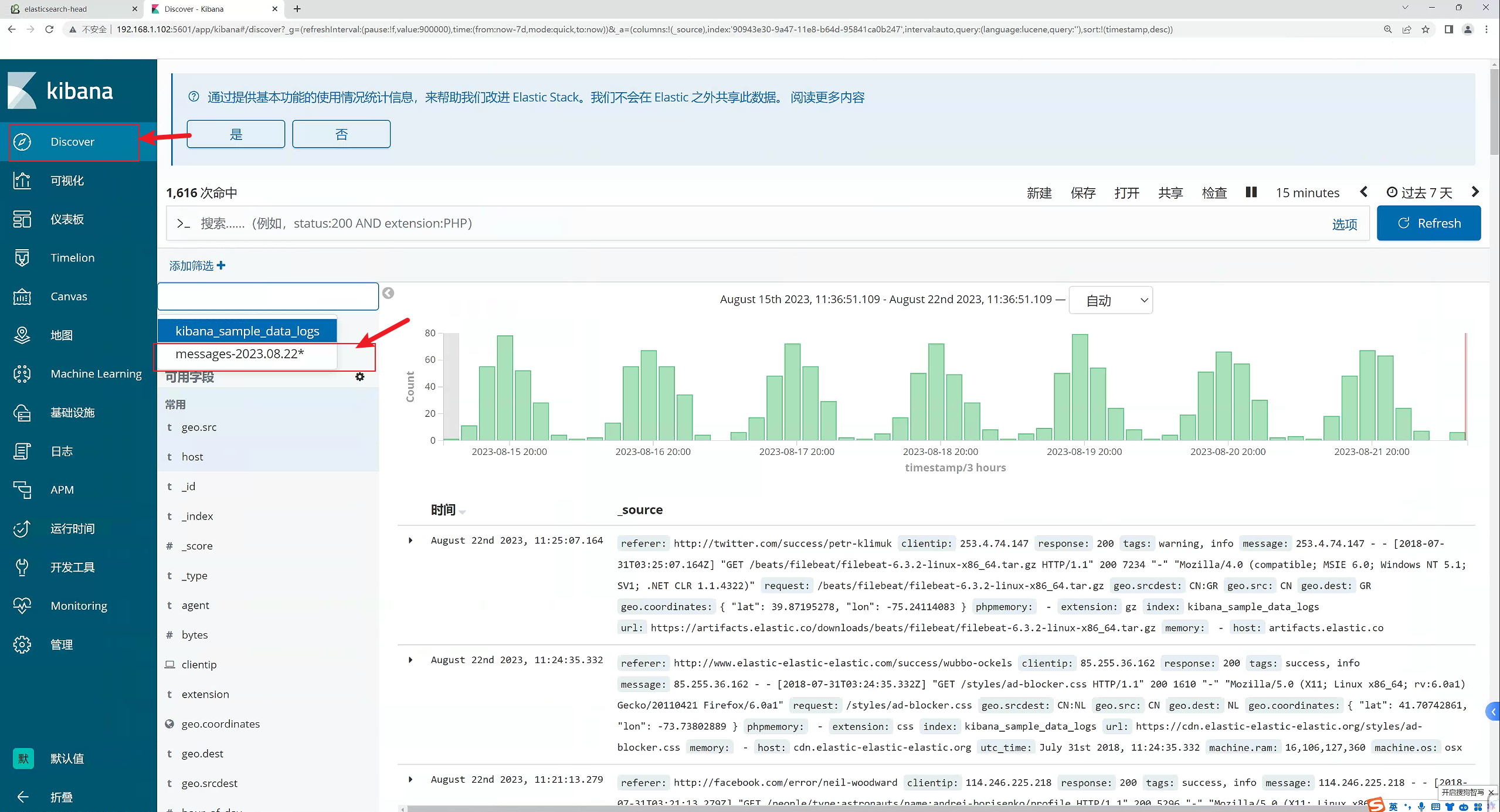
可以看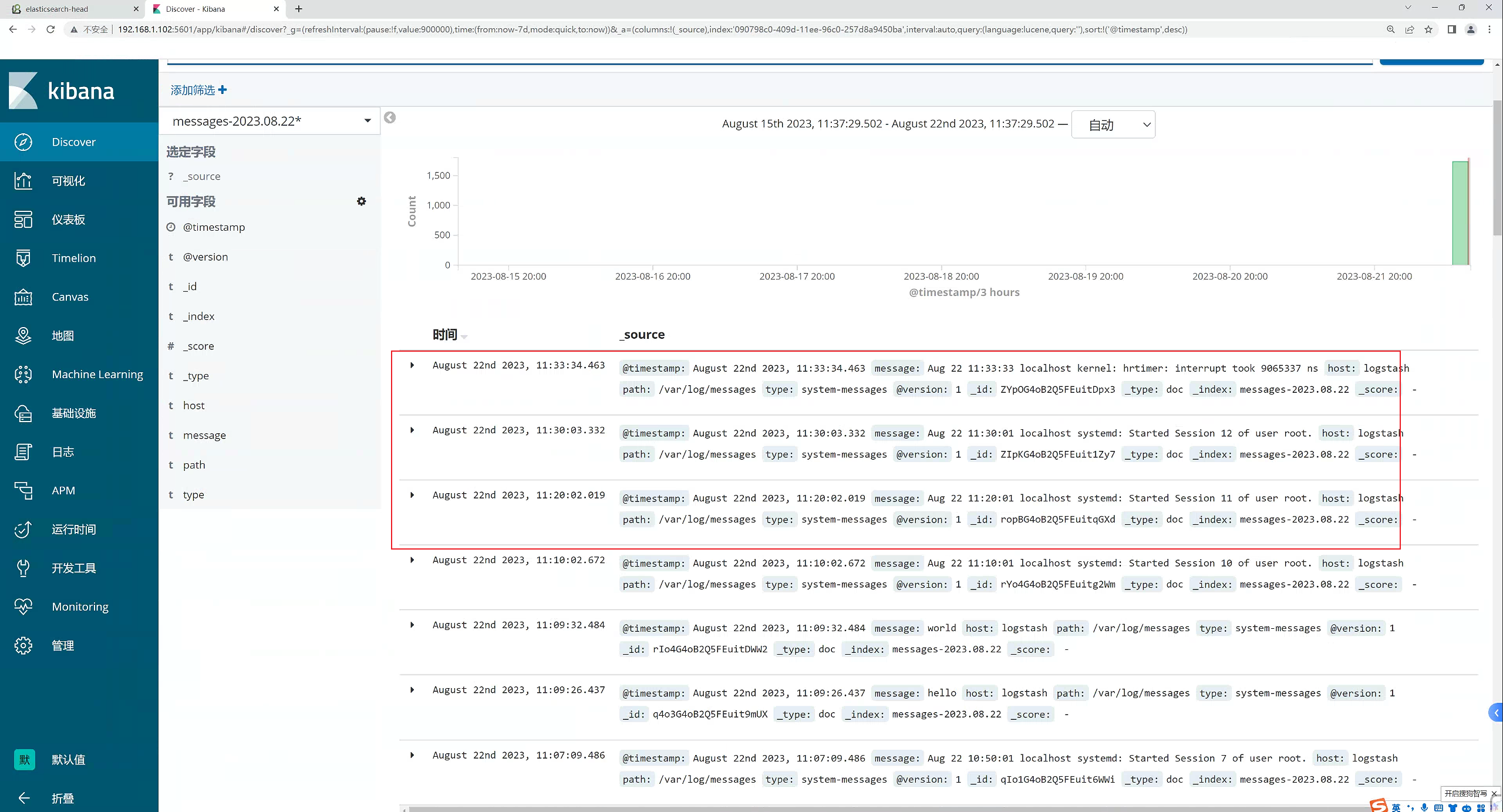
到产生了非常多的系统日志信息
2.11 kinaba的使用
2.11.1 过滤时间
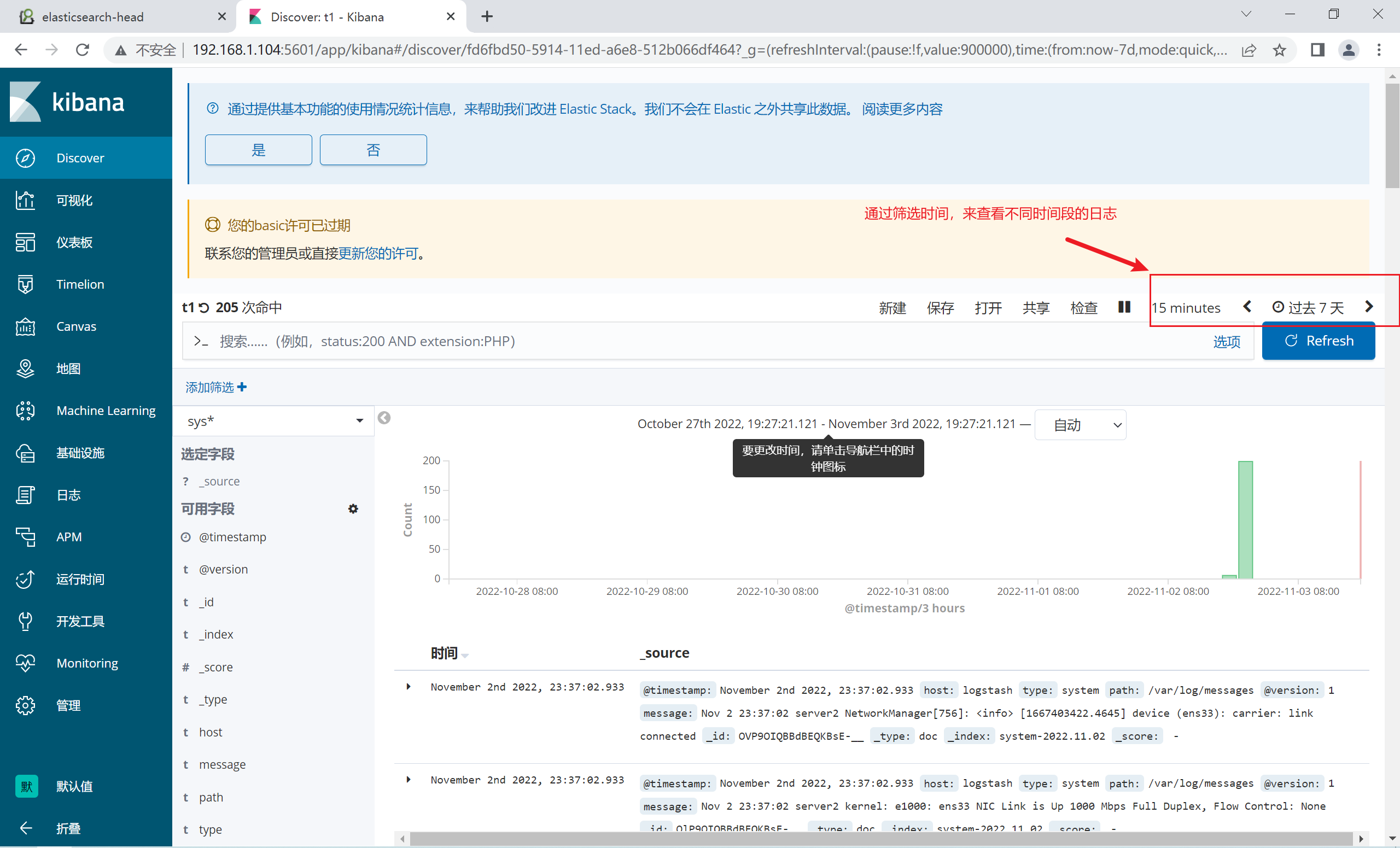
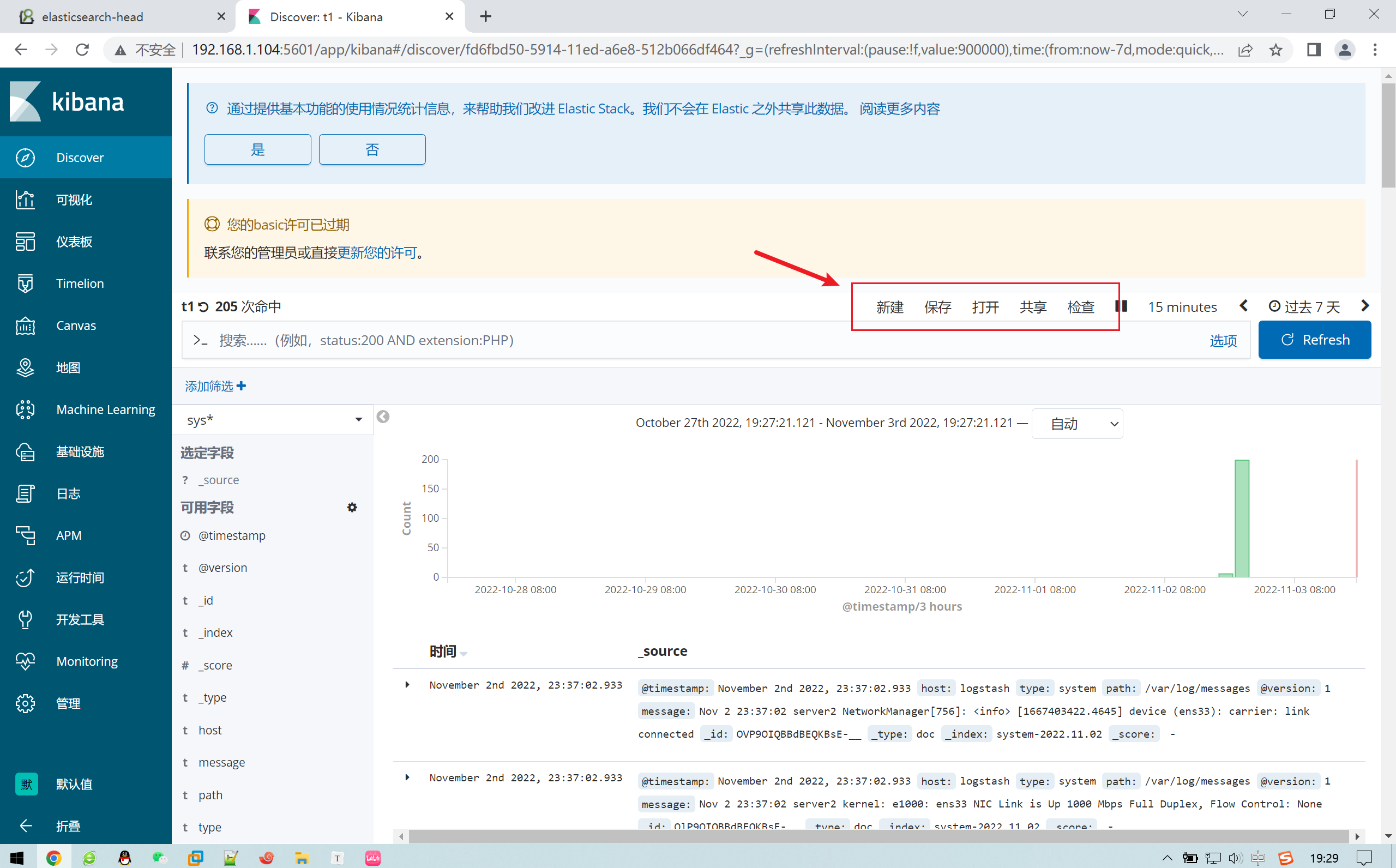
2.12.2 搜索
搜索是Kibana的核心功能之一,它可以帮助您快速地查找到所需的数据。在Kibana中,搜索功能主要通过搜索栏和查询语句来实现
「字段:值」,如果值是字符串,可以用双引号括起来
查询包含http的请求
*http*
查询页面不存在的请求
status : 404
查询请求成功和不存在的请求
status: (404 or 200)
查询方式为POST请求,并请求成功的日志
status: 200 and method: post
查询方式为GET成功的请求,并且响应数据大于512的日志
status: 200 and method: get and length > 512
查询请求成功的且URL为「/itcast.cn」开头的日志
uri: "\/itcast.cn\/*"
注意:因为/为特殊字符,需要使用反斜杠进行转义
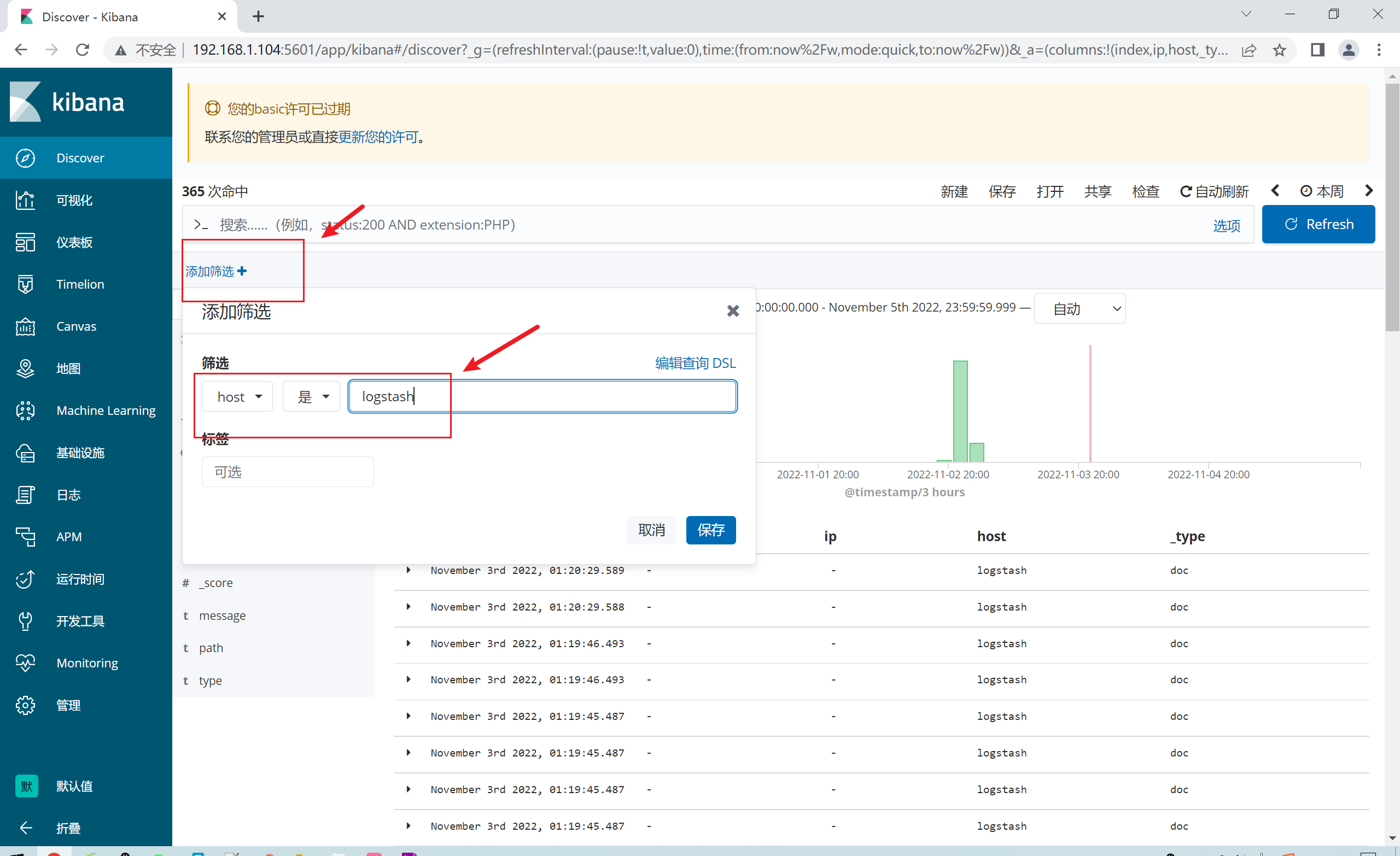
添加筛选器:可以根据条件来筛选需要的数据类型
Kibana的过滤功能可以帮助您筛选出满足指定条件的数据。过滤器可以通过过滤器面板或搜索栏来添加,它们可以基于字段值、范围、存在与否、脚本等多种条件来筛选数据。
(1)基本过滤器:基本过滤器可以帮助您快速筛选出字段的特定值,比如筛选出特定时间范围内的日志数据。在过滤器面板中,您可以选择要过滤的字段,并指定匹配条件和值,然后点击应用过滤器按钮即可。
(2)范围过滤器:范围过滤器可以帮助您筛选出数字或日期范围内的数据。在过滤器面板中,您可以选择要过滤的字段,并指定范围的最小值和最大值,然后点击应用过滤器按钮即可。
(3)布尔过滤器:布尔过滤器可以帮助您组合多个过滤器,比如同时筛选出时间范围内的某个特定IP地址的日志数据。在过滤器面板中,您可以使用逻辑运算符(AND、OR、NOT)来组合多个过滤器,并指定各个过滤器的条件和值。
(4)存在过滤器:存在过滤器可以帮助您筛选出某个字段存在或不存在的数据。在过滤器面板中,您可以选择要过滤的字段,并选择是否存在或不存在该字段,然后点击应用过滤器按钮即可。
(5)脚本过滤器:脚本过滤器可以帮助您使用Painless脚本来筛选数据。在过滤器面板中,您可以选择要过滤的字段,并编写Painless脚本,然后点击应用过滤器按钮即可。使用脚本过滤器需要注意,过滤器的脚本不能包含查询语句或聚合操作,否则可能会导致性能问题。
除了以上几种过滤器之外,Kibana还提供了一些其他的过滤器,比如地理位置过滤器、正则表达式过滤器、词条过滤器等。这些过滤器都可以通过过滤器面板或搜索栏来添加,并根据具体的场景选择合适的过滤器
除了自定义筛选器,我们还可以自定义DSL搜索语法
Query DSL是一个Java开源框架用于构建类型安全的SQL查询语句。采用API代替传统的拼接字符串来构造查询语句。目前Querydsl支持的平台包括JPA,JDO,SQL,Java Collections,RDF,Lucene,Hibernate Search。elasticsearch提供了一整套基于JSON的查询DSL语言来定义查询。
Query DSL当作是一系列的抽象的查询表达式树(AST)特定查询能够包含其它的查询,(如 bool ), 有些查询能够包含过滤器(如 constant_score), 还有的可以同时包含查询和过滤器 (如 filtered). 都能够从ES支持查询集合里面选择任意一个查询或者是从过滤器集合里面挑选出任意一个过滤器, 这样的话,我们就可以构造出任意复杂(maybe 非常有趣)的查询了。
DSL语法:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
例如:查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
索引操作
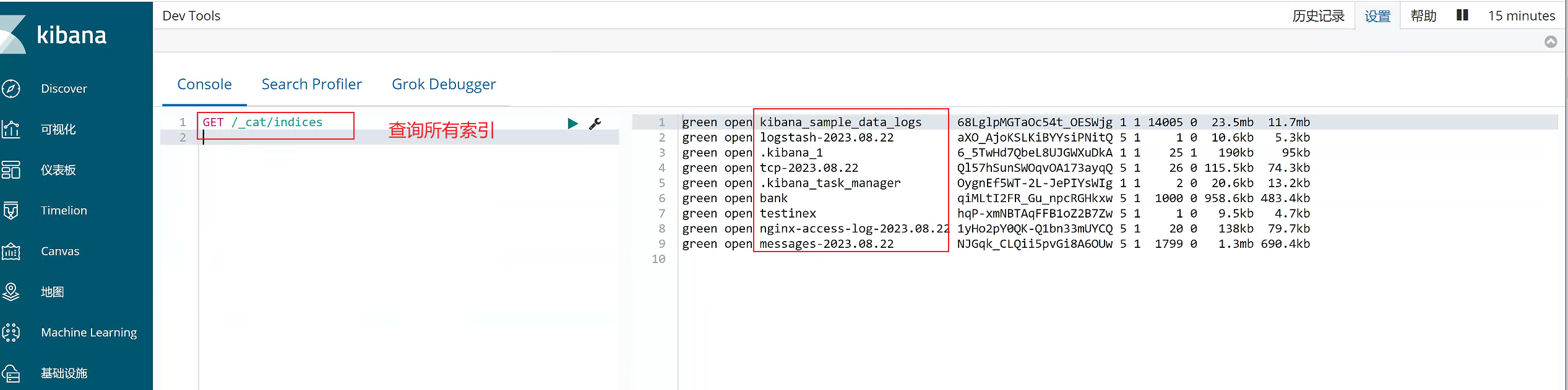
1)查询所有索引
GET /_cat/indices
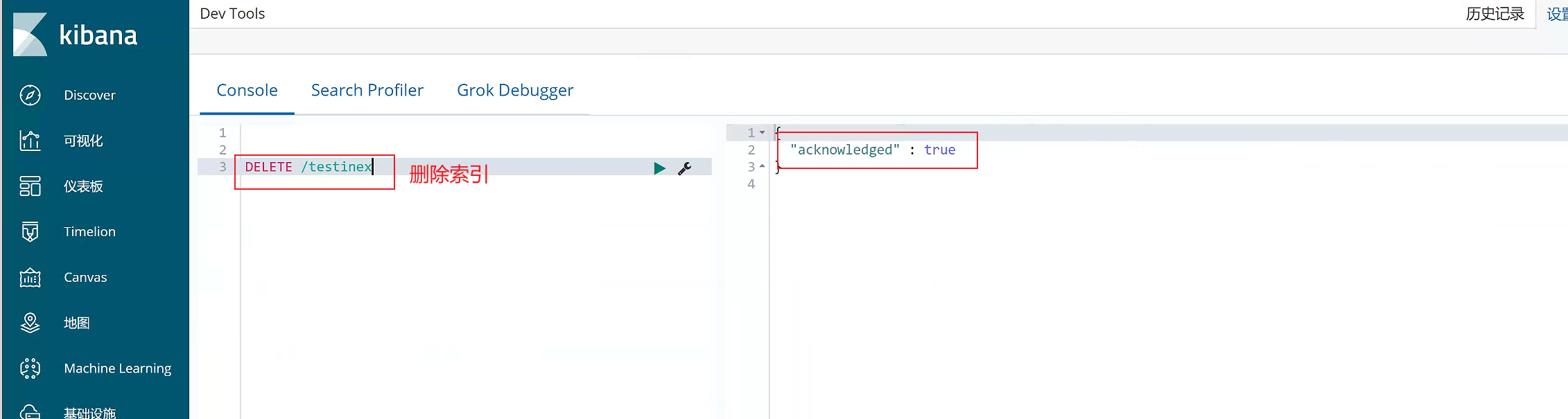
2)删除某个索引
DELETE /testinex
- 新建索引
PUT /testindex

4)新增文档数据
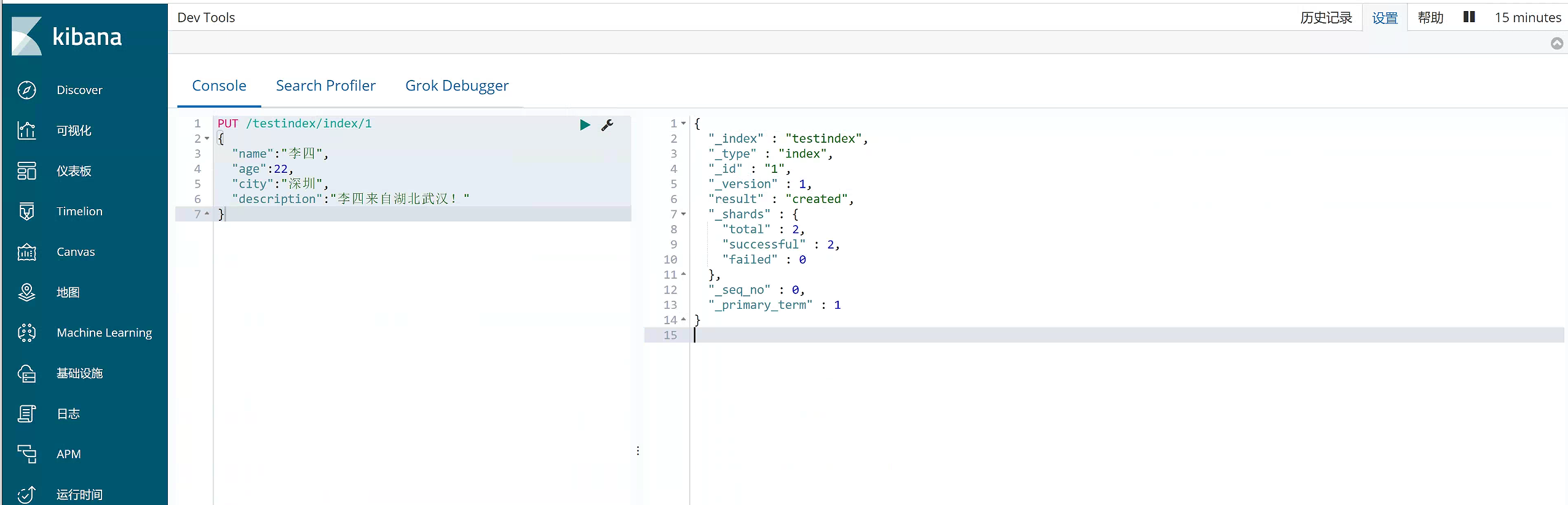
PUT /testindex/index/1
{
"name":"李四",
"age":22,
"city":"深圳",
"description":"李四来自湖北武汉!"
}
#新增文档数据 id=2
PUT /testindex/index/2
{
"name":"王五",
"age":35,
"city":"深圳",
"description":"王五家住在深圳!"
}
#新增文档数据 id=3
PUT /testindex/index/3
{
"name":"张三",
"age":19,
"city":"深圳",
"description":"在深圳打工,来自湖北武汉"
}
#新增文档数据 id=4
PUT /testindex/index/4
{
"name":"张三丰",
"age":66,
"city":"武汉",
"description":"在武汉读书,家在武汉!"
}
#新增文档数据 id=5
PUT /testindex/index/5
{
"name":"赵子龙",
"age":77,
"city":"广州",
"description":"赵子龙来自深圳宝安,但是在广州工作!",
"address":"广东省茂名市"
}
#新增文档数据 id=6
PUT /testindex/index/6
{
"name":"赵毅",
"age":55,
"city":"广州",
"description":"赵毅来自广州白云区,从事电子商务8年!"
}
#新增文档数据 id=7
PUT /testindex/index/7
{
"name":"赵哈哈",
"age":57,
"city":"武汉",
"description":"武汉赵哈哈,在深圳打工已有半年了,月薪7500!"
}
5)修改数据
a.替换操作
更新数据可以使用之前的增加操作,这种操作会将整个数据替换掉,代码如下:
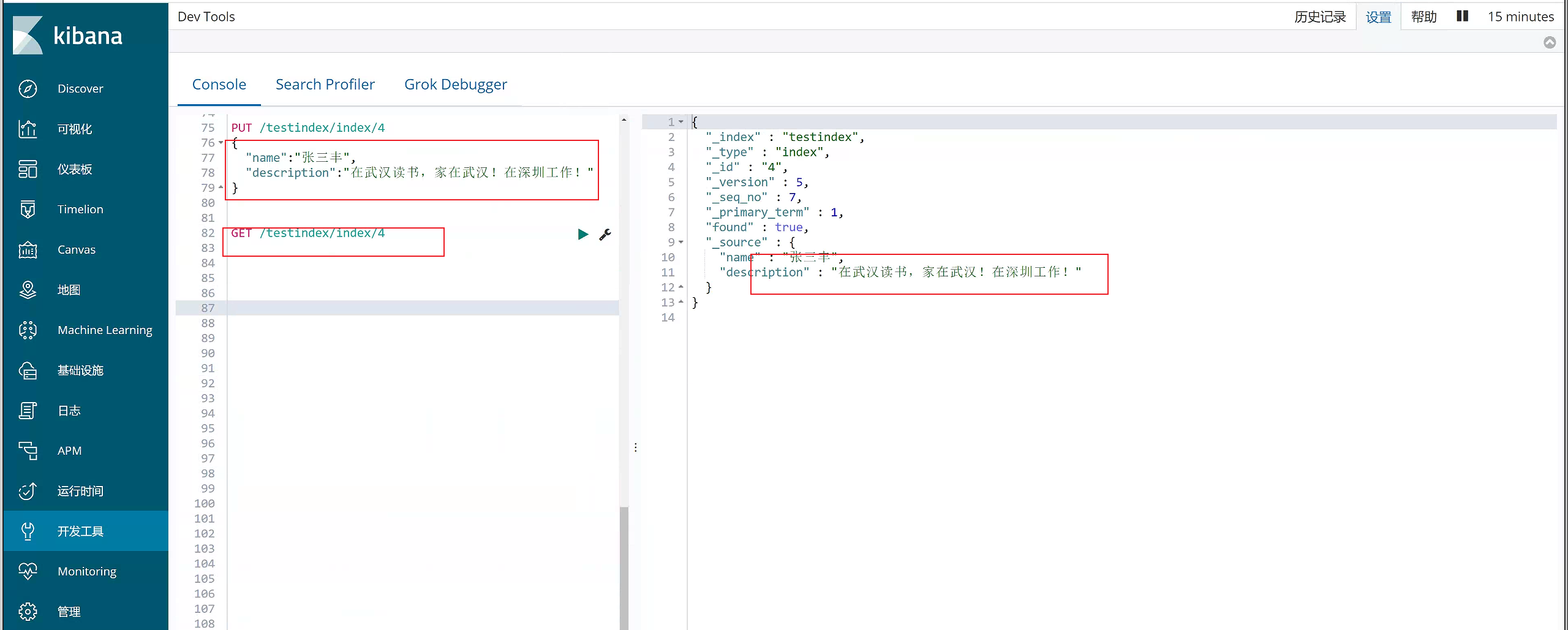
#更新数据,id=4
PUT /testindex/index/4
{
"name":"张三丰",
"description":"在武汉读书,家在武汉!在深圳工作!"
}
b.更新操作(部分)
我们先使用下面命令恢复数据:
#恢复文档数据 id=4
PUT /testindex/index/4
{
"name":"张三丰",
"age":66,
"city":"武汉",
"description":"在武汉读书,家在武汉!"
}
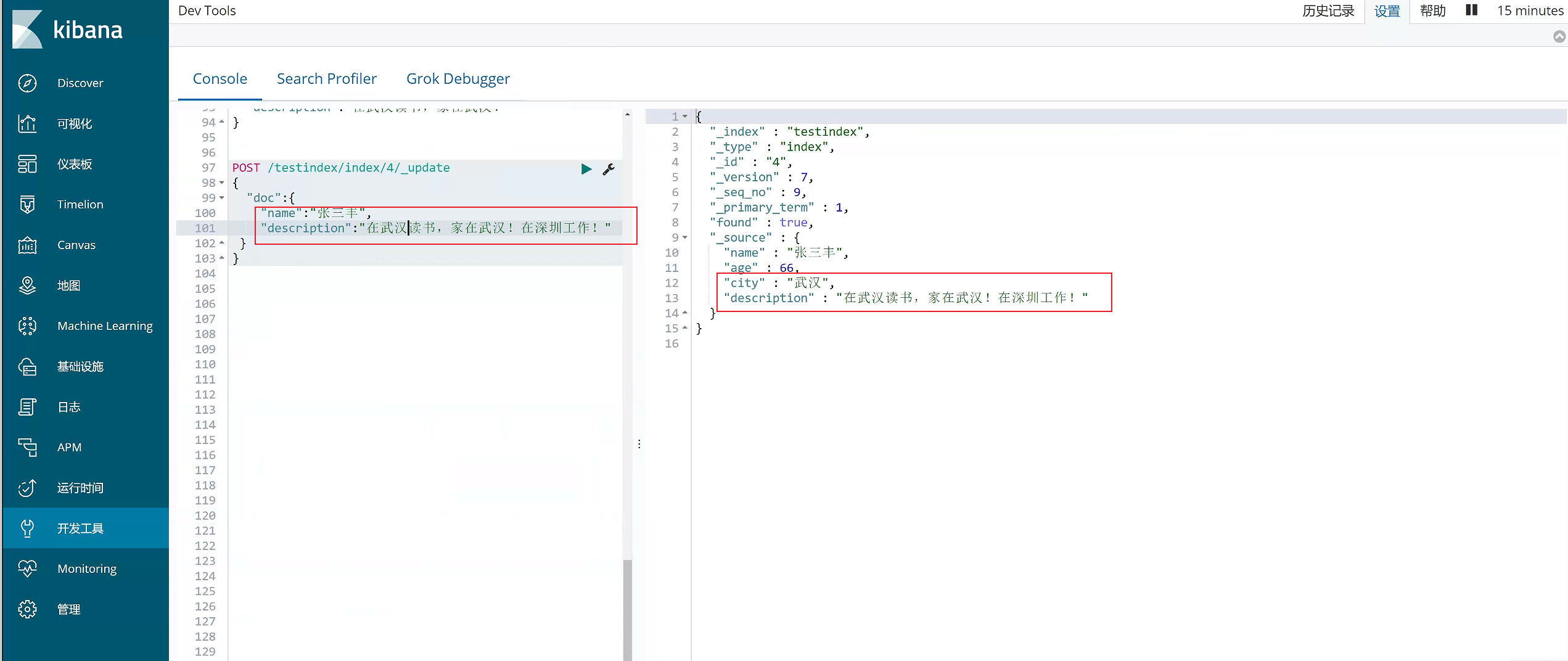
使用POST更新某个列的数据
#使用POST更新某个域的数据
POST /testindex/index/4/_update
{
"doc":{
"name":"张三丰",
"description":"在武汉读书,家在武汉!在深圳工作!"
}
}
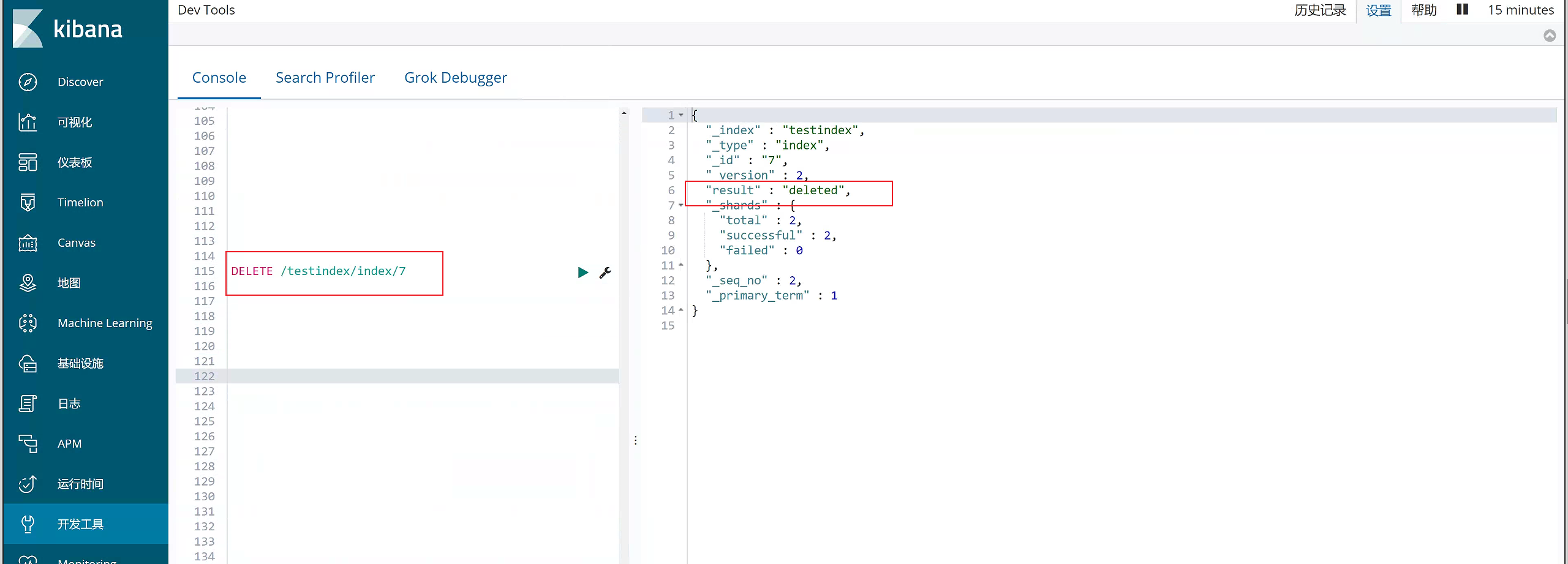
6)删除数据
DELETE /testindex/index/7
7)Sort排序
#搜索排序
GET /testindex/_search
{
"query": {
"match_all": {}
},
"sort":{
"age":{
"order":"desc"
}
}
}
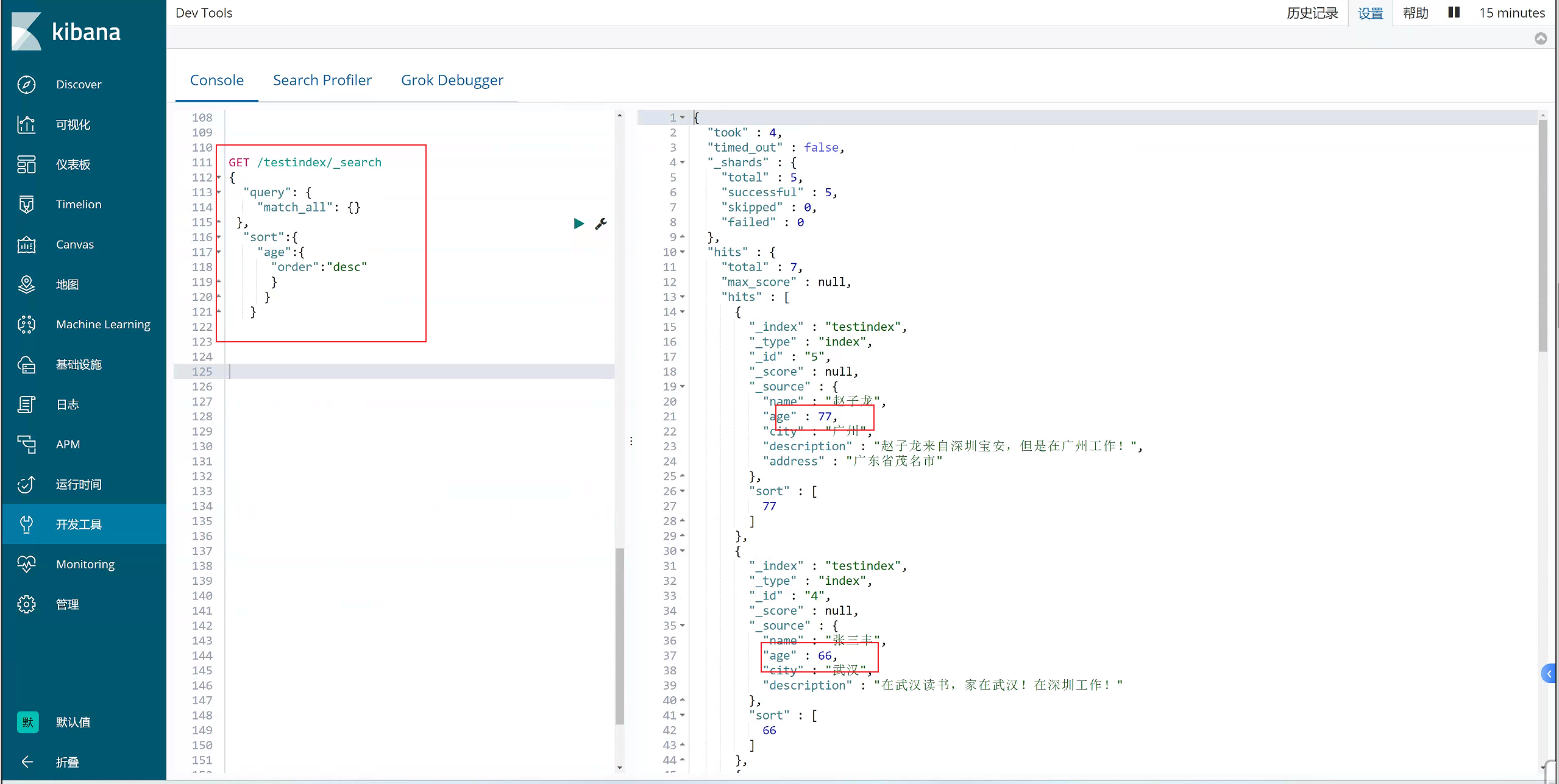
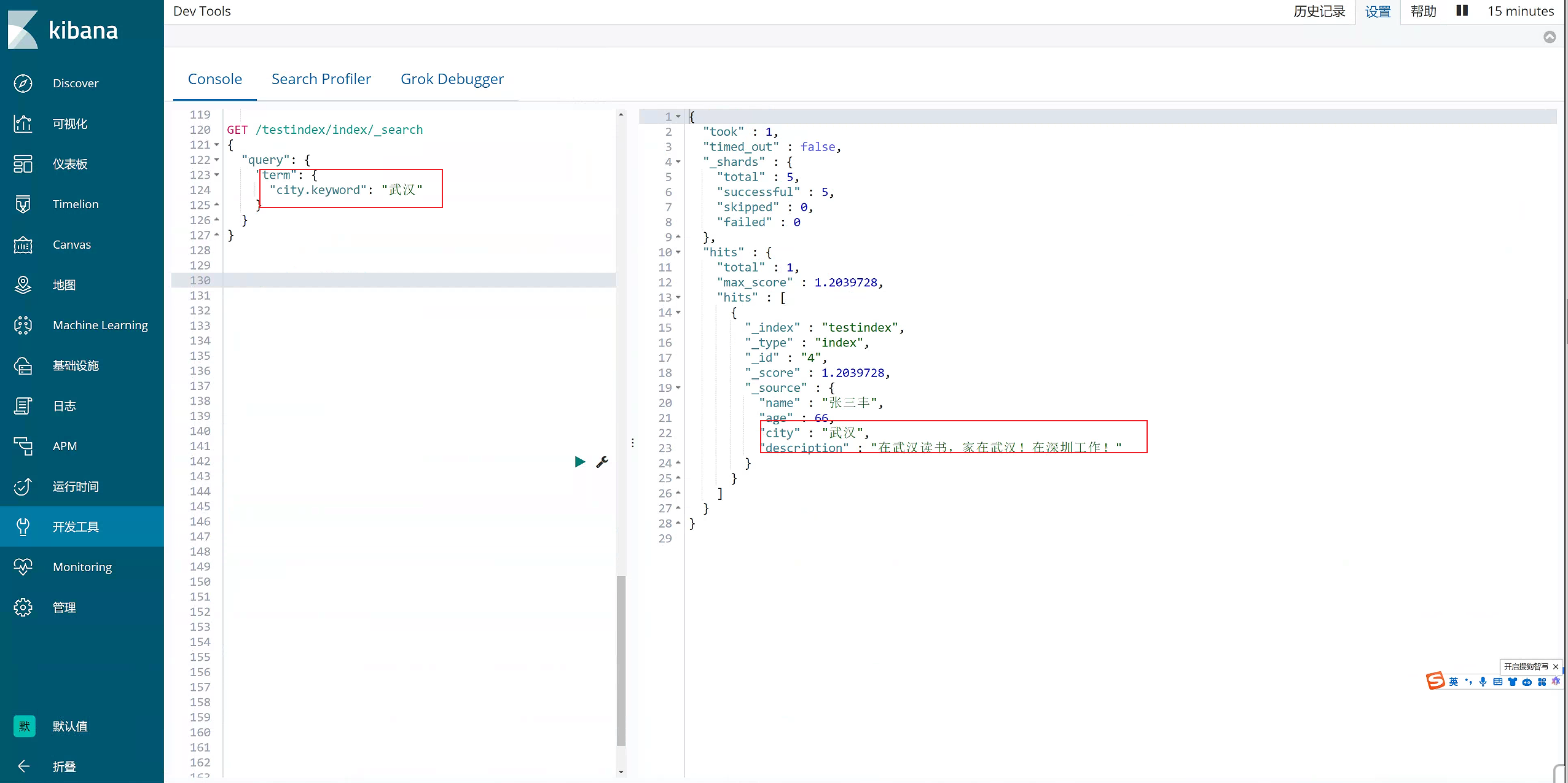
8)term过滤
term主要用于分词精确匹配,如字符串、数值、日期等(不适合情况:1.列中除英文字符外有其它值 2.字符串值中有冒号或中文 3.系统自带属性如_version)
GET /testindex/index/_search
{
"query": {
"term": {
"city.keyword": "武汉"
}
}
}
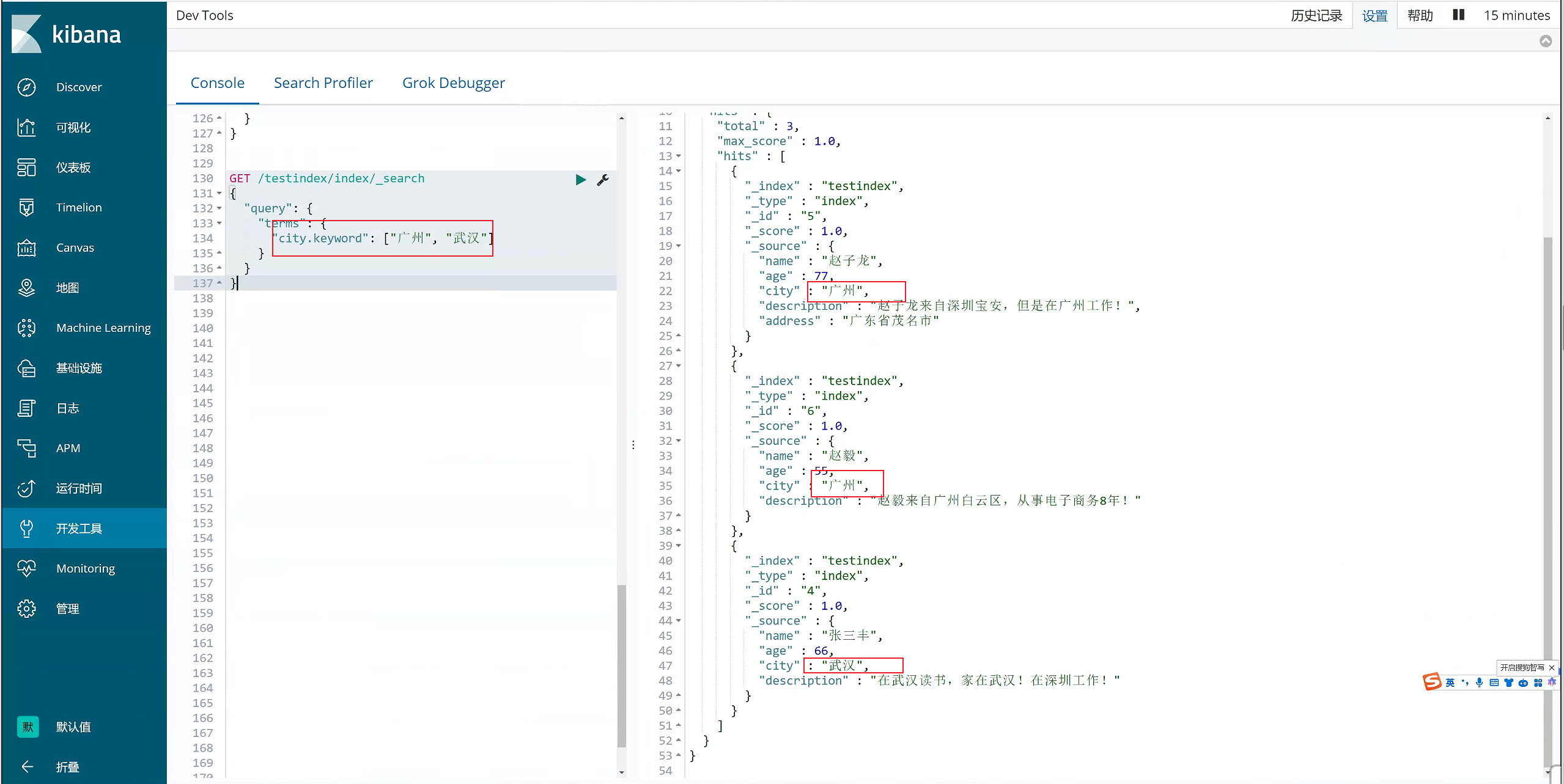
- terms 过滤
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配
GET /testindex/index/_search
{
"query": {
"terms": {
"city.keyword": ["广州", "武汉"]
}
}
}
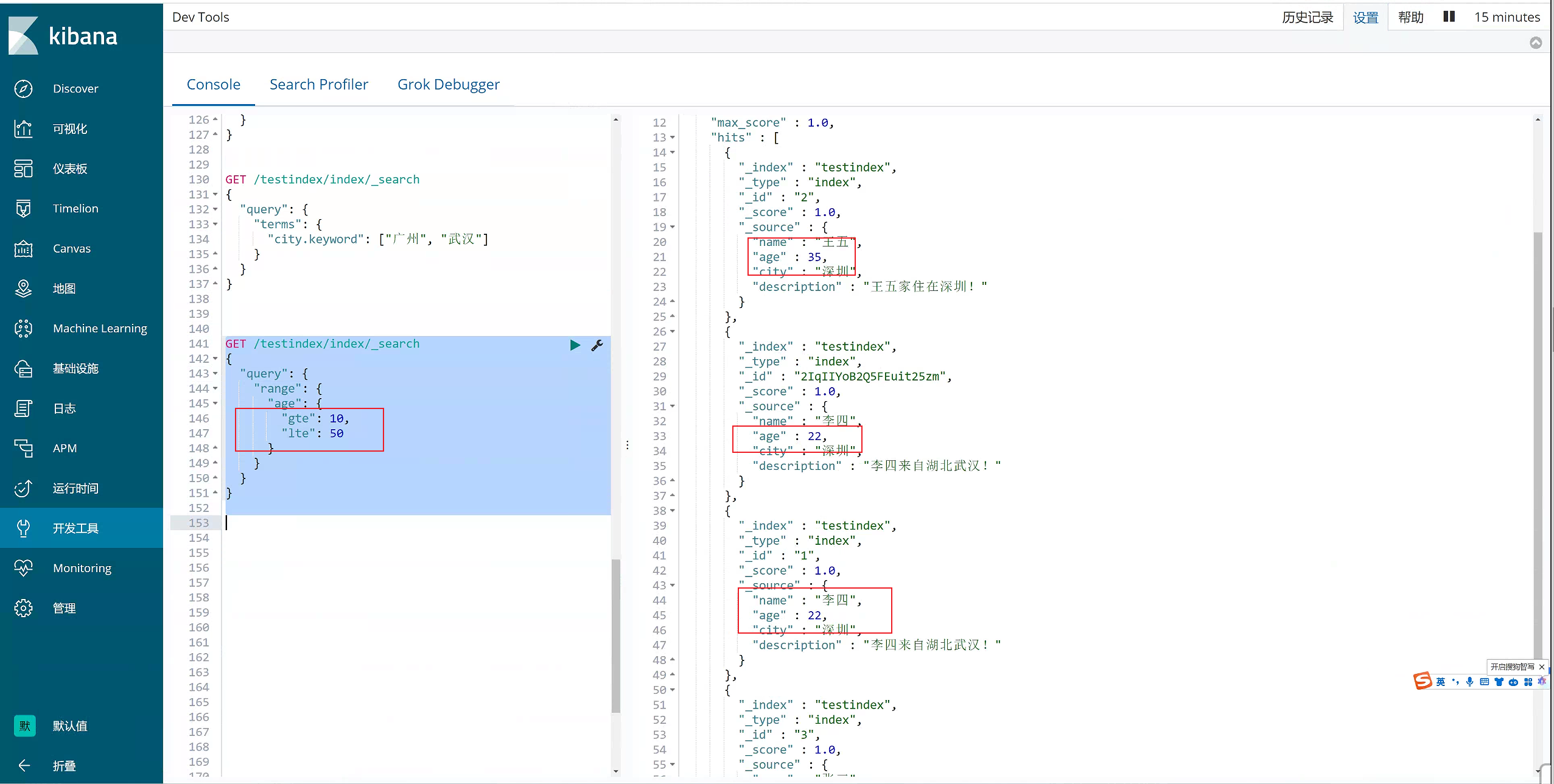
10)range 过滤
range过滤允许我们按照指定范围查找一批数据。例如我们查询年龄范围
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET /testindex/index/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
}
}
11)exists过滤
exists 过滤可以用于查找拥有某个域的数据
#过滤搜索 exists:是指包含某个域的数据检索
GET _search
{
"query": {
"exists": {
"field":"address"
}
}
}
- bool 过滤
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
- must : 多个查询条件的完全匹配,相当于 and。
- must_not : 多个查询条件的相反匹配,相当于 not。
- should : 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:
#过滤搜索 bool
#must : 多个查询条件的完全匹配,相当于 and。
#must_not : 多个查询条件的相反匹配,相当于 not。
#should : 至少有一个查询条件匹配, 相当于 or。
GET _search
{
"query":{
"bool":{
"must":[
{
"term":{
"city":{
"value":"深圳"
}
}
},
{
"range":{
"age":{
"gte":20,
"lte":99
}
}
}
]
}
}
}
- match_all 查询
可以查询到所有文档,是没有查询条件下的默认语句。
案例如下:
#查询所有 match_all
GET /testindex/index/_search
{
"query": {
"match_all": {}
}
}
- match 查询
match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符:
案例如下:
#字符串匹配
GET /testindex/index/_search
{
"query": {
"match": {
"description": "武汉"
}
}
}
15)prefix 查询
以什么字符开头的,可以更简单地用 prefix ,例如查询所有以张开始的用户描述
案例如下:
#前缀匹配 prefix
GET _search
{
"query": {
"prefix":{
"name": {
"value": "赵"
}
}
}
}
- multi_match 查询
multi_match查询允许你做match查询的基础上同时搜索多个字段,在多个字段中同时查一个
#多个域匹配搜索
GET _search
{
"query": {
"multi_match": {
"query": "深圳",
"fields": [
"city",
"description"
]
}
}
}
2.12.3 定制数据可视化
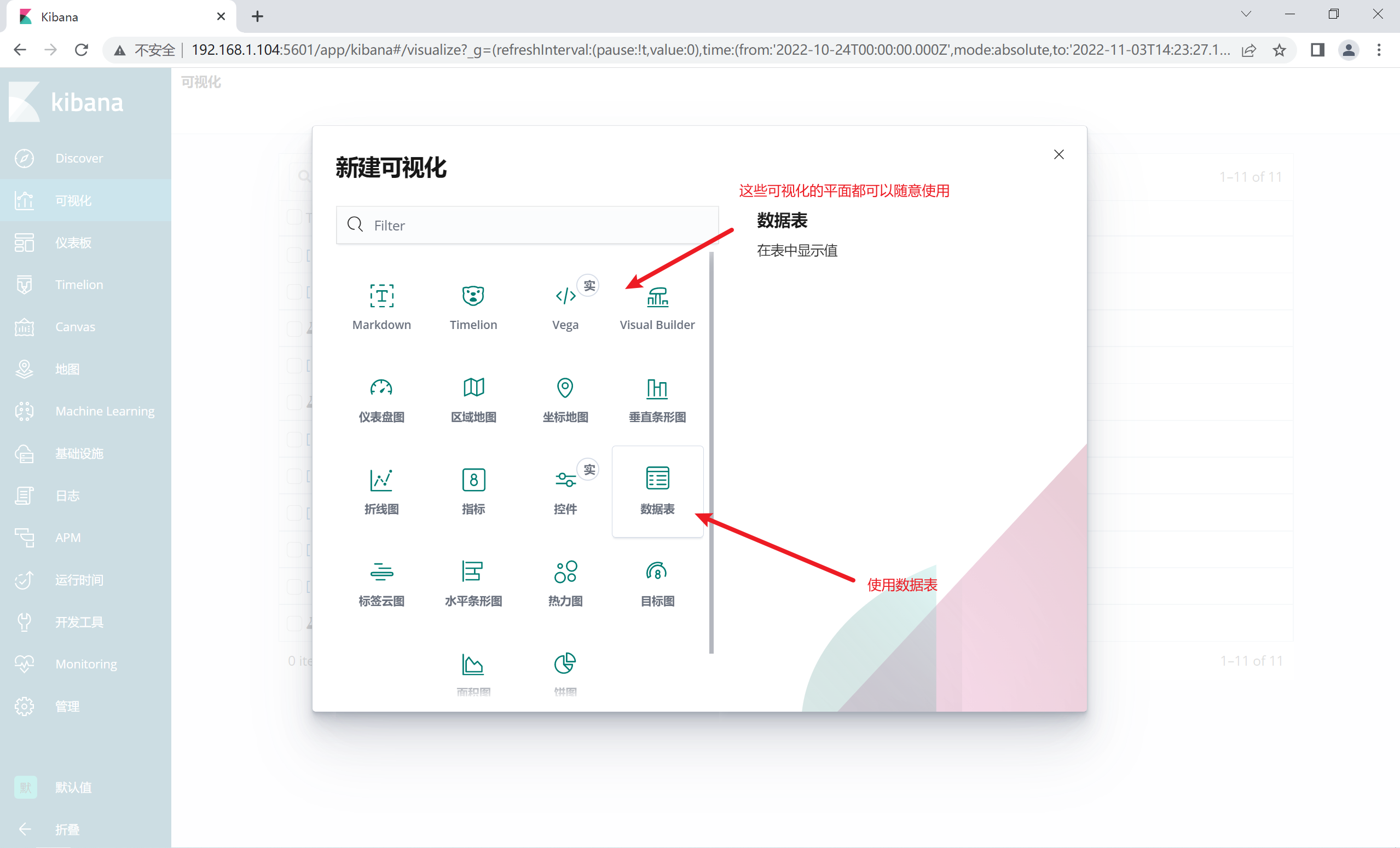
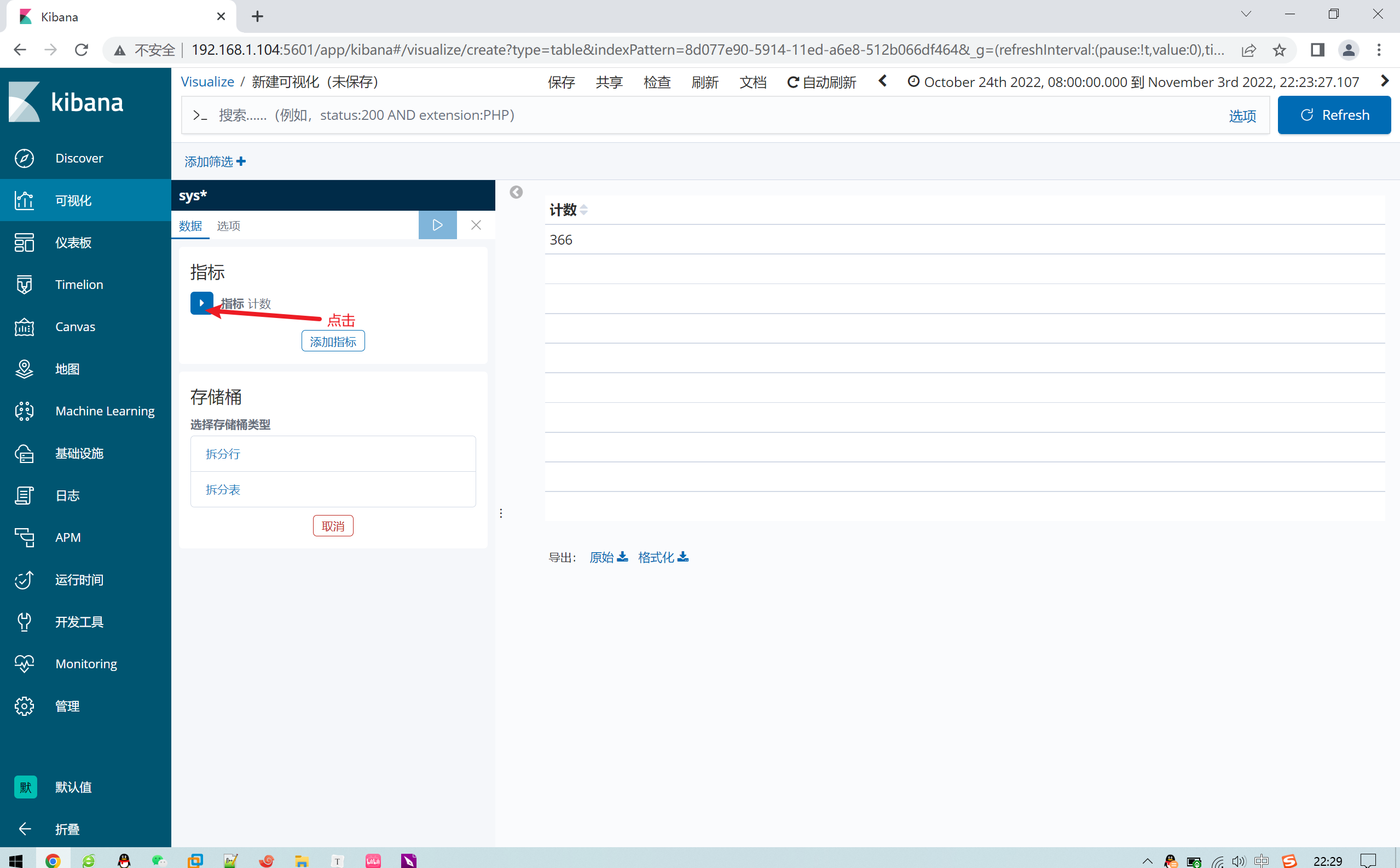
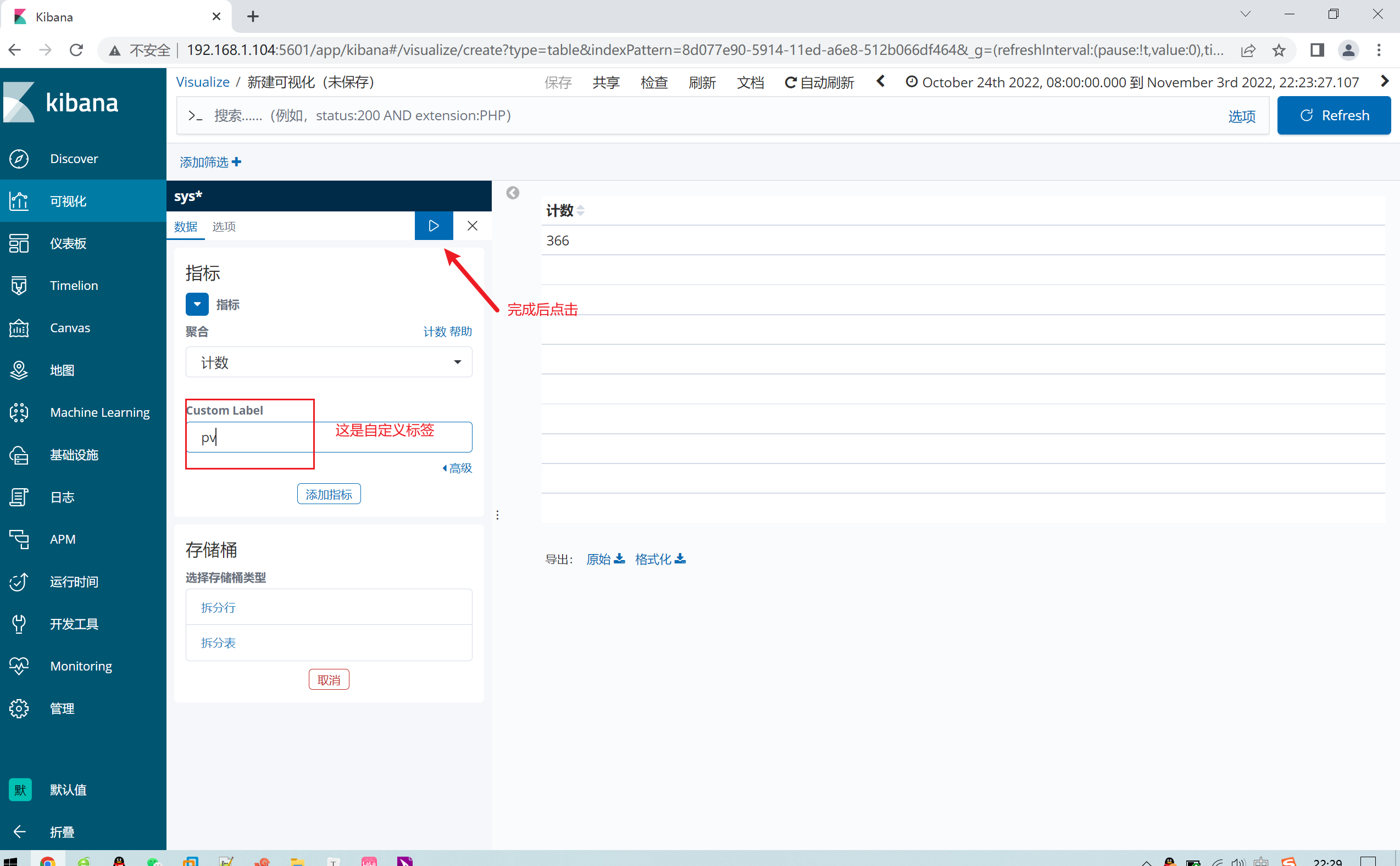
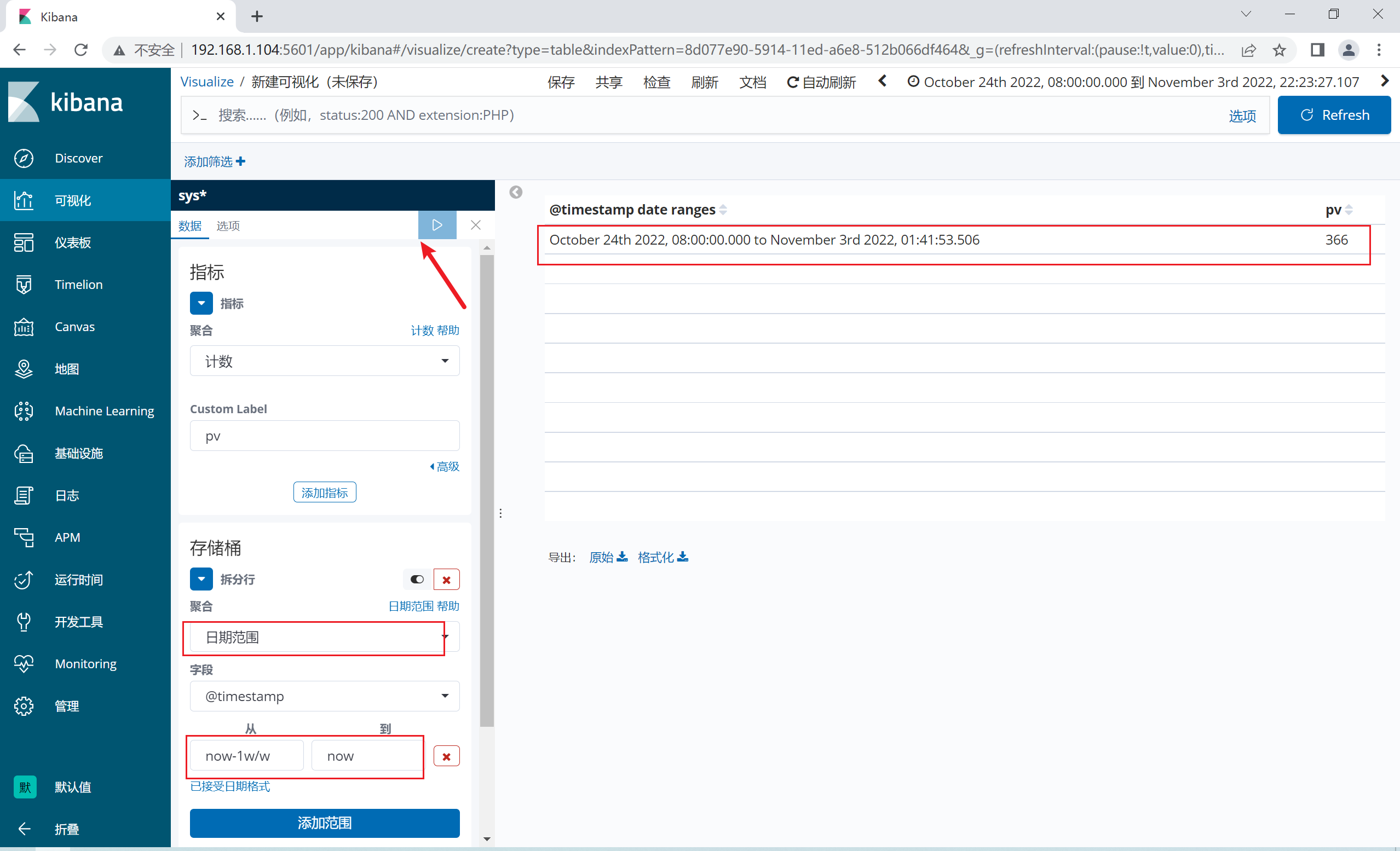
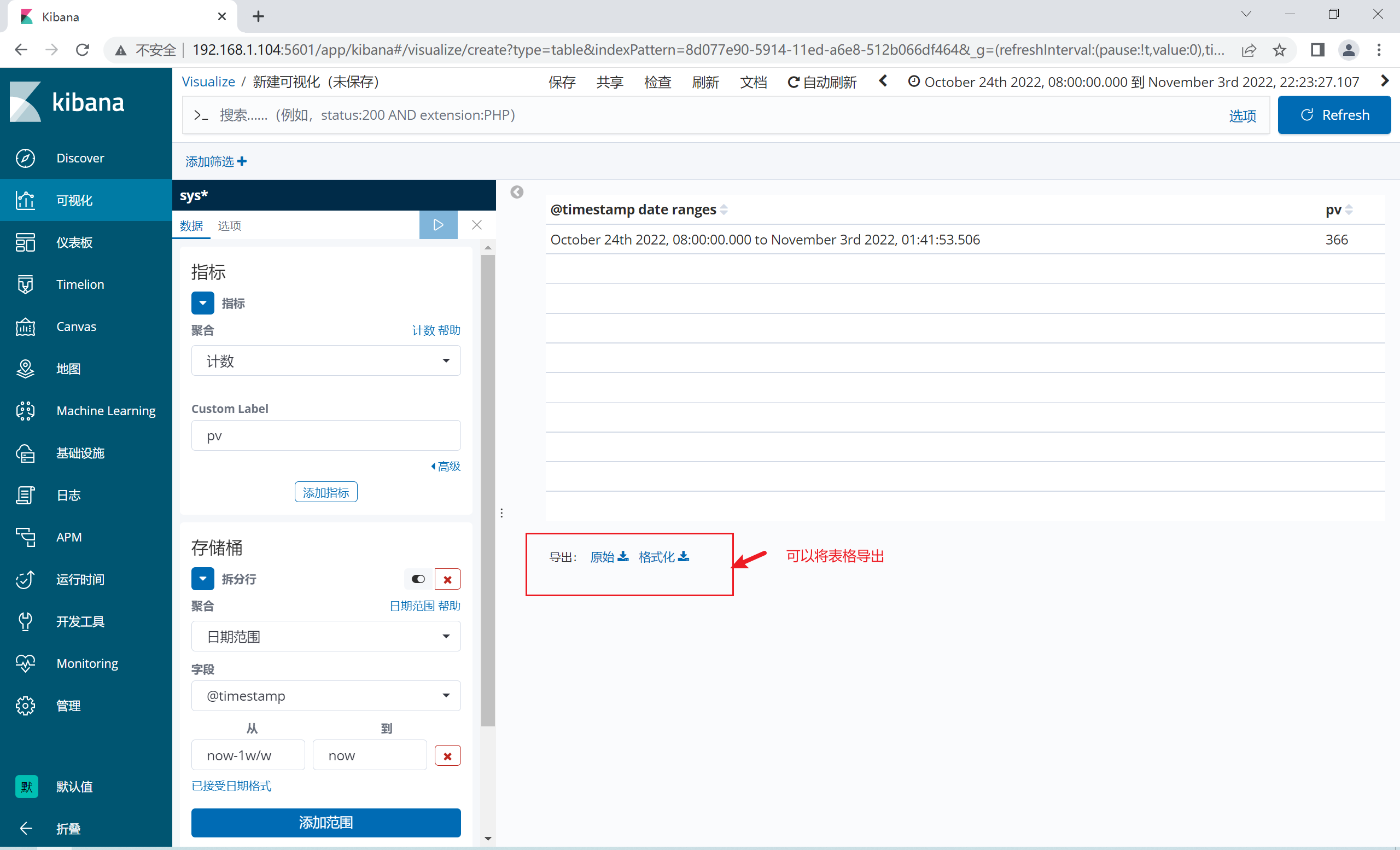
1.12.4 添加折线图
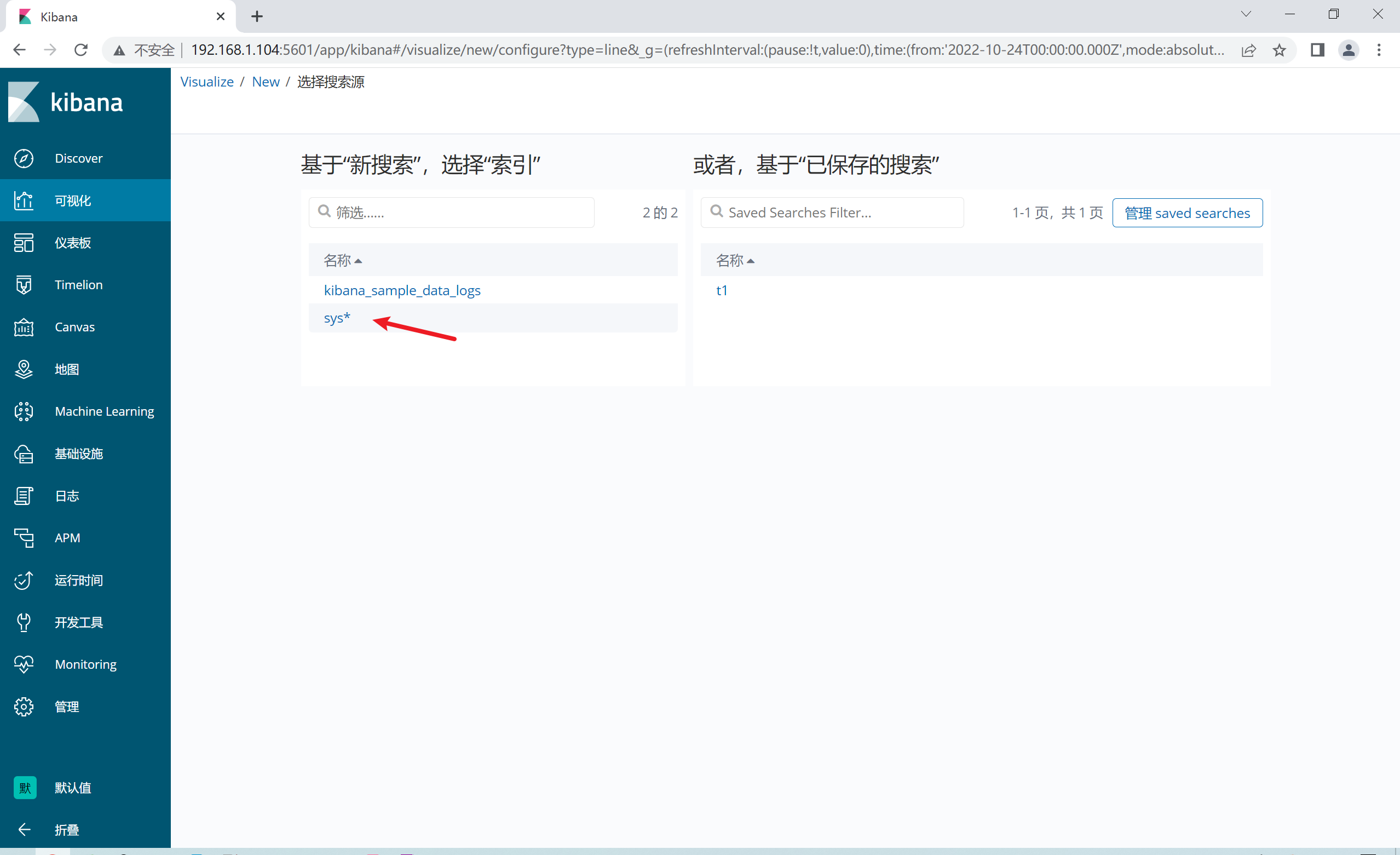
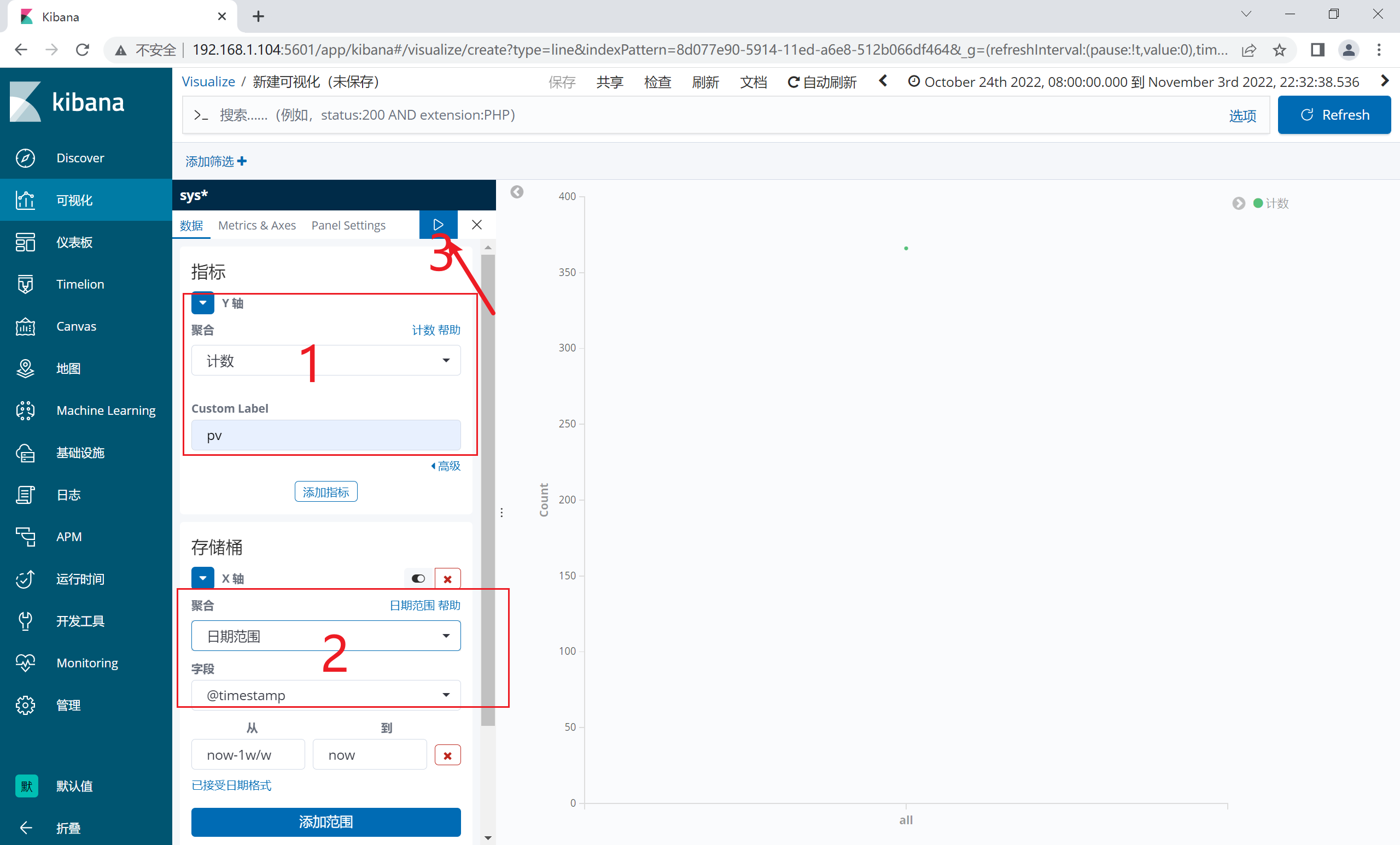
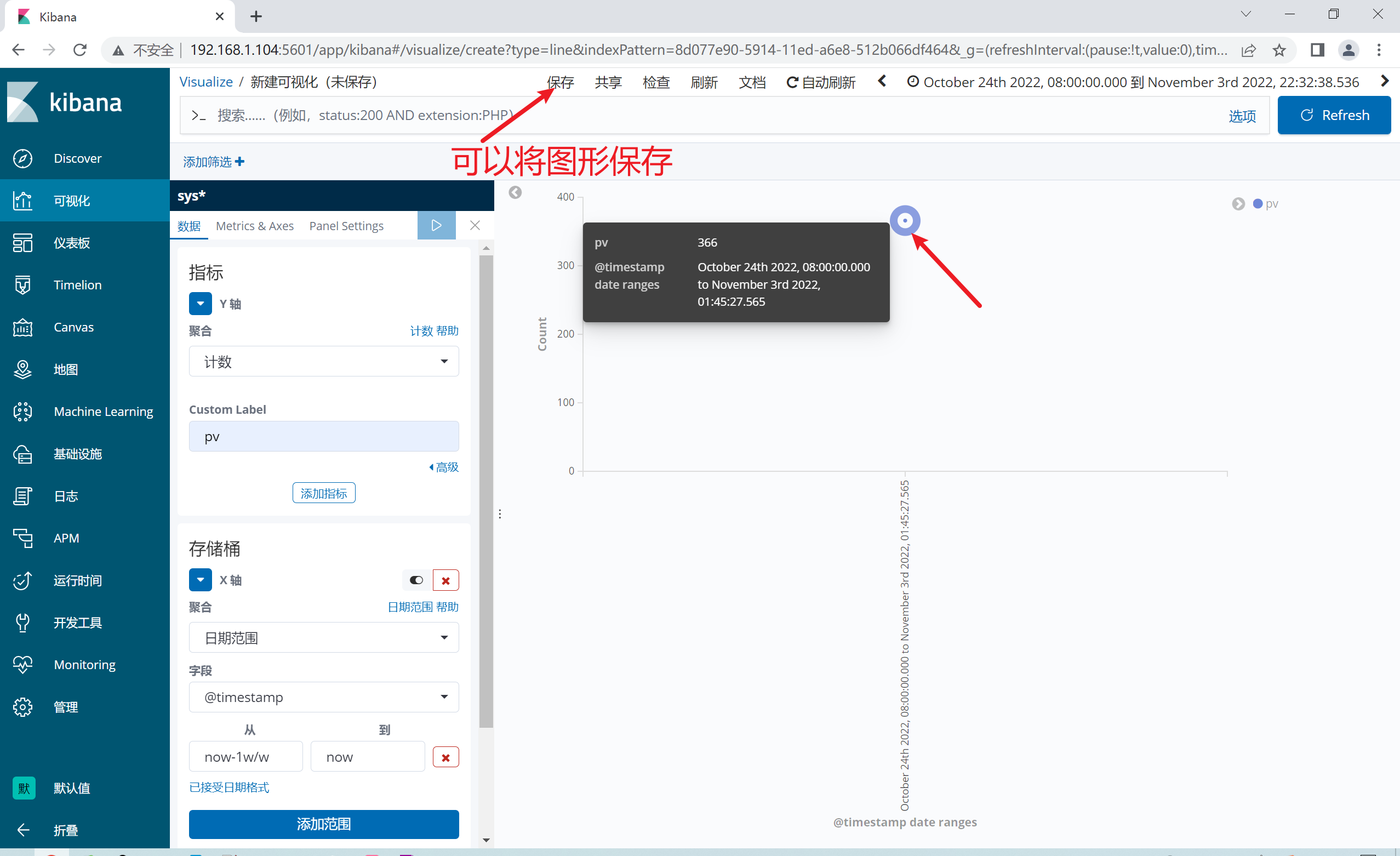
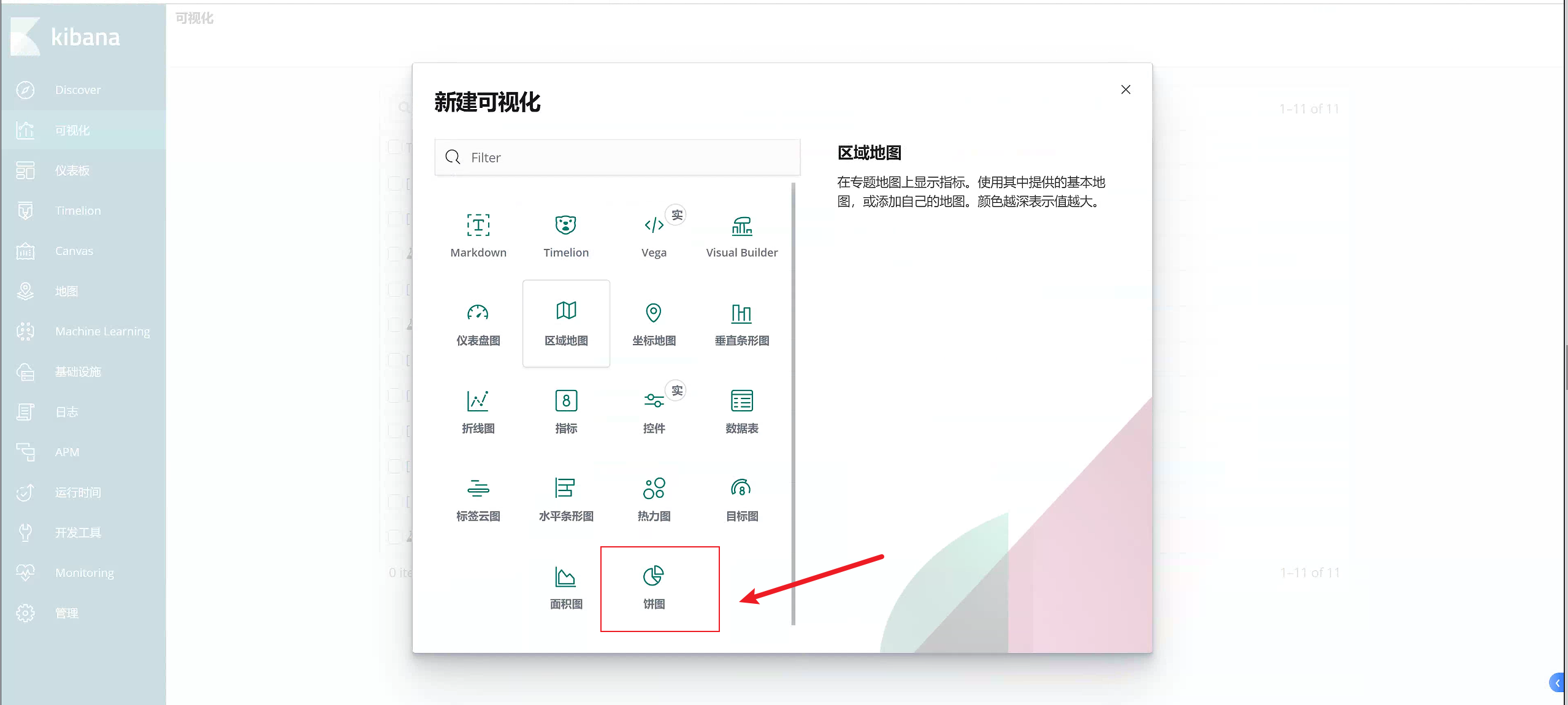
2.12.5 添加饼图
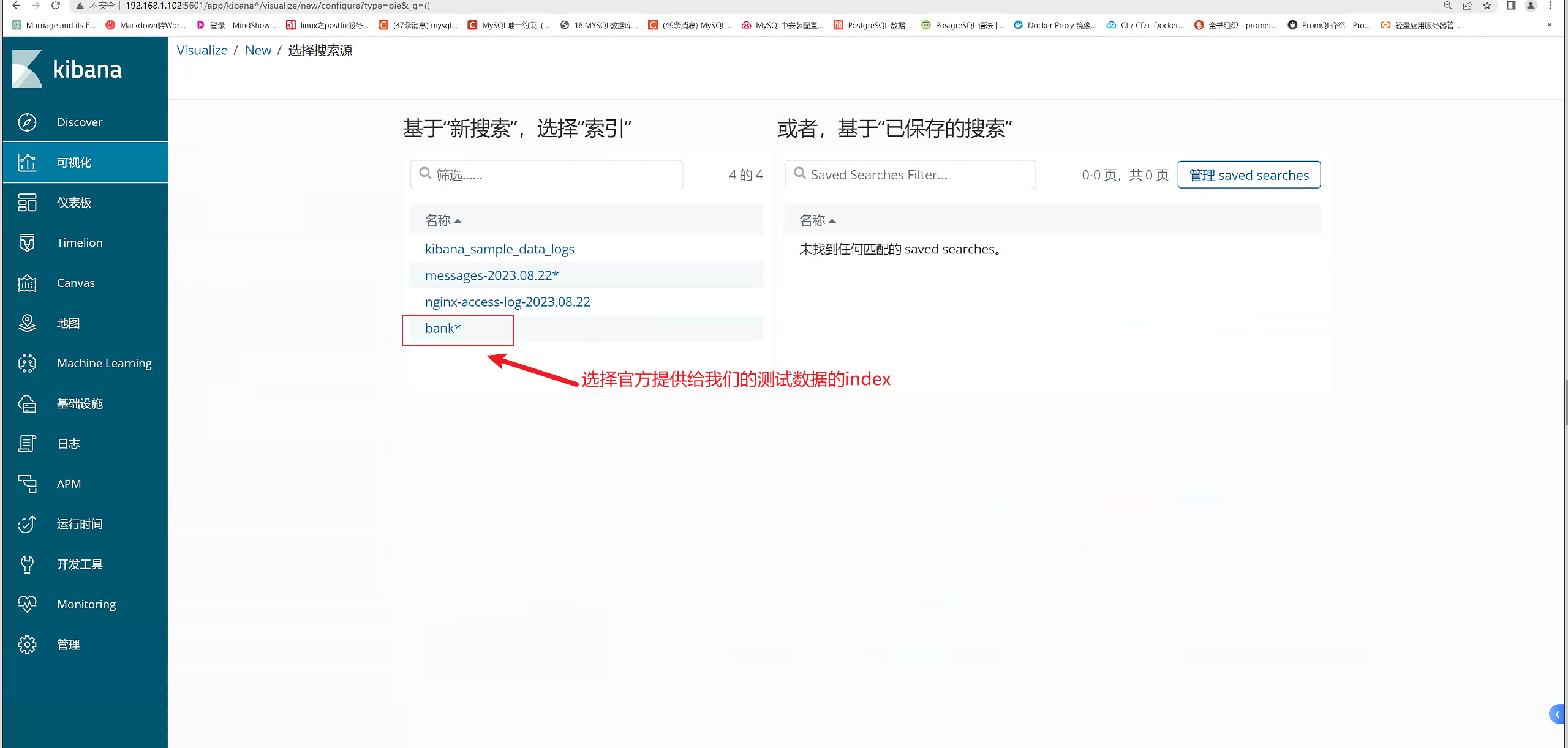
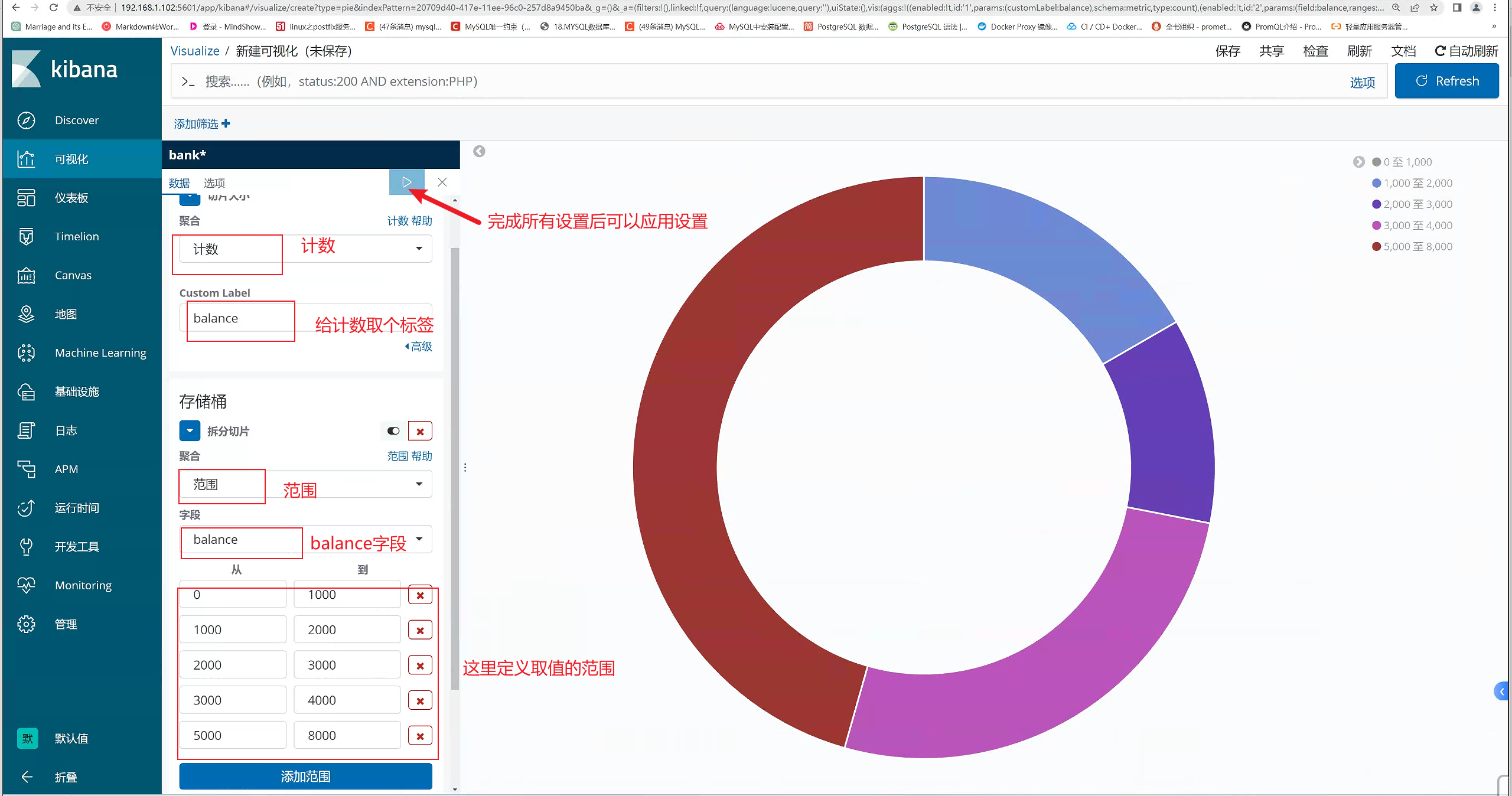
添加饼图,这里我们使用官方给我的测试数据来进行画图
指导手册:https://www.elastic.co/guide/cn/kibana/6.0/tutorial-visualizing.html
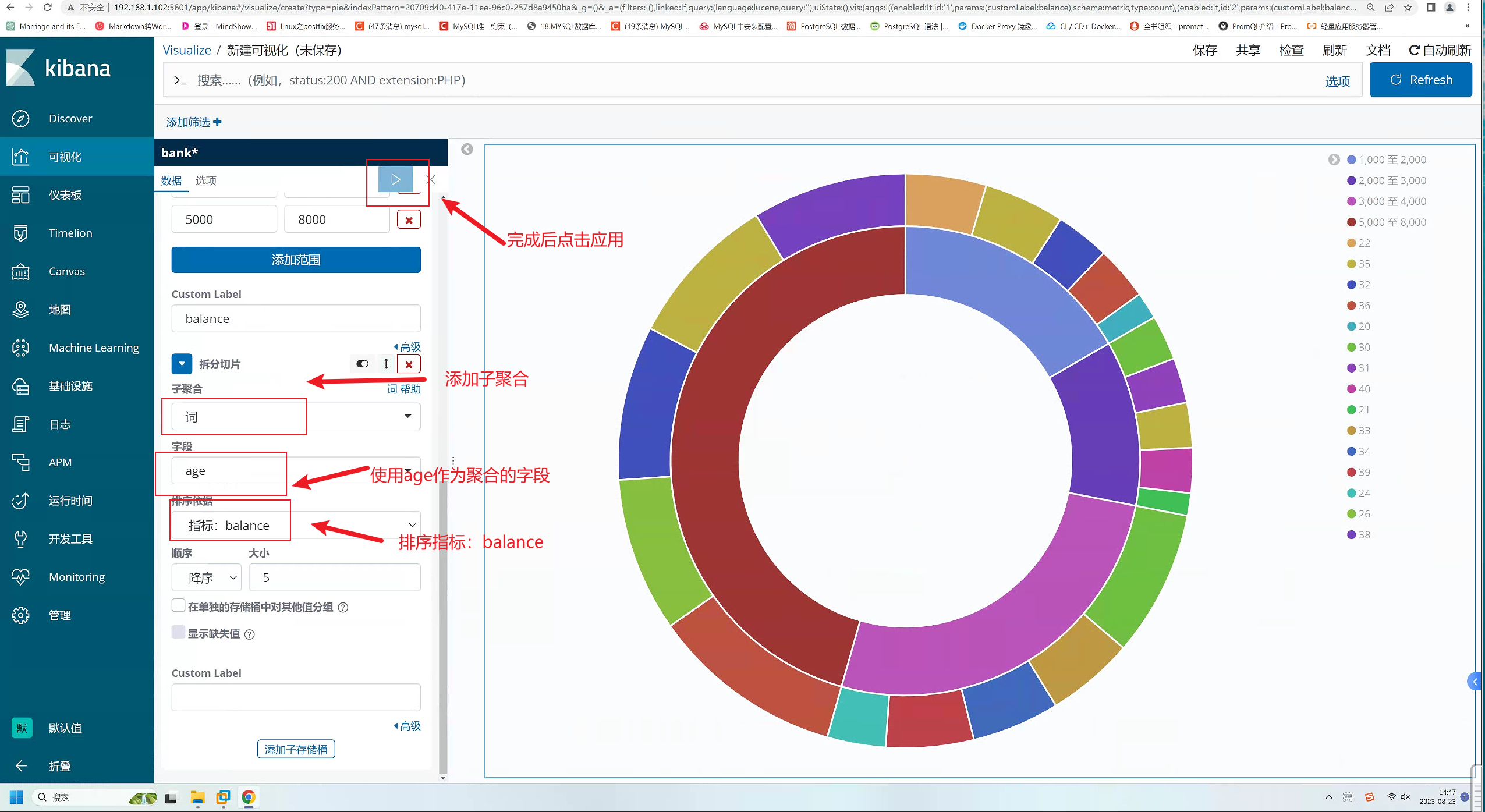
让我们看以下数据的另一方面:账户拥有者的年龄。通过添加另一个桶聚合,您可以看到每个余额区间的账户拥有者的年龄:
点击 保存 然后输入名称 Pie Example 来保存这个图表供以后使用。
2.12. 6 添加条形图

点击 保存 然后输入名称来保存这个图表供以后使用。
2.12 安装filebeat
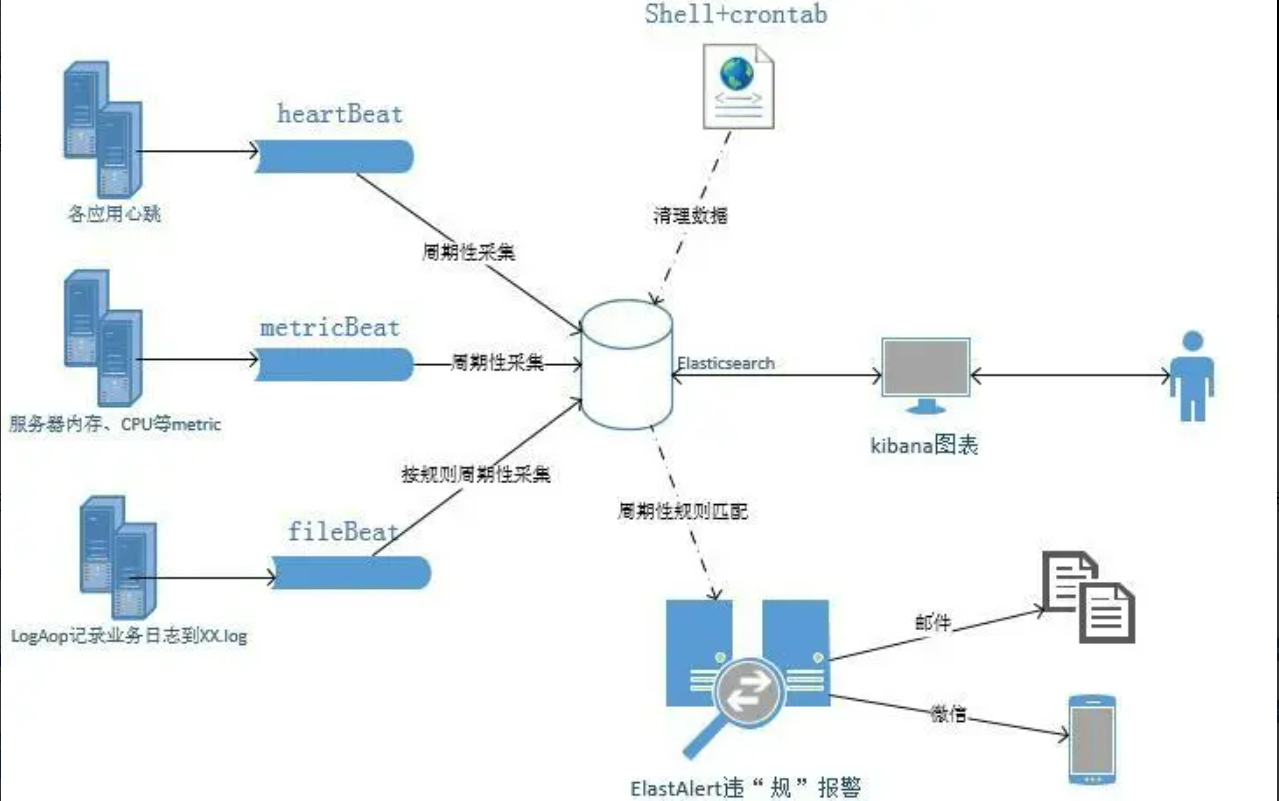
Filebeat 是使用 Golang 实现的轻量型日志采集器,也是 Elasticsearch stack 里面的一员。本质上是一个 agent ,可以安装在各个节点上,根据配置读取对应位置的日志,并上报到相应的地方去。早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
工作流程图如下:
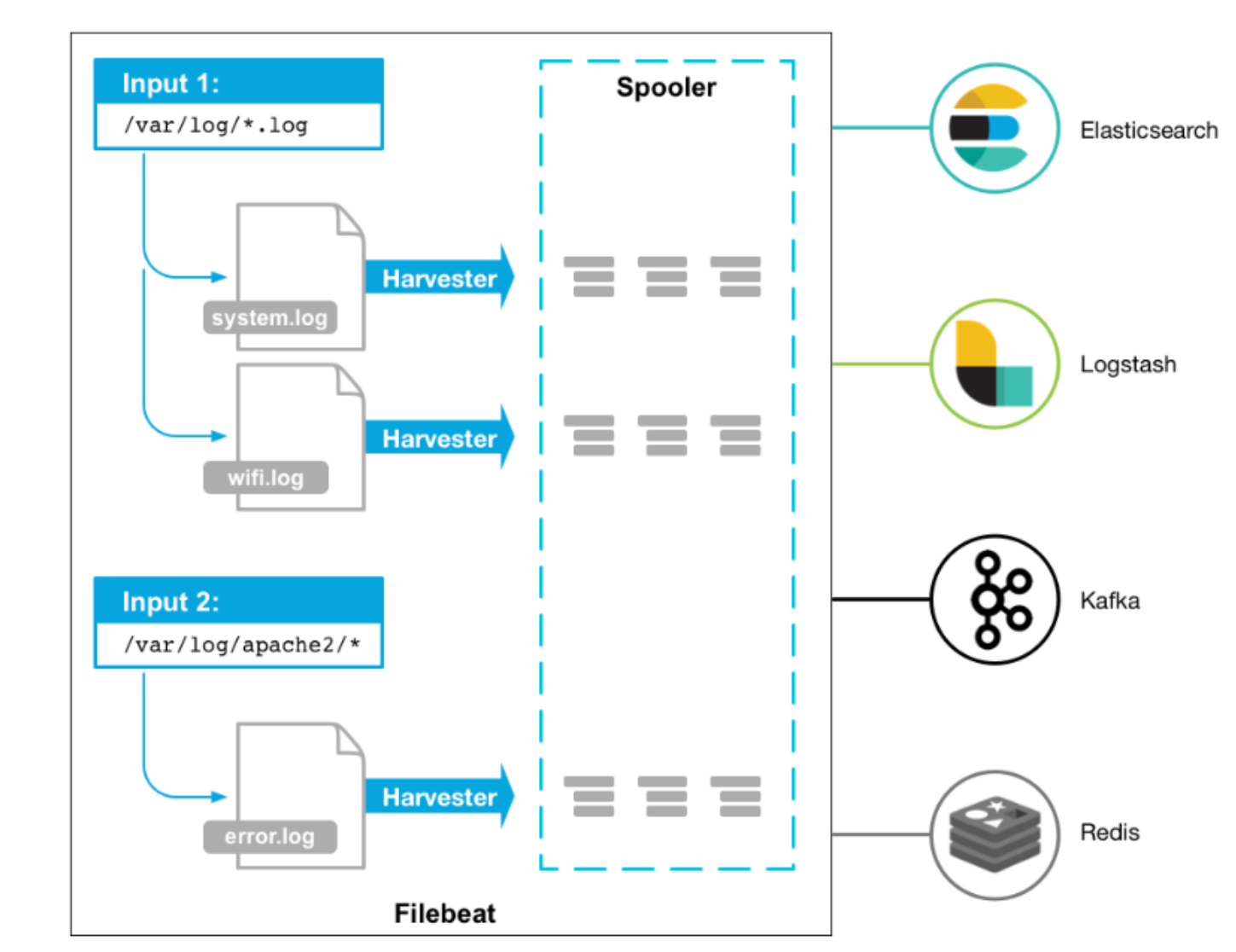
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:
启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
filebeat和logstash的关系
因为logstash是jvm跑的,资源消耗比较大,所以后来作者又用golang写了一个功能较少但是资源消耗也小的轻量级的logstash-forwarder。不过作者只是一个人,加入http://elastic.co公司以后,因为es公司本身还收购了另一个开源项目packetbeat,而这个项目专门就是用golang的,有整个团队,所以es公司干脆把logstash-forwarder的开发工作也合并到同一个golang团队来搞,于是新的项目就叫filebeat了。
2.12.1 下载filebeat
官方地址:https://www.elastic.co/cn/downloads/past-releases#filebeat
2.12.2 安装filebeat
[root@server5 ~]# tar zxvf filebeat-6.8.20-linux-x86_64.tar.gz -C /usr/local/src/
2.12.3 编辑配置文件
1)将日志传输到es
[root@server5 filebeat-6.8.20-linux-x86_64]#cat filebeat.yml
filebeat.inputs:
- type: log
enabled: true ##开启日志的收集的功能
paths:
- /var/log/*.log ##收集的日志类型
hosts: ["192.168.1.106:9200"] ##ES的服务器的IP
2.12.4 启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
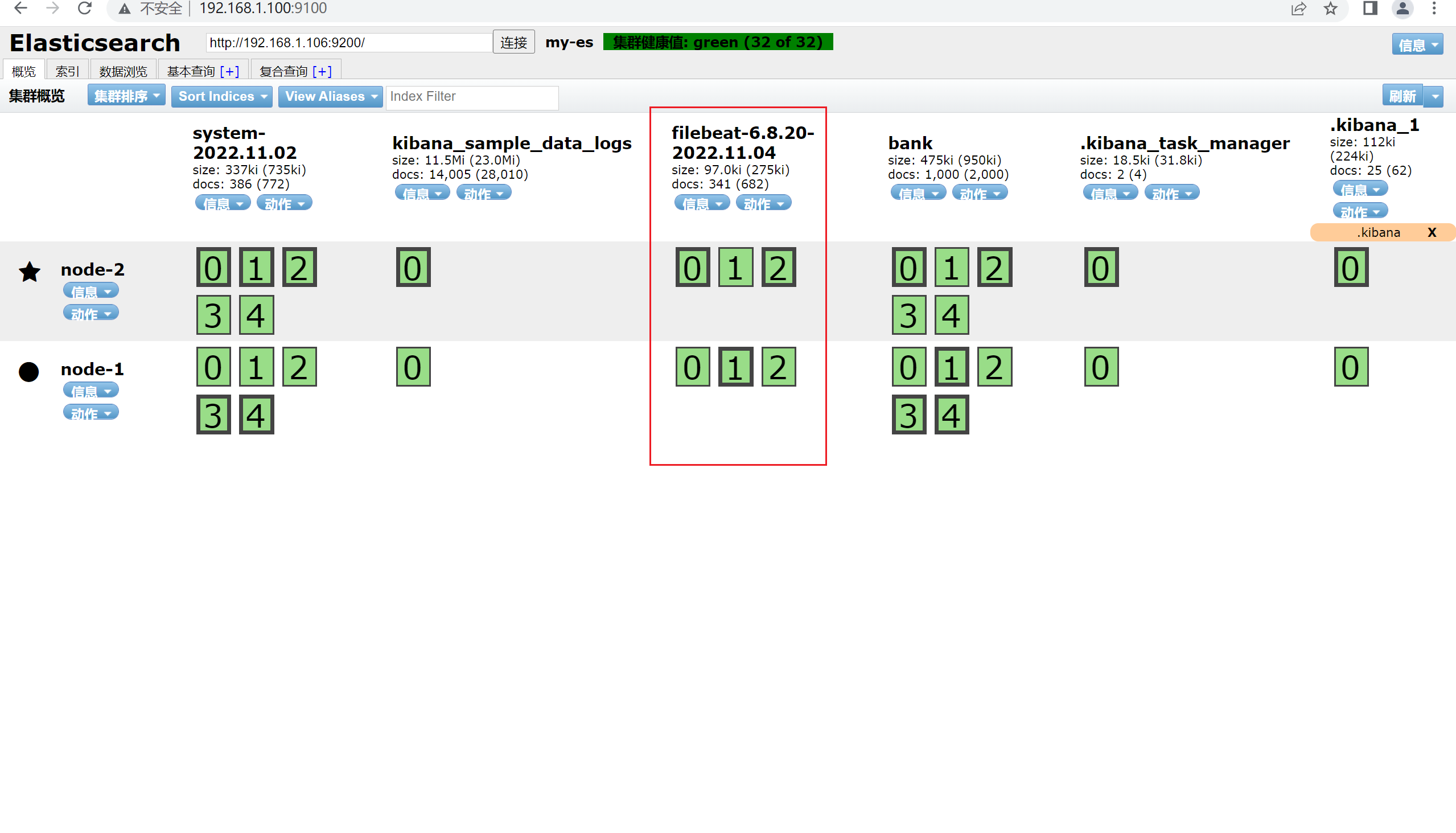
2.12.5 ES端查看
默认的索引的名字是filebeat开头。
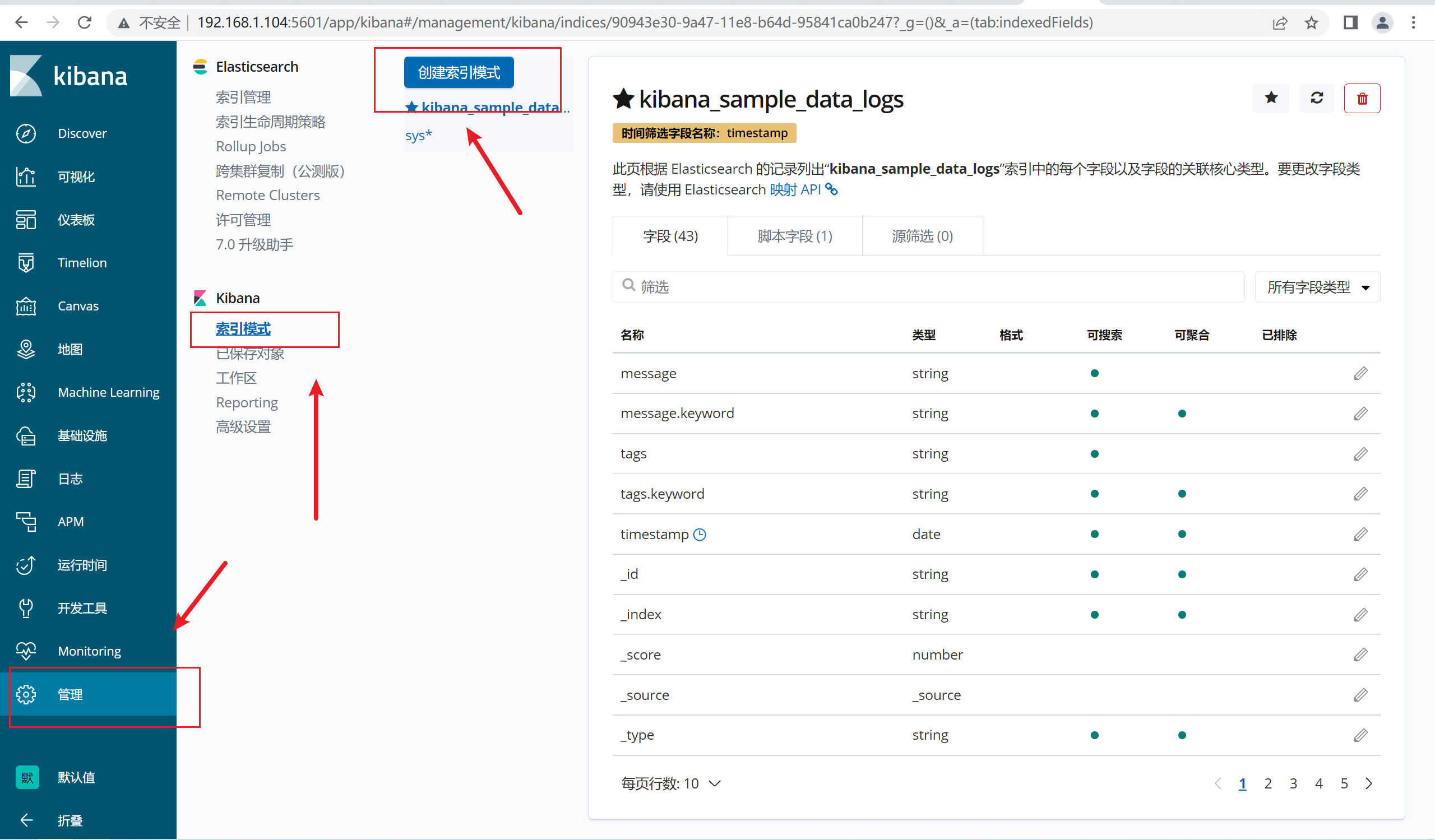
2.12.6 kibana端新建索引
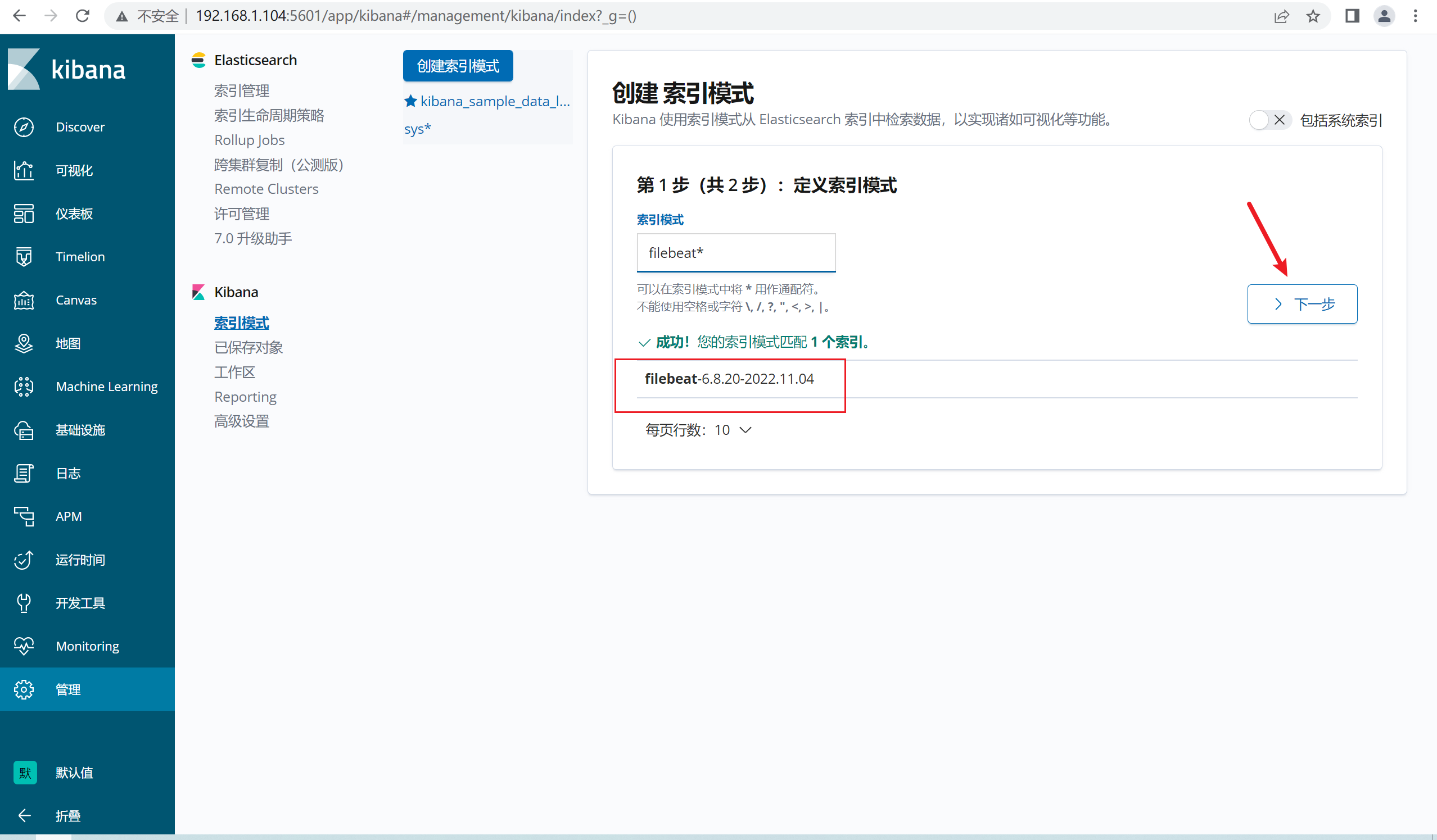
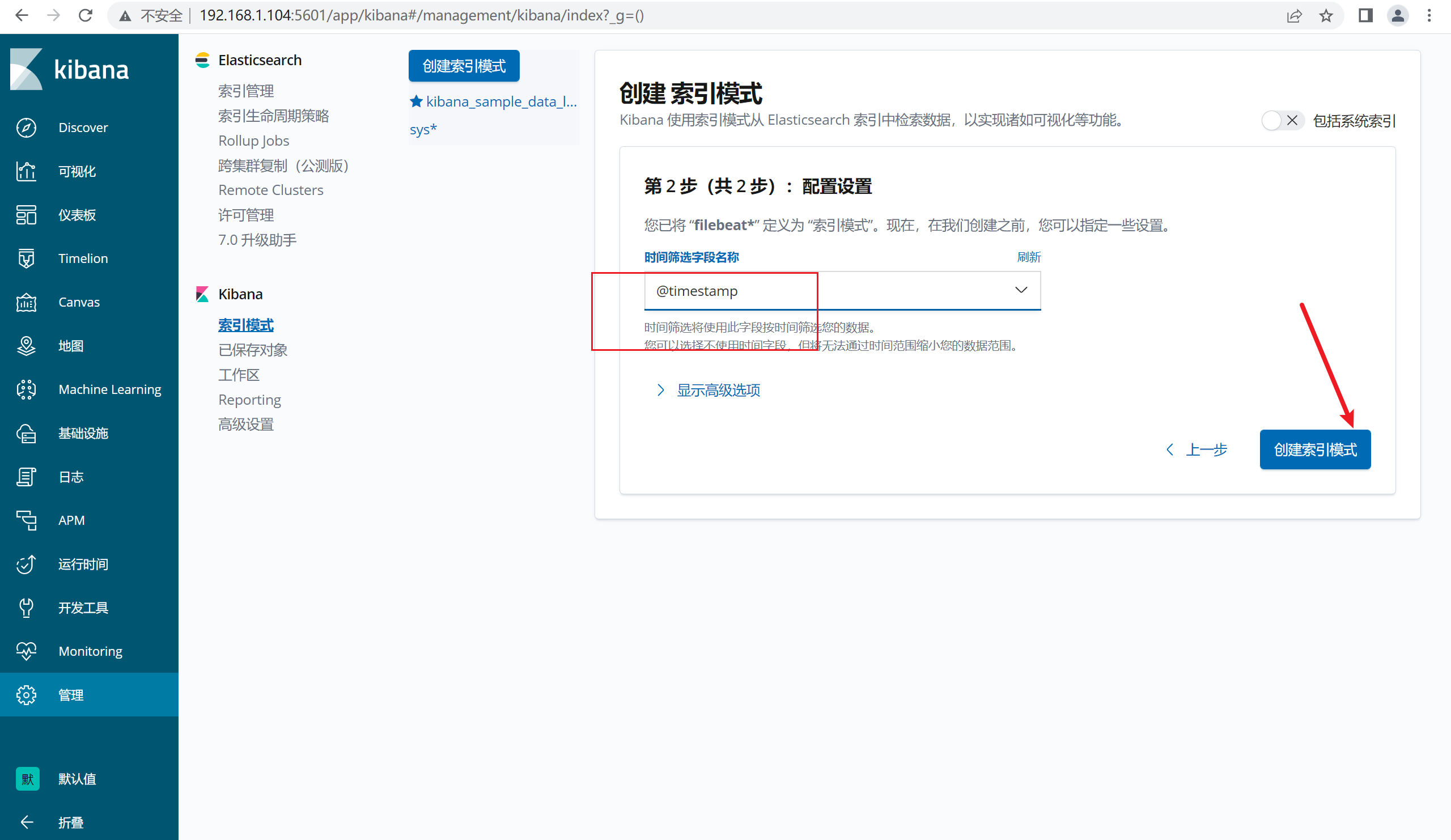
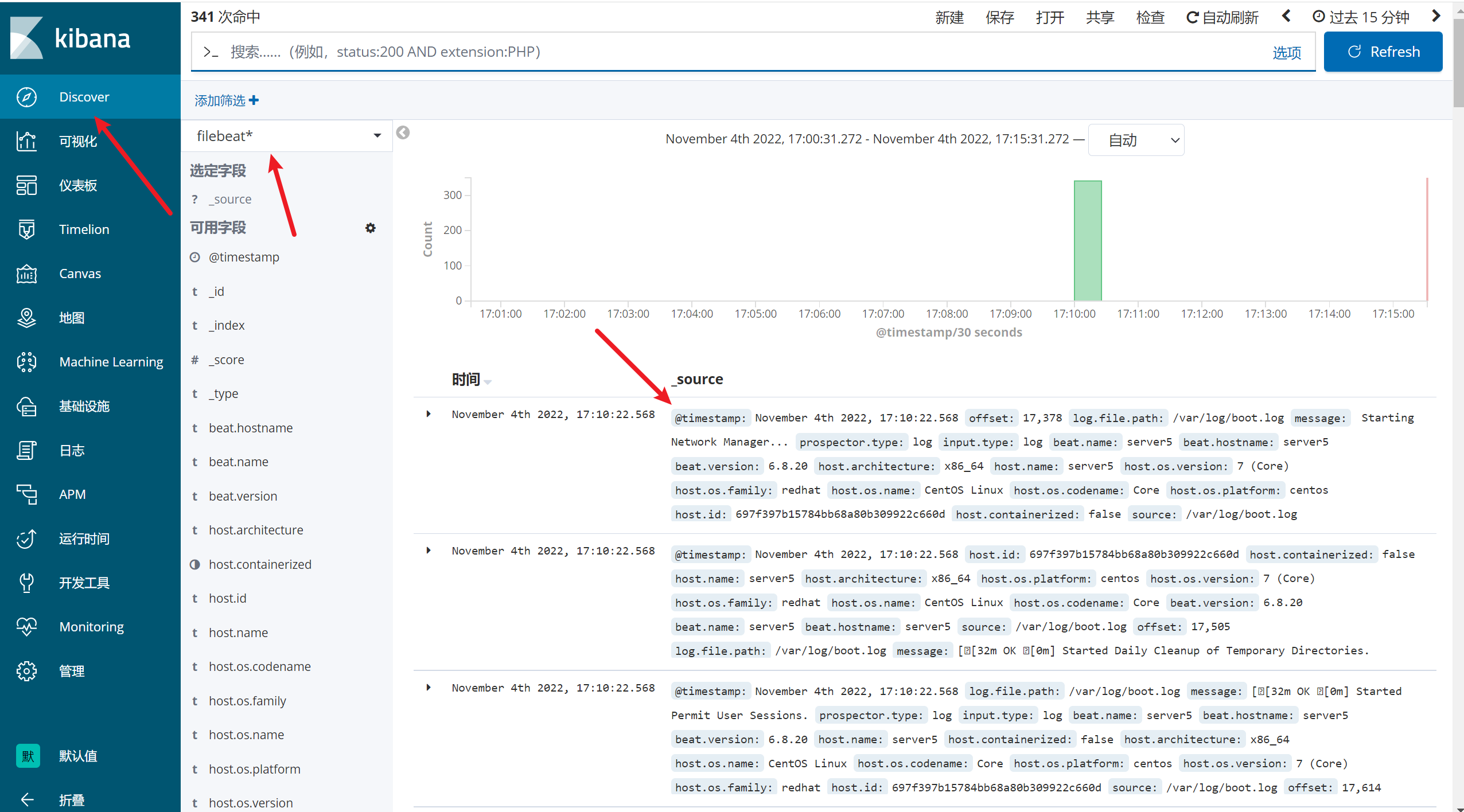
三、实战1: 收集客户端的apache的日志
收集192.168.1.108这台主机上的apache的日志
3.1 方法1:使用logstash来收集
3.1.1 安装logstash
[root@web02 conf.d]# source /etc/profile
[root@web02 conf.d]# java -version
java version "1.8.0_311"
Java(TM) SE Runtime Environment (build 1.8.0_311-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.311-b11, mixed mode)
[root@web02 conf.d]#
3.1.2 解压logstash
tar zxvf logstash-6.8.20.tar.gz -C /usr/local/src/
注意:logstash解压就可以使用。
3.1.3 安装http
yum -y install httpd
3.1.4 在conf.d新建一个elk.conf的文件,用于定义我们的配置
input {
file {
path => "/var/log/messages" ##定义系统日志信息
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/httpd/access_log" ##定义apache的日志信息
type => "httpd"
start_position => "beginning"
}
}
output {
if [type] == "system" {
elasticsearch {
hosts => ["192.168.1.101:9200"] ##日志格式
index => "system-%{+YYYY.MM.dd}"
}
}
if [type] == "httpd" {
elasticsearch {
hosts => ["192.168.1.101:9200"]
index => "httpd-%{+YYYY.MM.dd}"
}
}
}
3.1.5 启动Logstash
[root@web02 bin]# ./logstash -f /usr/local/src/logstash/conf.d/elk.conf
启动后,我们可以将其放置在后台运行:
[root@web02 bin]# ./logstash -f /usr/local/src/logstash/conf.d/elk.conf
Sending Logstash logs to /usr/local/src/logstash/logs which is now configured via log4j2.properties
[2021-11-10T22:40:56,542][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-11-10T22:40:56,554][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.8.20"}
[2021-11-10T22:41:00,925][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2021-11-10T22:41:01,271][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://192.168.1.101:9200/]}}
[2021-11-10T22:41:01,446][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.1.101:9200/"}
[2021-11-10T22:41:01,494][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>6}
[2021-11-10T22:41:01,497][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2021-11-10T22:41:01,525][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//192.168.1.101:9200"]}
[2021-11-10T22:41:01,541][INFO ][logstash.outputs.elasticsearch] Using default mapping template
[2021-11-10T22:41:01,548][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://192.168.1.101:9200/]}}
[2021-11-10T22:41:01,559][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.1.101:9200/"}
[2021-11-10T22:41:01,567][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2021-11-10T22:41:01,569][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>6}
[2021-11-10T22:41:01,569][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2021-11-10T22:41:01,574][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//192.168.1.101:9200"]}
[2021-11-10T22:41:01,582][INFO ][logstash.outputs.elasticsearch] Using default mapping template
[2021-11-10T22:41:01,594][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2021-11-10T22:41:01,806][INFO ][logstash.inputs.file ] No sincedb_path set, generating one based on the "path" setting {:sincedb_path=>"/usr/local/src/logstash/data/plugins/inputs/file/.sincedb_452905a167cf4509fd08acb964fdb20c", :path=>["/var/log/messages"]}
[2021-11-10T22:41:01,847][INFO ][logstash.inputs.file ] No sincedb_path set, generating one based on the "path" setting {:sincedb_path=>"/usr/local/src/logstash/data/plugins/inputs/file/.sincedb_15940cad53dd1d99808eeaecd6f6ad3f", :path=>["/var/log/httpd/access_log"]}
[2021-11-10T22:41:01,873][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x5e9ad084 run>"}
[2021-11-10T22:41:01,941][INFO ][filewatch.observingtail ] START, creating Discoverer, Watch with file and sincedb collections
[2021-11-10T22:41:01,944][INFO ][filewatch.observingtail ] START, creating Discoverer, Watch with file and sincedb collections
[2021-11-10T22:41:02,011][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2021-11-10T22:41:02,314][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
3.1.6 查看es
3.1.7 在kibana中新建索引
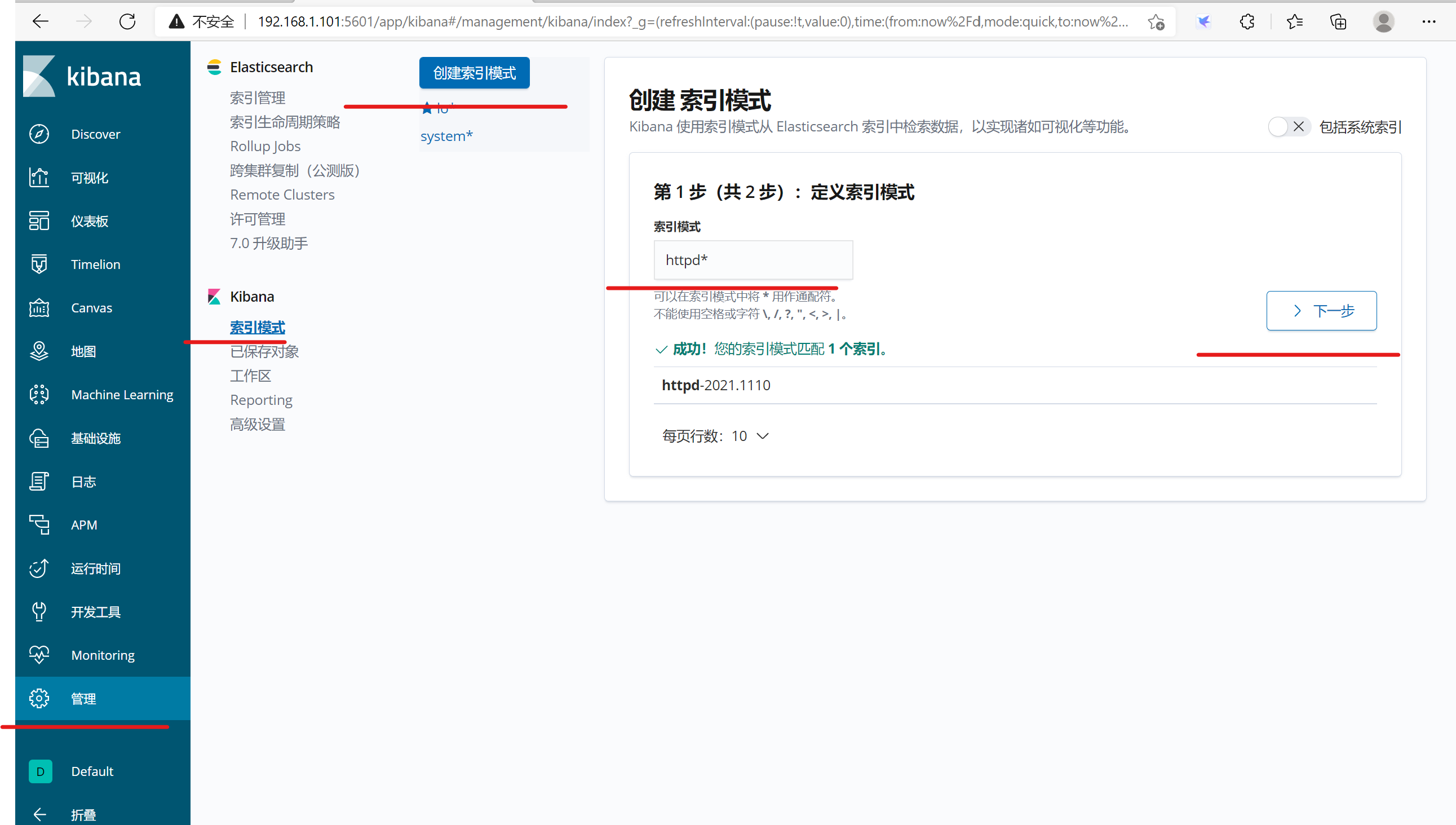
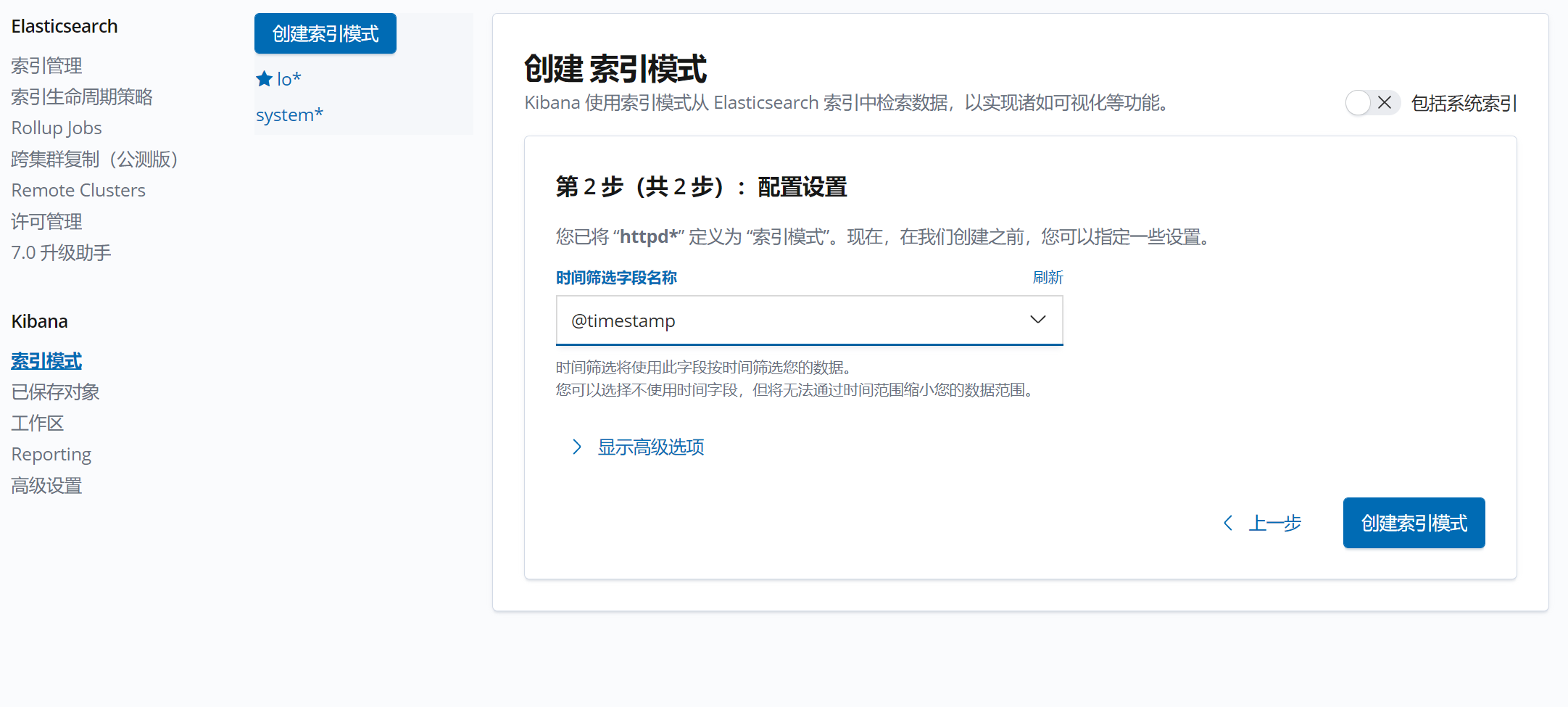
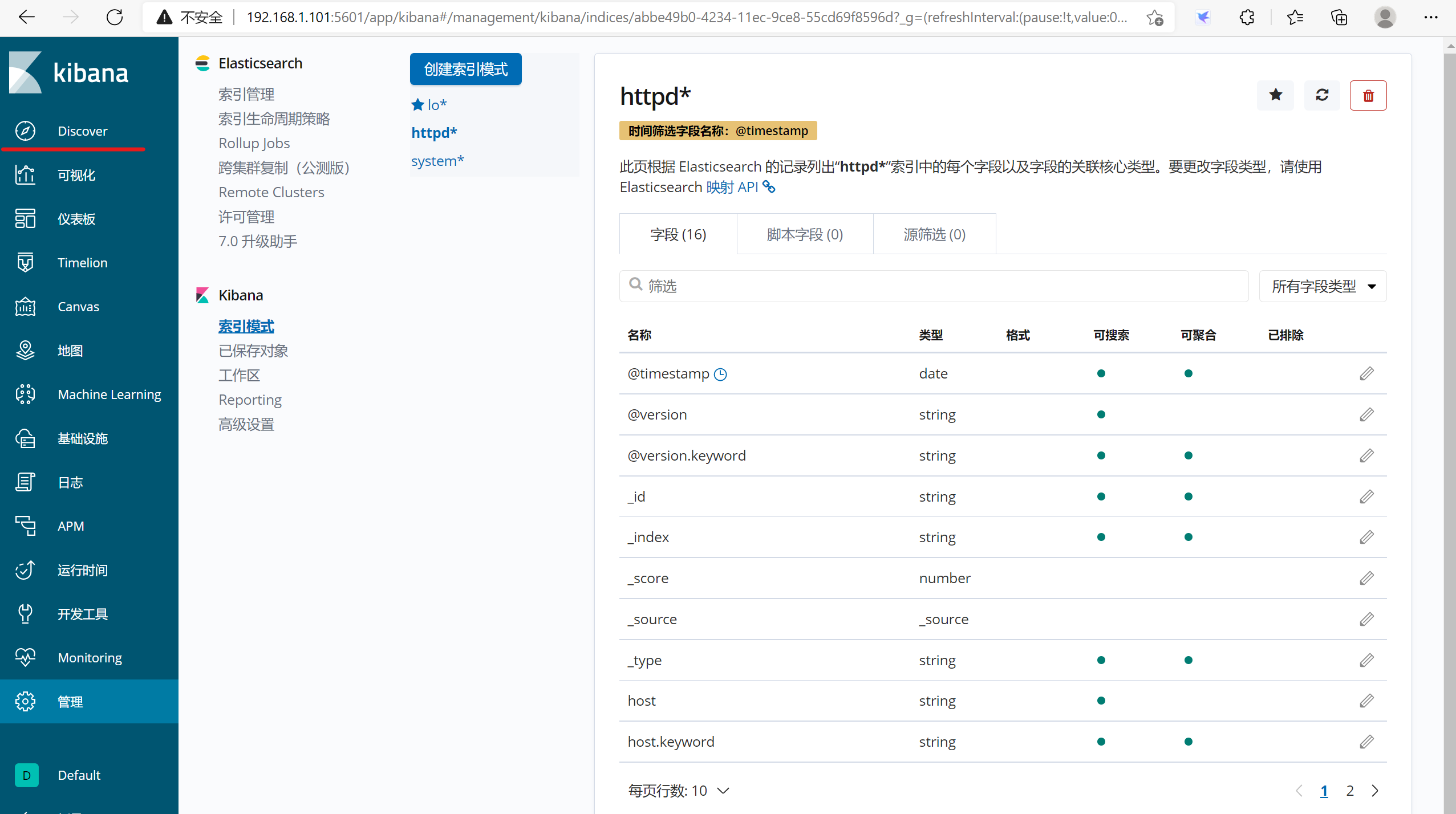
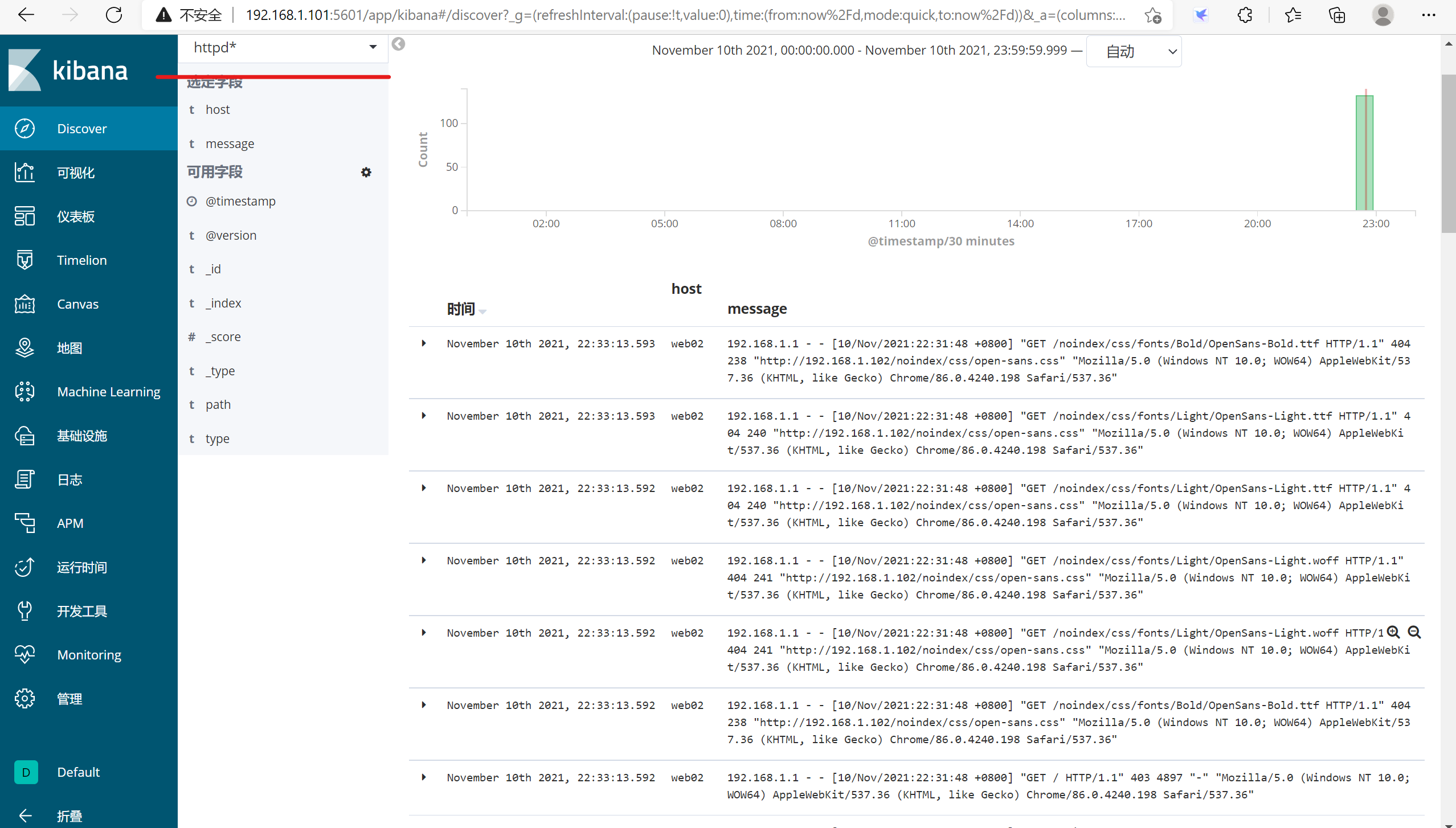
3.2 方法2:使用filebeat收集
3.2.1 安装http
yum -y install httpd
3.2.2 启动服务
systemctl enable --now httpd
3.2.3 编辑filebeat配置文件
在paths中加入http的新的日志文件路径

3.2.4 启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
3.2.5 查看kibana
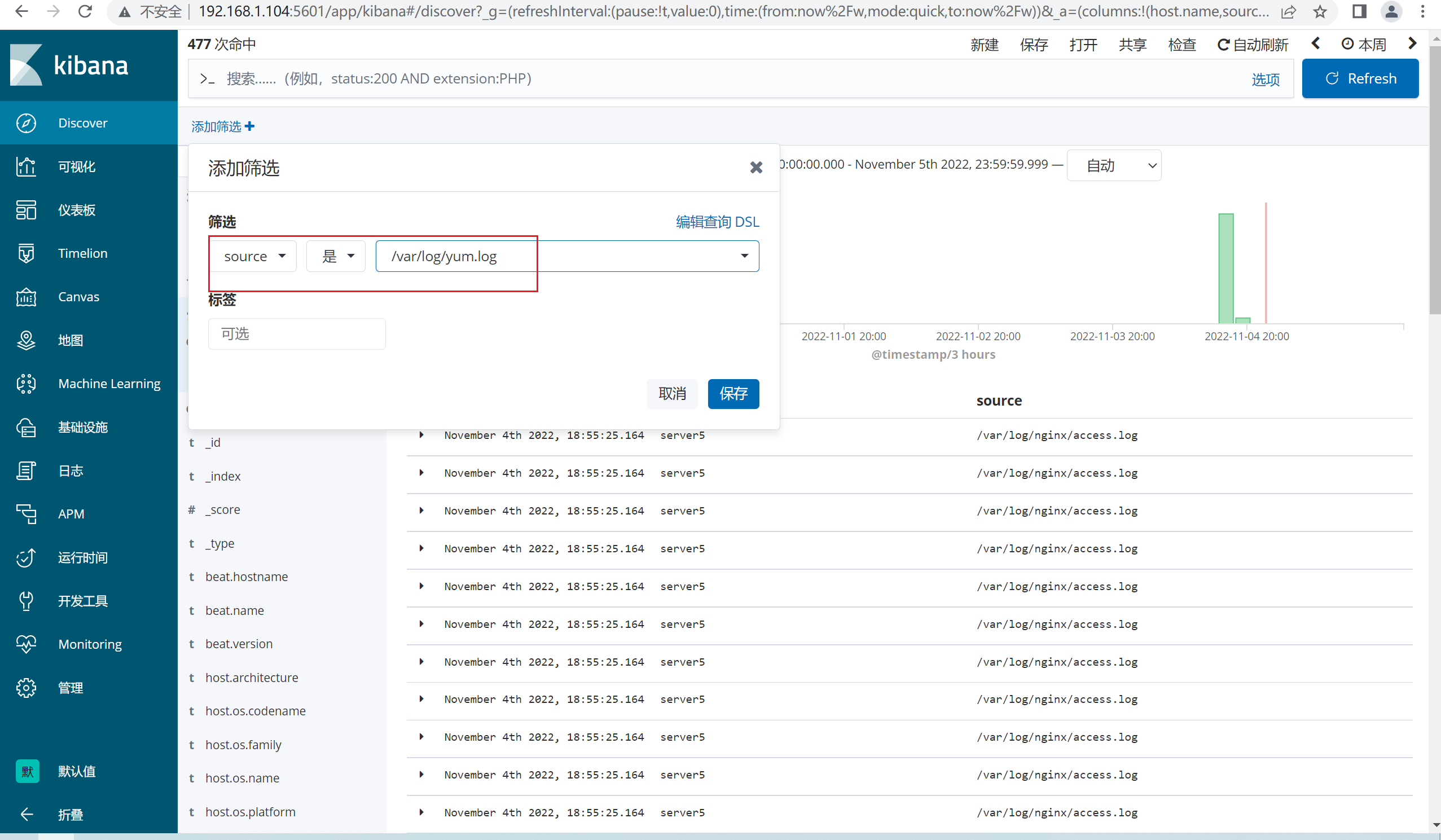
由于日志和其他的*.log混杂在一起,因此kibana查看的时候,新建一个筛选器,过滤http的日志即可
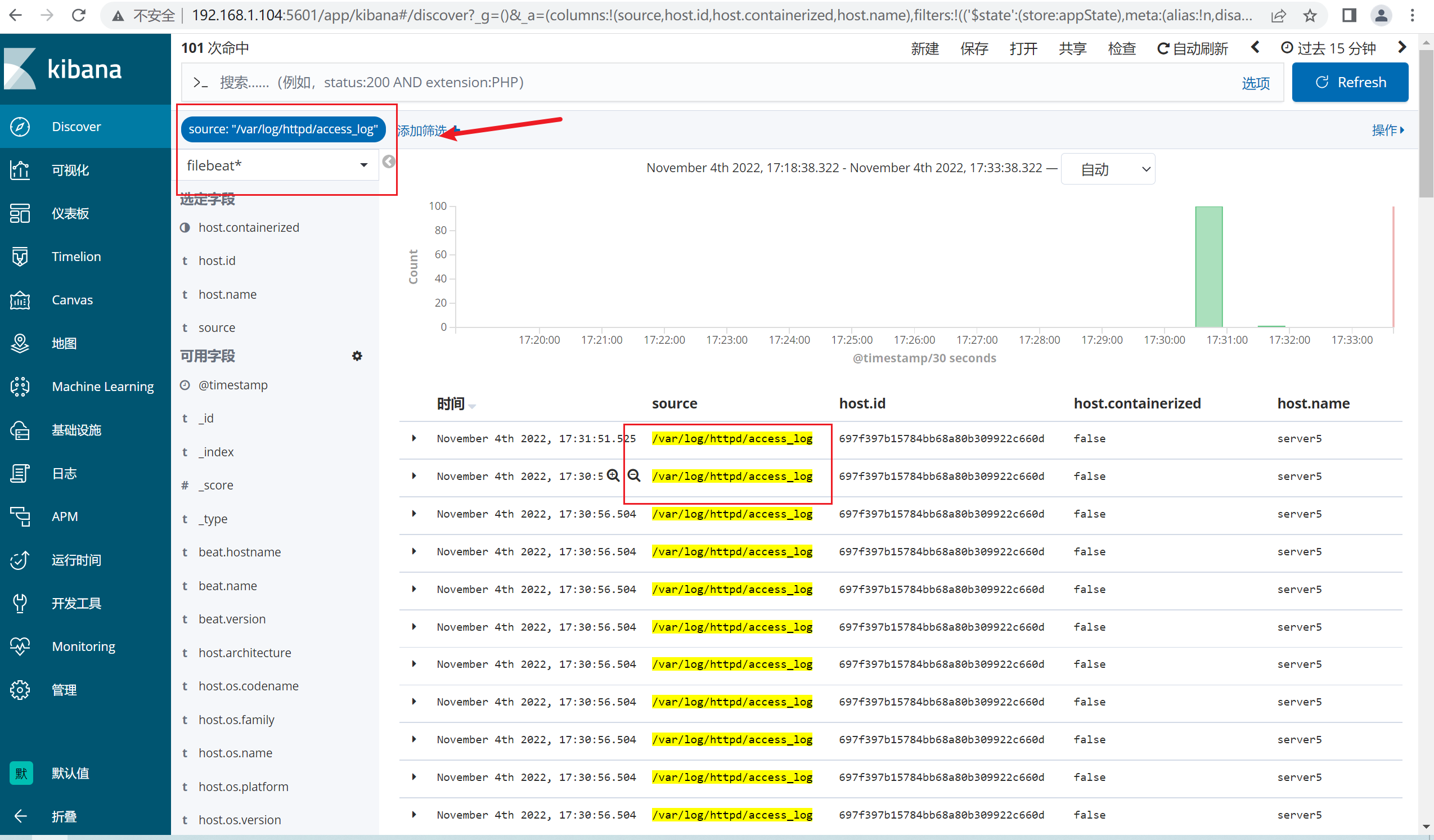
四、实战2:收集nginx的日志
工作中,我们也也可以使用logstash来收集nginx的日志信息,以便于我们进行集中式管理。
4.1 方法1:使用logstash来收集
4.1.1 安装nginx服务
yum -y install epel-release
yum -y install nginx
4.1.2 配置Nginx的日志格式
注意:将nginx日志转换为json格式,语法如下:
http {
# log_format main '$remote_addr - $remote_user [$time_local] "$request" ' #将原有的日志格式注释
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log /var/log/nginx/access.log main;
log_format access_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"status":"$status"}';
access_log /var/log/nginx/access.log access_json;
4.1.3 重启nginx
[root@web02 nginx]# systemctl restart nginx
4.1.4 查看访问日志
[root@localhost nginx]# tail access.log
{"@timestamp":"2022-08-21T14:38:27+08:00","host":"192.168.1.101","client":"192.168.1.1","size":5,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.1.101","url":"/index.html","domain":"192.168.1.101","xff":"-","referer":"-","status":"200"}
{"@timestamp":"2022-08-21T14:38:27+08:00","host":"192.168.1.101","client":"192.168.1.1","size":555,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.1.101","url":"/404.html","domain":"192.168.1.101","xff":"-","referer":"http://192.168.1.101/","status":"404"}
json在线校验工具
https://www.sojson.com/
{
"@timestamp": "2022-08-21T14:38:27+08:00",
"host": "192.168.1.101",
"client": "192.168.1.1",
"size": 5,
"responsetime": 0.000,
"upstreamtime": "-",
"upstreamhost": "-",
"http_host": "192.168.1.101",
"url": "/index.html",
"domain": "192.168.1.101",
"xff": "-",
"referer": "-",
"status": "200"
}
4.1.5 配置logstash
在logstash中新建配置文件elk2.conf
input {
file { #定义日志收集的位置
type => "nginx"
path => "/var/log/nginx/access.log"
start_position => "beginning"
stat_interval => "2"
codec => "json" #表示日志格式是json格式的
}
}
output { #定义日志输出的位置
if [type] == "nginx" {
elasticsearch {
hosts => ["192.168.1.101:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
}
4.1.6 重新运行logstash
[root@web02 bin]# ./logstash -f /usr/local/src/logstash/conf.d/elk2.conf
Sending Logstash logs to /usr/local/src/logstash/logs which is now configured via log4j2.properties
[2021-11-11T17:30:39,889][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2021-11-11T17:30:39,899][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.8.20"}
[2021-11-11T17:30:44,119][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2021-11-11T17:30:44,456][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://192.168.1.101:9200/]}}
[2021-11-11T17:30:44,625][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://192.168.1.101:9200/"}
[2021-11-11T17:30:44,670][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>6}
[2021-11-11T17:30:44,674][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2021-11-11T17:30:44,706][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//192.168.1.101:9200"]}
[2021-11-11T17:30:44,724][INFO ][logstash.outputs.elasticsearch] Using default mapping template
[2021-11-11T17:30:44,749][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2021-11-11T17:30:44,955][INFO ][logstash.inputs.file ] No sincedb_path set, generating one based on the "path" setting {:sincedb_path=>"/usr/local/src/logstash/data/plugins/inputs/file/.sincedb_d883144359d3b4f516b37dba51fab2a2", :path=>["/var/log/nginx/access.log"]}
[2021-11-11T17:30:44,997][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x6b8cf562 run>"}
[2021-11-11T17:30:45,053][INFO ][filewatch.observingtail ] START, creating Discoverer, Watch with file and sincedb collections
[2021-11-11T17:30:45,058][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2021-11-11T17:30:45,323][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
4.1.7 查看es中和kibana中是否有nginx开头的索引了。
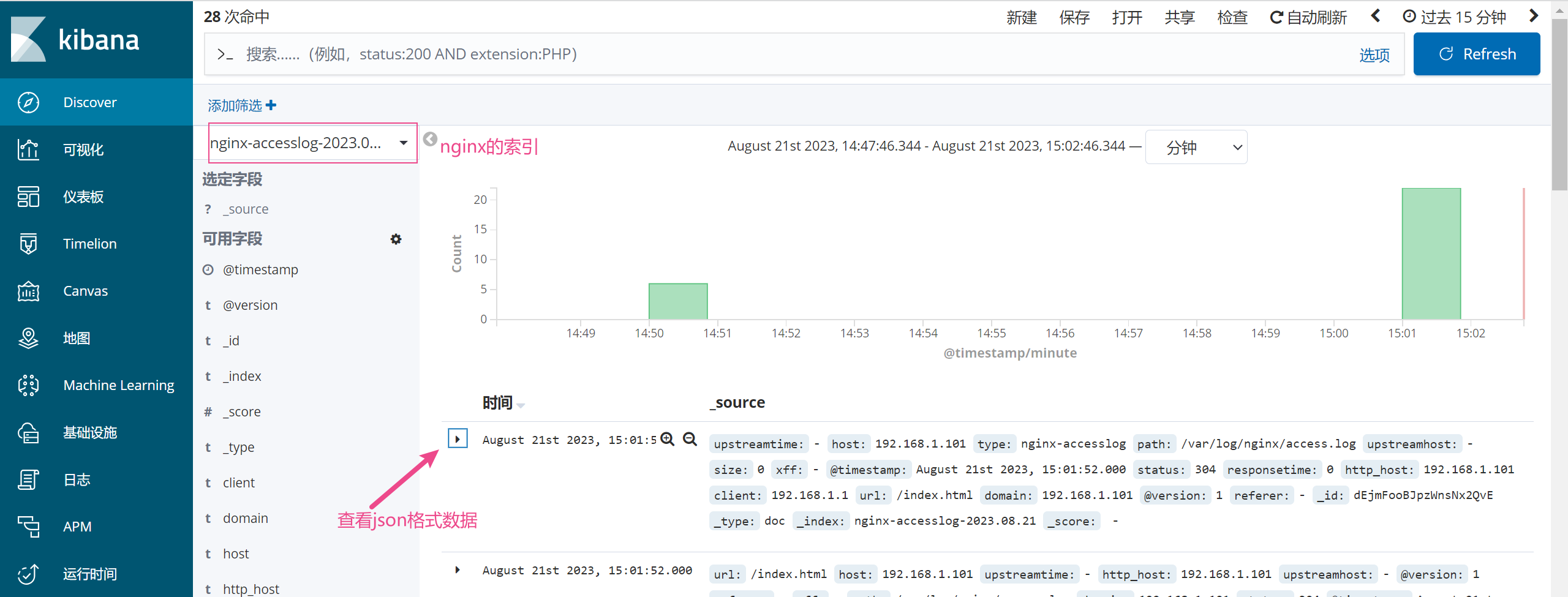
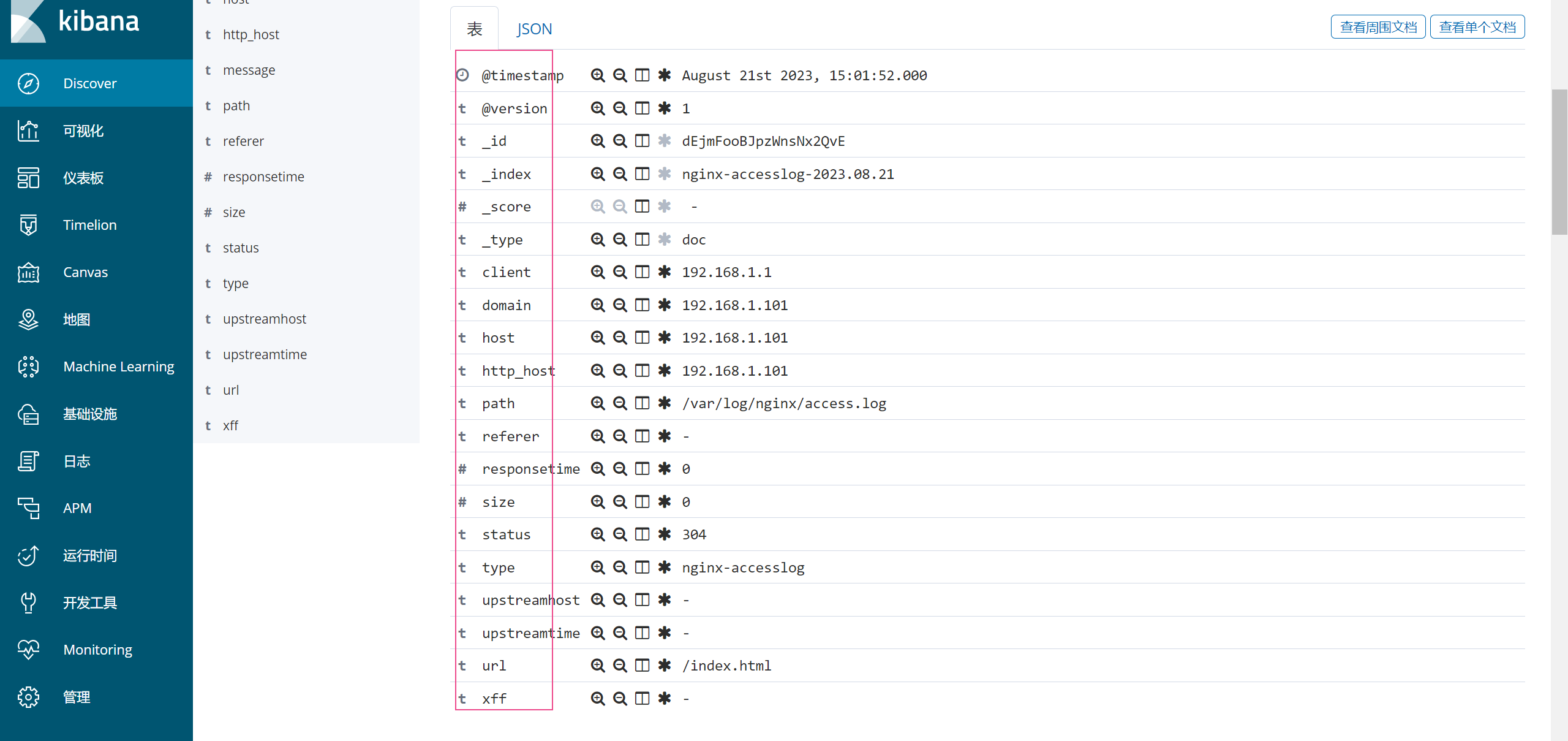
4.2 方法2:使用filebeat来收集
4.2.1 安装nginx
yum -y install epel-release
yum -y install nginx
4.2.2 启动nginx
[root@server5 ~]# systemctl enable --now nginx
4.2.3 配置filebeat收集nginx日志
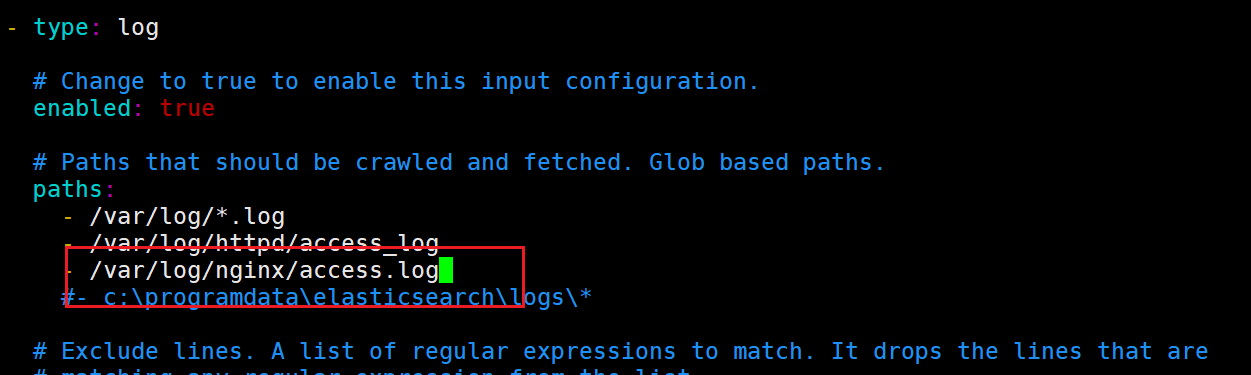
4.2.3 启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
4.2.4 查看kibana
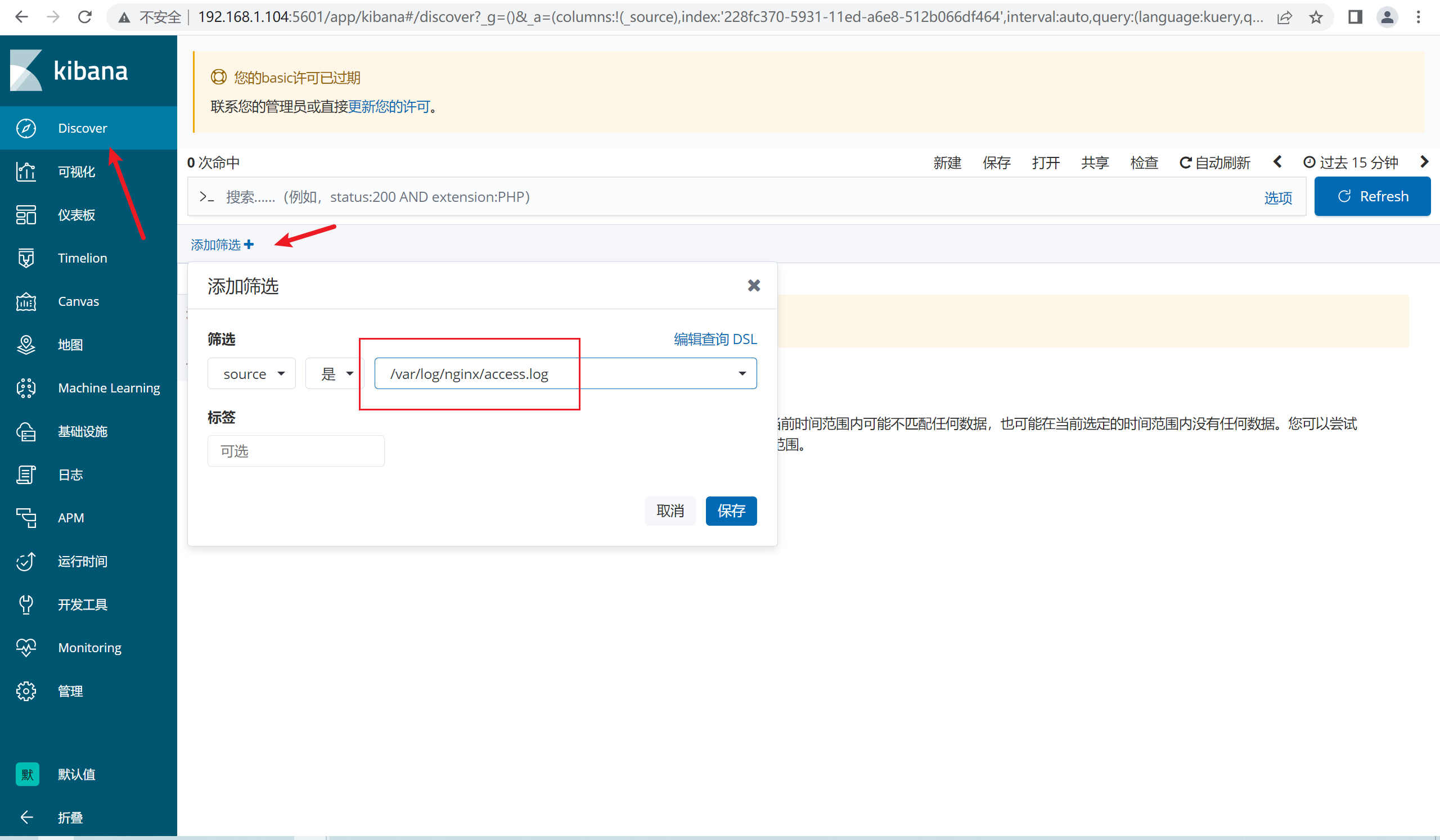
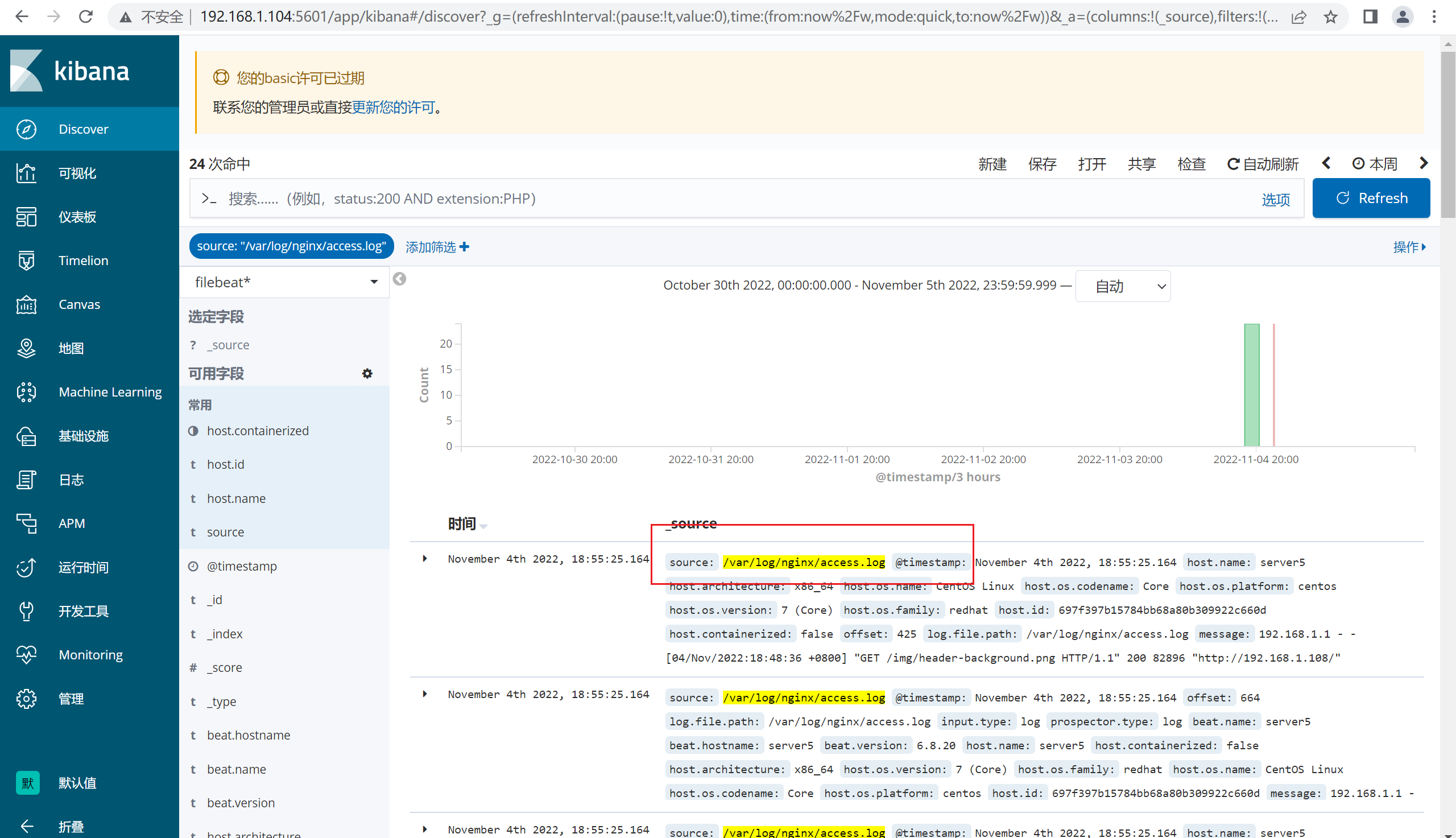
4.3 filebeat中的日志过滤功能
filebeat.yml示例:
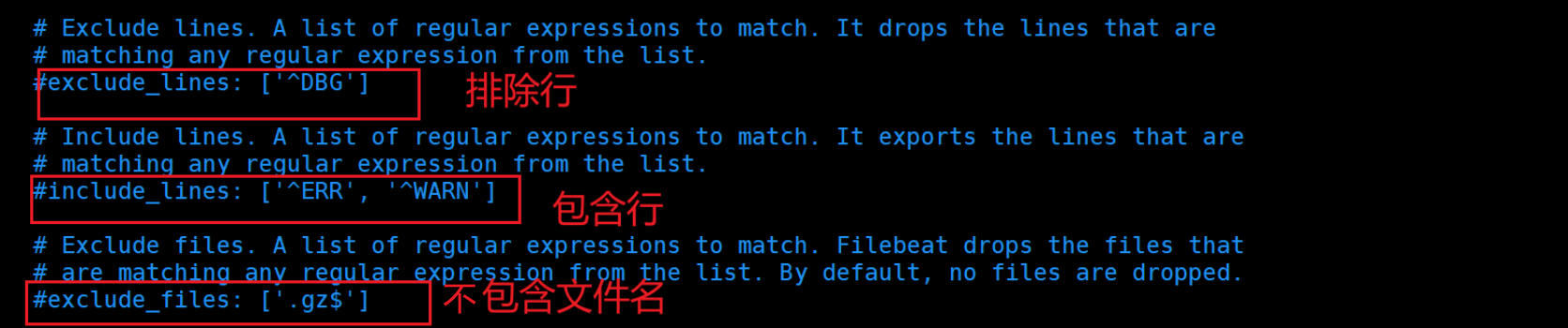
根据上述的语法,我们自定义一个配置
4.3.1 定义过滤规则
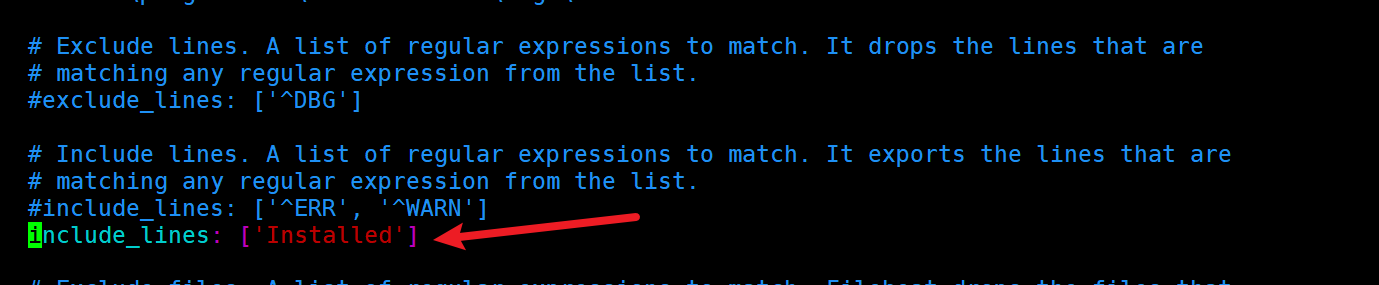
4.3.2 启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
4.3.3 查看kibana的数据
五、logstash插件
5.1 logstash的输入插件
官方文档:https://www.elastic.co/guide/en/logstash/6.8/input-plugins.html
stdin
file
tcp
udp
Beats
redis
......
5.1.1 tcp插件
1)tcp:即通过TCP套接字来读取实践,即接收收集,与标准输入和文件输入一致,每个事件都会被定为成一行文本内容,也可以转换成json数据
[root@logstash conf.d]# cat tcp.elk
input {
tcp {
port => 4567
type => "tcp"
}
}
filter {
}
output {
stdout {
codec => "rubydebug"
}
}
启动logstash
[root@logstash bin]# ./logstash -f /usr/local/src/logstash/conf.d/tcp.elk
查看监听的端口
[root@logstash bin]# netstat -antup|grep 4567
tcp6 0 0 :::4567 :::* LISTEN 21899/java
通过在其他的机器上通过nc工具,模拟启动4567端口,通过网络的方式收集事件信息
[root@elasticearch-2 ~]# yum -y install nc

查看Logstash

除此之外,还可以将文件的内容通过TCP网络传输进logstash
[root@es2 ~]# nc 192.168.1.101 4567 < /etc/passwd
运行logstash
[root@logstash bin]# ./logstash -f /usr/local/logstash/conf.d/tcp.conf
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
[2023-08-22T16:46:13,361][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2023-08-22T16:46:13,377][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.8.20"}
[2023-08-22T16:46:20,768][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2023-08-22T16:46:21,029][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#<Thread:0x396aca34 run>"}
[2023-08-22T16:46:21,039][INFO ][logstash.inputs.tcp ] Starting tcp input listener {:address=>"0.0.0.0:456", :ssl_enable=>"false"}
[2023-08-22T16:46:21,075][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2023-08-22T16:46:21,310][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
/usr/local/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"type" => "tcp",
"message" => "test",
"@timestamp" => 2023-08-22T08:47:38.234Z,
"@version" => "1",
"host" => "192.168.1.103",
"port" => 48716
}
{
"type" => "tcp",
"message" => "sync:x:5:0:sync:/sbin:/bin/sync",
"@timestamp" => 2023-08-22T08:49:34.269Z,
"@version" => "1",
"host" => "192.168.1.103",
"port" => 48718
}
将日志写入到elasticsearch中
input {
tcp {
port => "4567"
type => "tcp"
}
}
output {
elasticsearch {
hosts => ["192.168.1.100:9200"]
index => "tcp-%{+YYYY.MM.dd}"
}
}
完成后,运行logstash,查看ES的索引数据
[root@logstash bin]# ./logstash -f /usr/local/logstash/conf.d/tcp.conf
5.1.2 json插件
通过nc工具传输nginx日志数据,并进行过滤
示例1:
模拟json的数据格式:
{"ip":"192.168.1.106","hostname":"nginx","path":"/var/log/nginx/access/log"}
使用nc工具将数据传递到logstash服务器上观察数据的表示格式
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
{"ip":"192.168.1.106","hostname":"nginx","path":"/var/log/nginx/access/log"}
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"message" => " {\"ip\":\"192.168.1.106\",\"hostname\":\"nginx\",\"path\":\"/var/log/nginx/access/log\"}",
"host" => "192.168.1.106",
"port" => 57494,
"@version" => "1",
"@timestamp" => 2022-11-02T22:44:06.060Z
}
##发现数据的格式是不对的,出现了很多的\。
修改logstash的过滤机制(在原有的配置上加上json配置)
[root@logstash conf.d]# cat tcp.elk
input {
tcp {
port => 4567
type => "tcp"
}
}
filter {
json {
source => "message"
target => "content" ##可以省略
}
}
output {
stdout {
}
}
[root@logstash conf.d]#
重新在启动logstash,在nc上重新传输数据。
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"@version" => "1",
"@timestamp" => 2022-11-02T22:49:19.266Z,
"host" => "192.168.1.106",
"port" => 57496,
"content" => {
"path" => "/var/log/nginx/access/log",
"ip" => "192.168.1.106",
"hostname" => "nginx"
},
"message" => "{\"ip\":\"192.168.1.106\",\"hostname\":\"nginx\",\"path\":\"/var/log/nginx/access/log\"}"
示例2:将大段转换成小段
[root@logstash conf.d]# vim tcp.elk
[root@logstash conf.d]# cat tcp.elk
input {
tcp {
port => 4567
}
}
filter {
json {
source => "message"
}
}
output {
stdout {
}
}
[root@logstash conf.d]#
"@timestamp" => 2022-11-02T23:15:02.410Z,
"path" => "/var/log/nginx/access/log",
"host" => "192.168.1.106",
"port" => 57506,
"ip" => "192.168.1.106",
"@version" => "1",
"message" => "{\"ip\":\"192.168.1.106\", \"hostname\":\"nginx\", \"path\":\"/var/log/nginx/access/log\"}",
"hostname" => "nginx"
}
好处就是当我们需要统计uv的时候,可以通过IP地址来进行统计。
5.1.3 k-v插件
可以自动将数据解析成key:value的数据类型,有时候我们的日志数据也有可能是如下的格式:
url=www.baidu.com?pid=user&passwd=123456
这种格式在logstash中并不会帮我们进行转换处理,如下:

发现json无法将这种类型的日志转换
[root@logstash conf.d]# cat tcp.elk
input {
tcp {
port => 4567
}
}
filter {
kv {
field_split => "?&" #指定分隔符
}
}
output {
stdout {
}
}
[root@logstash conf.d]#
重新启动logstash测试
输入:
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
url=www.baidu.com?pid=user&passwd=123456
输出:
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"message" => "url=www.baidu.com?pid=user&passwd=123456",
"host" => "192.168.1.106",
"port" => 57508,
"passwd" => "123456",
"@version" => "1",
"@timestamp" => 2022-11-03T00:56:09.931Z,
"pid" => "user",
"url" => "www.baidu.com"
}
可以看到已经成功的进行了切割了。
5.1.4 grok插件
用于将非结构化数据解析为结构化和可查询的数据。即将一个key对应的一长串非结构化的value,转成多个结构化的key-value。
示例:非结构化数据
192.168.1.1 - - [04/Nov/2022:18:48:36 +0800] "GET / HTTP/1.1" 200 4833 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
从数据分析的角度:非结构化数据不便于检索、统计、分析。
非结构化数据变成结构化数据后才有检索、统计、分析的价值。
grok正则主要有两部分:
1、grok的默认表达式。grok预定义好的一些表达式,可以匹配常见的字符串。
官方文档:https://www.elastic.co/guide/en/logstash/6.8/plugins-filters-grok.html
默认表达式路径:
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/pattern
grok模式的语法:%{SYNTAX:SEMANTIC}
SYNTAX代表匹配值类型,SEMANTIC代表赋值字段名称。
例如:127.0.0.0:9200可以使用IP类型匹配,%{IP:client}
age是24,可以用NUMBER类型匹配,%{NUMBER:age}
默认情况下,所有语义都保存为字符串,希望转换语义的数据类型,例如将字符串更改为整数,则将其后缀为目标数据类型。例如:%{NUMBER:age:int},将age语义从一个字符串转换为一个整数。
示例:通过grop来匹配nginx的日志
使用grok pattern从日志中抽出有用的字段:
%{IP:client}%{WORD:method}%{URIPATHPARAM:request}%{NUMBER:bytes}%{NUMBER:duration}
在logstash中添加过滤器配置
[root@logstash conf.d]# cat tcp.elk
input {
tcp {
port => 4567
}
}
filter {
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
}
output {
stdout { codec => rubydebug}
}
----------
输入:
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
127.0.0.1 GET /index.html 5000 0.2 ##输入的内容
输出:
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"request" => "/index.html",
"bytes" => "5000",
"duration" => "0.2",
"client" => "127.0.0.1",
"host" => "192.168.1.106",
"port" => 57510,
"method" => "GET",
"message" => "127.0.0.1 GET /index.html 5000 0.2",
"@version" => "1",
"@timestamp" => 2022-11-03T01:41:08.195Z
}
2、自定义grok表达式
如果默认模式中没有匹配项,可以自定义匹配项
[root@logstash conf.d]# cat /opt/patterns
ID [0-9]{3,5}
编写logstash过滤项
input {
tcp {
port => 4567
}
}
filter {
grok {
patterns_dir => '/opt/patterns'
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} %{ID:id}"}
}
}
output {
stdout { codec => rubydebug}
}
##重新启动logstash
----------------------
输入:
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
127.0.0.1 GET /index.html 5000 0.2 445566 ##其他的机器上的测试输入信息
输出:
/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/awesome_print-1.7.0/lib/awesome_print/formatters/base_formatter.rb:31: warning: constant ::Fixnum is deprecated
{
"id" => "44556",
"method" => "GET",
"request" => "/index.html",
"@version" => "1",
"bytes" => "5000",
"port" => 57522,
"client" => "127.0.0.1",
"duration" => "0.2",
"host" => "192.168.1.106",
"message" => "127.0.0.1 GET /index.html 5000 0.2 445566",
"@timestamp" => 2022-11-03T02:08:00.484Z
}
5.1.5 geoip插件
Geo是geographic的缩写,意思是地理的,GeoIP即为IP地理位置数据库,可以根据IP获得地理位置信息。GeoLite2是GeoIP2的免费版本,与GeoIP2数据库相比准确性较差。GeoLite2数据库每周更新国家、城市和自治系统编号信息,更新时间为每周二。 IP地理定位本质上是不精确的,地点通常靠近人口中心。GeoIP数据库提供的任何位置不应用于识别特定地址或家庭,使用精度半径作为IP地址返回的纬度和经度坐标的地理定位精度指示,IP地址的实际位置可能在这个半径和经纬度坐标所定义的区域内。
GeoIP库可以根据IP地址(支持IPv4 和 IPv6), 定位该IP所在的 洲、经纬度、国家、省市、ASN 等信息。
GeoIP目前已经升级到GeoIP2,GeoIP2有两个版本,一个免费版(GeoLite2),一个收费版本(GeoIP2, 200$起步)。
收费版本的准确率稍高一些,更新频率为每周二更新一次, 免费版是每月第一个周二更新一次。
在对Logstash的实际应用中,为了从日志中ip获取到用户访问时的所在地,用到了geoip这个模块。在logstash下/usr/local/src/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-filter-geoip-5.0.3-java/vendor的位置下,在这个文件夹下有一个名为GeoLite2-City.mmdb的文件,这个就是geoip使用的数据源了,这个数据源是由Maxmind这家公司提供的
下载地址:https://support.maxmind.com/hc/en-us/articles/4408216129947-Download-and-Update-Databases#h_01FM56FTVAWJQK3XBQVAJGWY66 ---需要登录
但是由于网络下载限制的问题,因此可能存在下载失败的问题,因此可以下载更高版本的logstash,然后从其中获取更高版本的geoip的数据库版本。
input{
tcp { port => 4567 }
}
filter{
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
geoip{
source => "client"
database => "/opt/GeoLite2-City.mmdb"
}
}
output{
stdout { codec => rubydebug}
}
##重新启动logstash
----------------
输入:
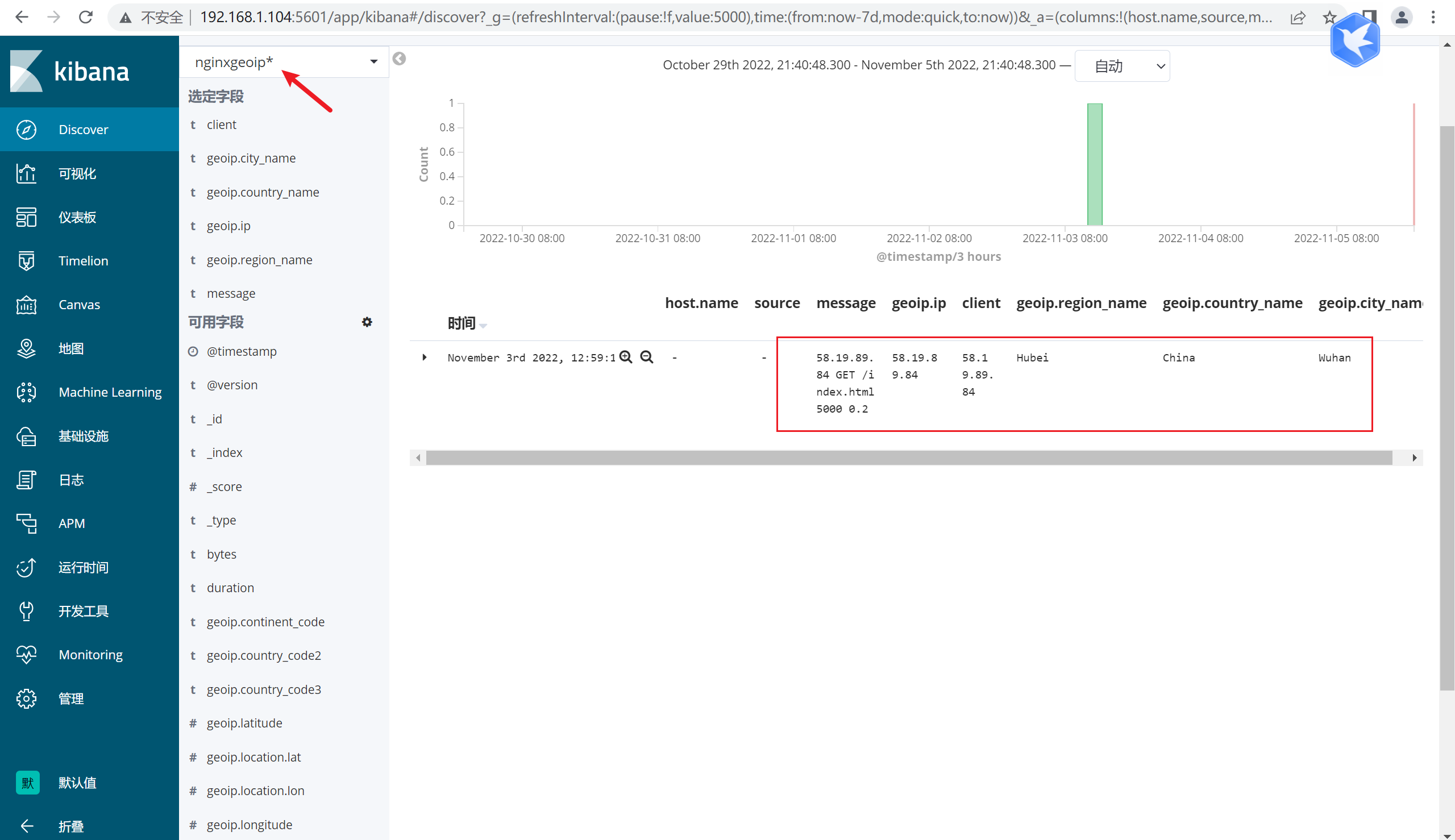
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
58.19.89.84 GET /index.html 5000 0.2
输出:
{
"host" => "192.168.1.106",
"client" => "58.19.89.84",
"bytes" => "5000",
"@timestamp" => 2022-11-03T04:51:00.876Z,
"request" => "/index.html",
"method" => "GET",
"duration" => "0.2",
"port" => 57528,
"@version" => "1",
"geoip" => {
"latitude" => 30.5856,
"region_name" => "Hubei",
"ip" => "58.19.89.84",
"country_code3" => "CN",
"city_name" => "Wuhan",
"country_name" => "China",
"country_code2" => "CN",
"location" => {
"lon" => 114.2665,
"lat" => 30.5856
},
"continent_code" => "AS",
"longitude" => 114.2665,
"region_code" => "HB",
"timezone" => "Asia/Shanghai"
},
"message" => "58.19.89.84 GET /index.html 5000 0.2"
}
5.2 logstash输出插件
官方文档:https://www.elastic.co/guide/en/logstash/6.8/output-plugins.html
ES
stdout
redis
kafka
file
rabbitmq
syslog
tcp
udp
zabbix
......
5.2.1 示例:结合geoip将日志信息导入到ES中
1)新建logstash的过滤文件
input {
tcp { port => 4567 }
}
filter{
grok {
match => {"message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
}
geoip{
source => "client"
database => "/opt/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["192.168.1.100:9200"]
index => "nginxgeoip-%{+YYYY.MM.dd}"
}
}
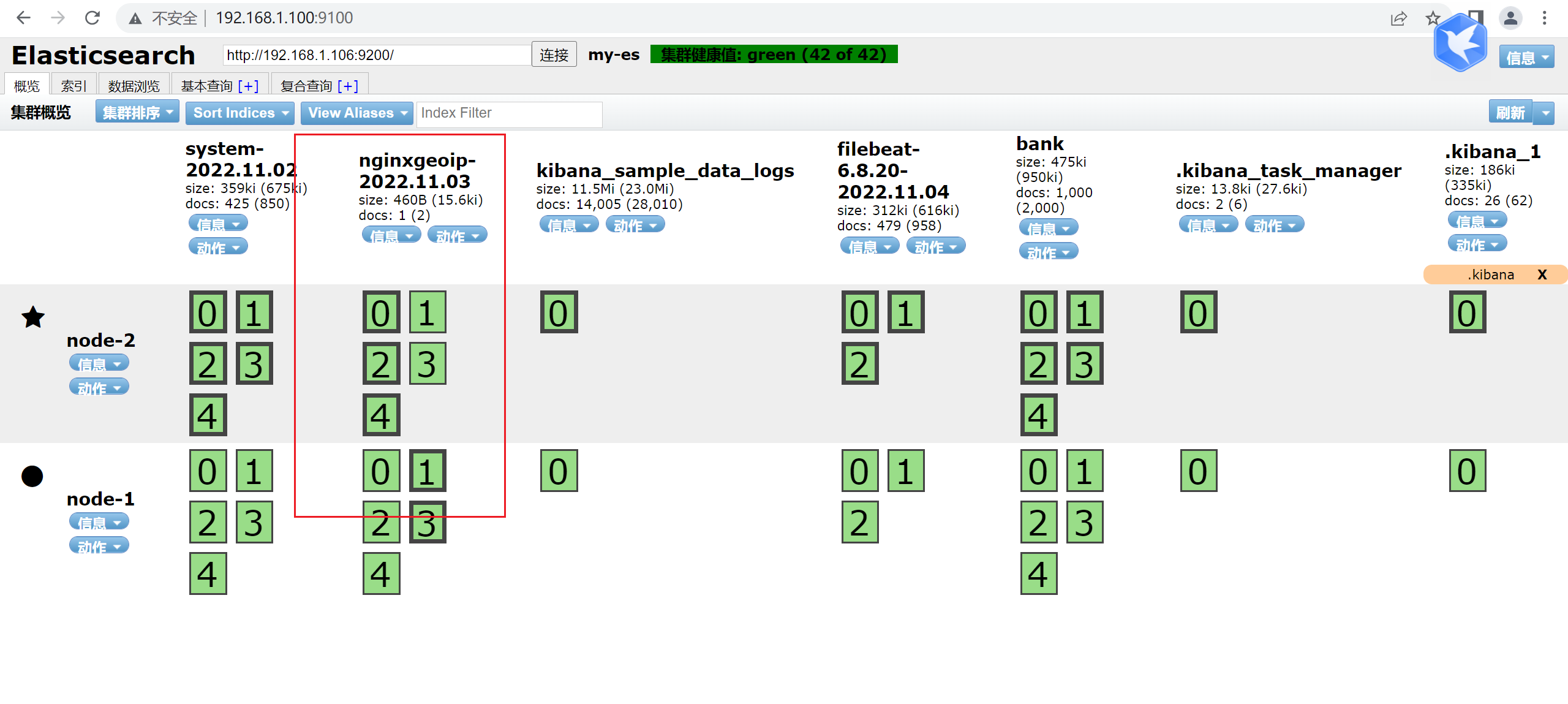
2)启动logstash
[root@logstash bin]# ./logstash -f /usr/local/src/logstash/conf.d/nginxgeoip.elk
3)输入测试数据
[root@elasticearch-2 ~]# nc 192.168.1.102 4567
58.19.89.84 GET /index.html 5000 0.2
4)查看ES并在kibana新建索引
六、实战3:配合redis收集日志
使用redis来解耦合,让客户端的日志先输入的redis,这样可以避免同时大量的日志实时导入到ES中导致ES的磁盘IO不足而影响性能甚至在一些特殊情况下存在数据丢失的问题,因而可以将客户端的日志数据先导入到redis/kafka中,在从redis/kafka将数据导入ES,es从redis中拿出数据在进行分析存储和展示
6.1 redis部署
6.1.1 解压redis
[root@web01 ~]# tar zxvf redis-4.0.9.tar.gz -c /usr/local/src
6.1.2 安装部署
[root@web01 redis-4.0.9]#make MALLOC=libc && make install
6.1.3 配置redis
[root@web01 redis-4.0.9]# grep -v '^#' redis.conf
bind 192.168.1.101 #绑定IP
protected-mode no 关闭保护模式
port 6379 #端口
daemonize yes #是否后台运行
databases 16 #数据库
requirepass 123456 认证密码
6.1.4 运行redis数据库
[root@web01 src]# ./redis-server /usr/local/src/redis-4.0.9/redis.conf
6.1.5 查看端口
[root@web01 src]# netstat -antup |grep 6379
tcp 0 0 192.168.1.101:6379 0.0.0.0:* LISTEN 59307/./redis-serve
tcp 0 0 192.168.1.101:6379 192.168.1.102:38590 ESTABLISHED 59307/./redis-serve
tcp 0 0 192.168.1.101:6379 192.168.1.101:60712 ESTABLISHED 59307/./redis-serve
6.1.6 测试redis是否正常
[root@web01 src]# ./redis-cli -h 192.168.1.101
192.168.1.101:6379> auth 123456
OK
192.168.1.101:6379> set name zhangsan
OK
192.168.1.101:6379> get name
"zhangsan"
192.168.1.101:6379>
6.2 安装nginx
6.2.1 安装nginx服务
yum -y install epel-release
yum -y install nginx
6.2.2 配置Nginx的日志格式
将nginx日志转换为json格式,便于kibana进行统计
语法如下:
http {
# log_format main '$remote_addr - $remote_user [$time_local] "$request" ' #将原有的日志格式注释
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log /var/log/nginx/access.log main;
log_format access_json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"client":"$remote_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"status":"$status"}';
access_log /var/log/nginx/access.log access_json;
6.2.3 重启nginx
[root@web02 nginx]# systemctl restart nginx
6.2.4 观察新的nginx的日志格式
{"@timestamp":"2022-11-05T05:29:19+08:00","host":"192.168.1.108","client":"192.168.1.1","size":0,"responsetime":0.000,"upstreamtime":"-","upstreamhost":"-","http_host":"192.168.1.108","url":"/index.html","domain":"192.168.1.108","xff":"-","referer":"-","status":"304"}
6.3 安装filebeat(安装过程如之前一样)
6.3.1 修改filebeat的配置文件(最终需要修改的配置项如下)
filebeat.inputs:
- type: log
- /var/log/nginx/access.log
output.redis:
hosts: ["192.168.1.108:6379"] #这里指的是redis的IP(这里我的redis和nginx,filebeat安装在一起)
key: nginx_log
password: 123456
db: 1
datatype: list
6.3.2 启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
6.3.3 访问nginx,生成一下测试数据
登录redis,测试发现已经有数据了。
[root@server5 src]# ./redis-cli -h 192.168.1.108
192.168.1.108:6379> auth 123456
OK
192.168.1.108:6379> select 1
OK
192.168.1.108:6379[1]> keys *
1) "nginx_log" ##数据已经存在
192.168.1.108:6379[1]>
192.168.1.108:6379[1]> LLEN nginx_log
(integer) 46 ##队列长度
192.168.1.108:6379[1]>
192.168.1.108:6379[1]> LLEN nginx_log
(integer) 53
192.168.1.108:6379[1]>
6.4 配置logstash的匹配规则
6.4.1 在logstash服务器上将日志收集起来并导入ES,如下代码
cat nginxlog.elk
-----
input {
redis {
data_type => "list"
host => "192.168.1.108"
db => "1"
port => "6379"
password => "123456"
key => "nginx_log"
}
}
output {
elasticsearch {
hosts => "192.168.1.100:9200"
index => "nginx_log-%{+YYYY.MM.dd}"
}
}
6.4.2 启动logstash
[root@logstash conf.d]# /usr/local/src/logstash/bin/logstash -f /usr/local/src/logstash/conf.d/nginxlog.elk
6.4.3 查看es是否有数据
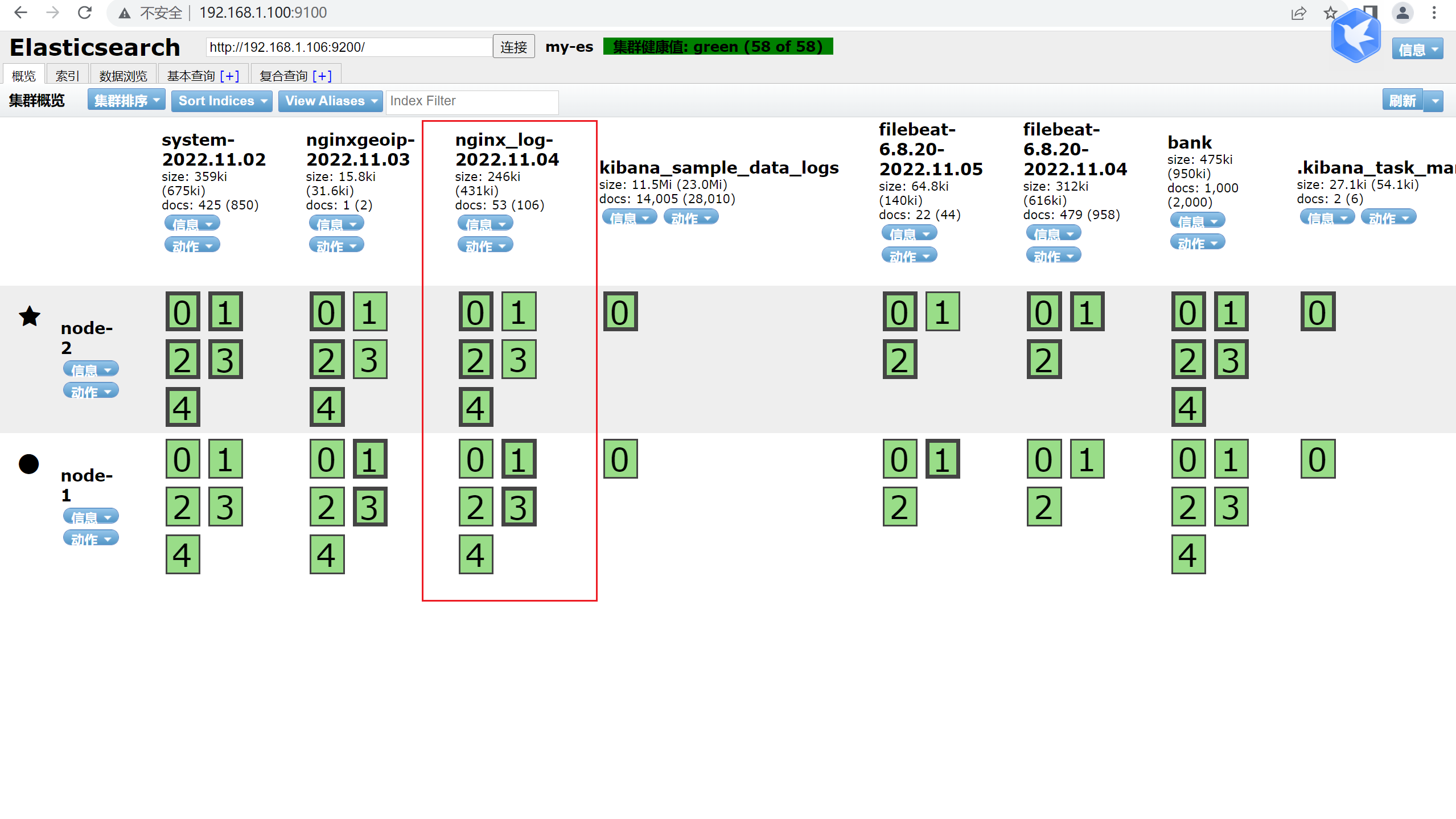
可以看到已经有数据过来了
6.4.4 配置kibana,增加索引
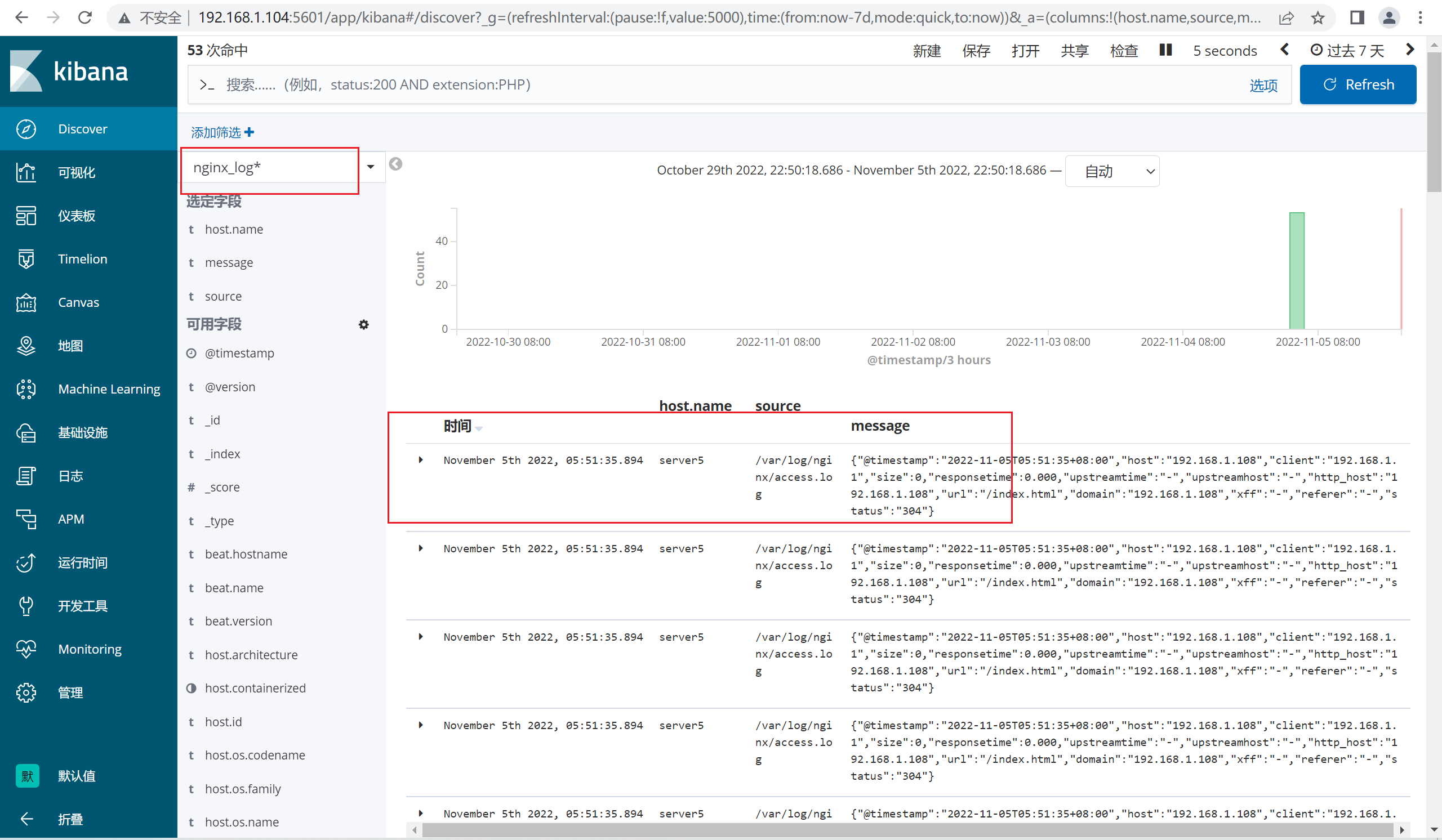
6.4.5 查看redis中的队列长度
192.168.1.108:6379[1]> LLEN ng inx_log
(integer) 0 ##这个值变成了0 ,是因为队列中的数据被“消费”了,所以被清空了
192.168.1.108:6379[1]>
6.5 在logstash中增加过滤的字段
此举是为了能将客户端的IP地址截取出来统计PV的大小
6.5.1 修改logstash中的nginxlog.elk配置
input {
redis {
data_type => "list"
host => "192.168.1.108"
db => "1"
port => "6379"
password => "123456"
key => "nginx_log"
}
}
##增加如下5行
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => "192.168.1.100:9200"
index => "nginx_log-%{+YYYY.MM.dd}"
}
}
6.5.2 重新启动logstash
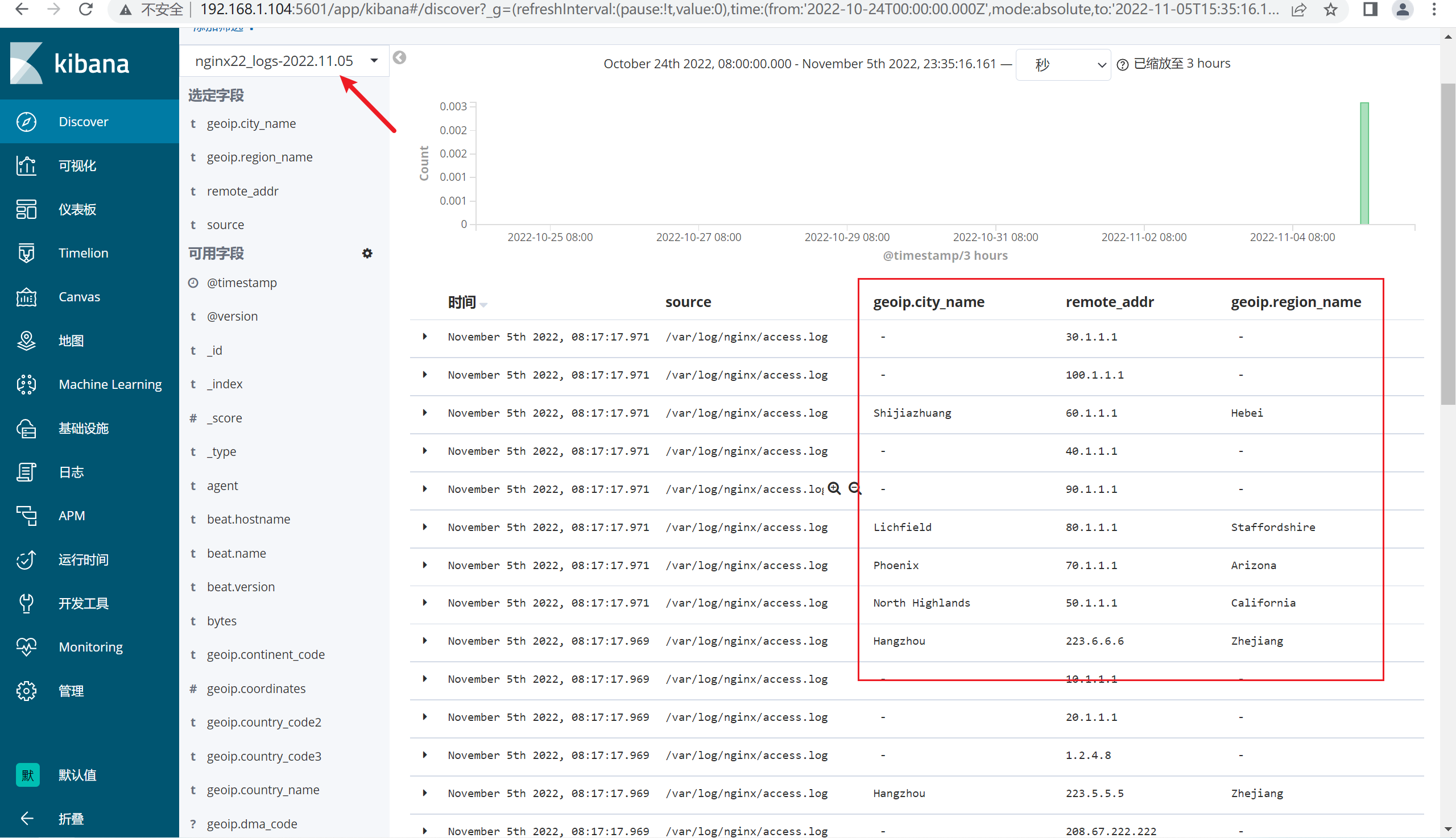
[root@logstash conf.d]# /usr/local/src/logstash/bin/logstash -f /usr/local/src/logstash/conf.d/nginxlog.elk
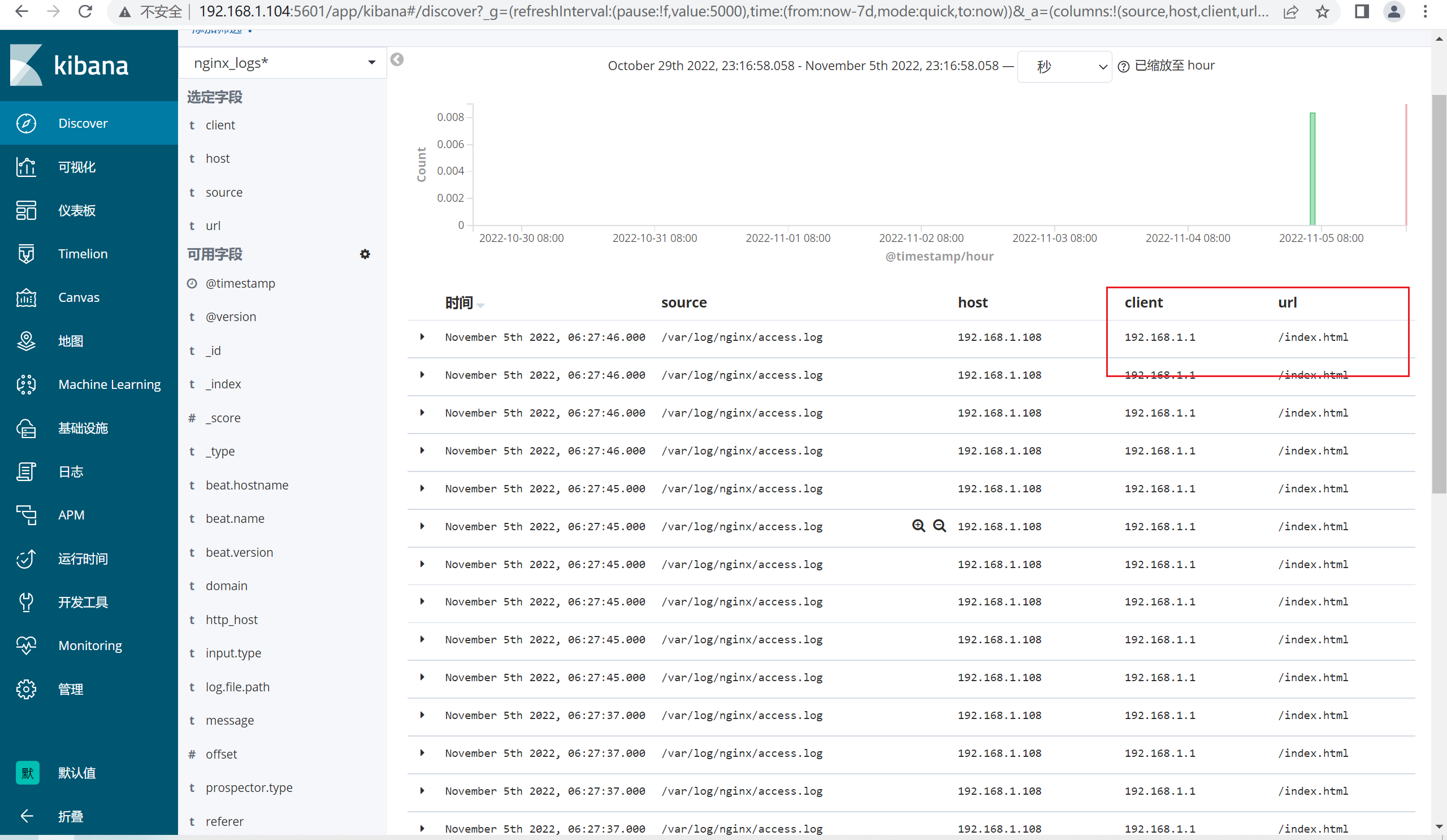
6.5.3 查看kibana
将原来的message字段删除,添加新的字段,比如client,url,这样我们就可以统计PV的大小。
6.6 创建可视化
6.6.1 创建折线图
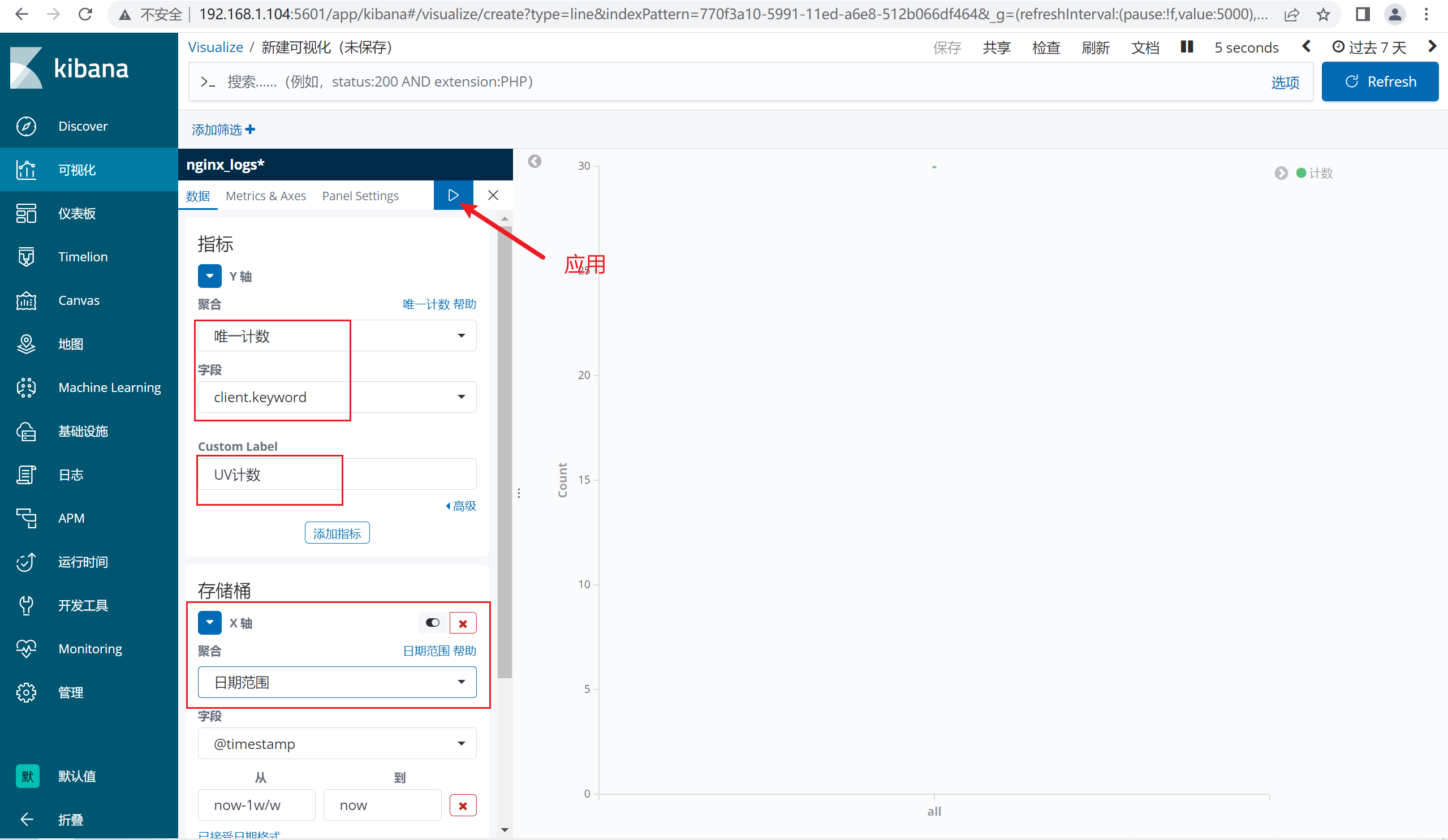
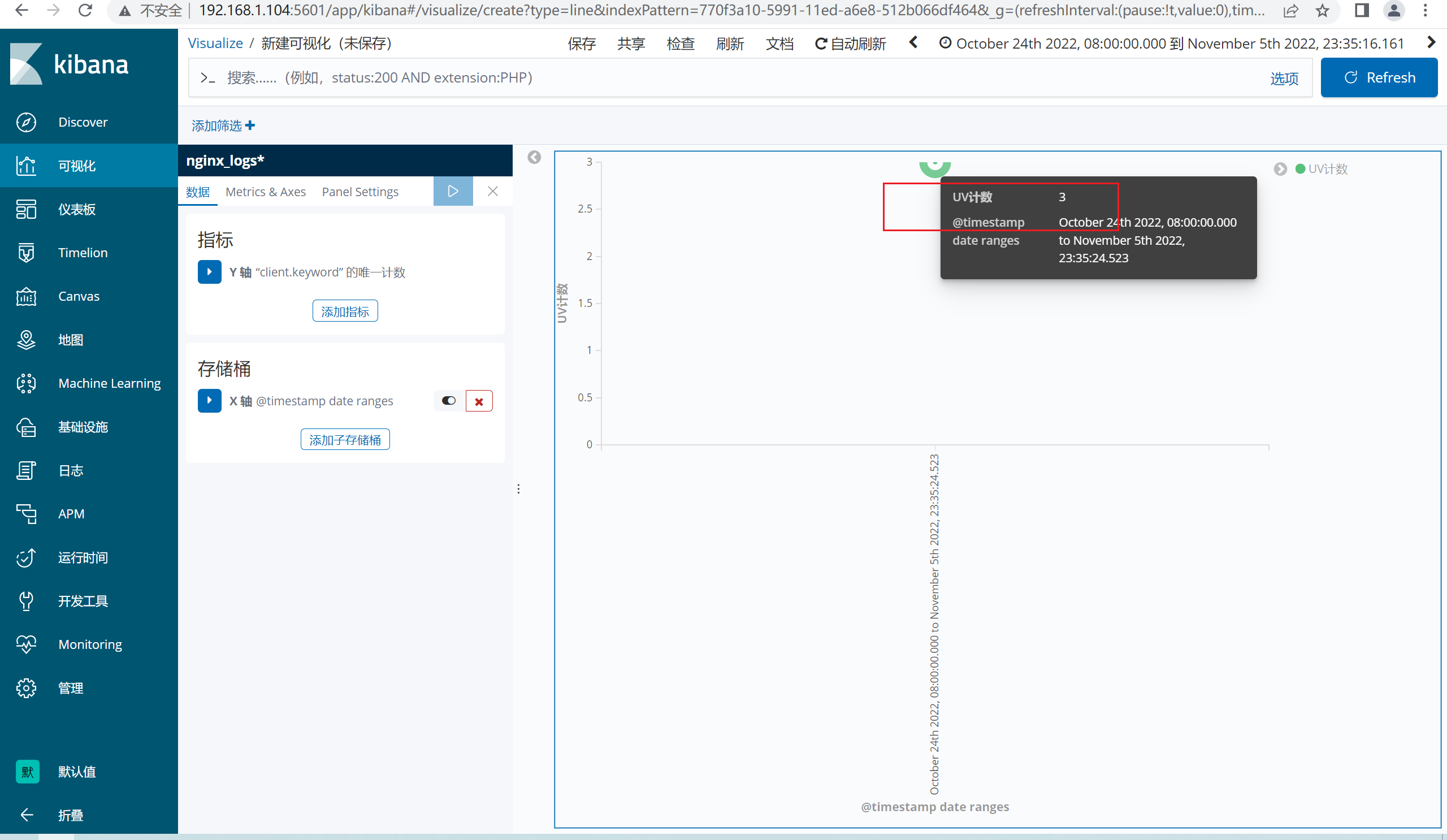
注意:统计如果没有数据,请将服务器的时间同步一下
ntpdate ntp1.aliyun.com
七、综合实战4:es+logstash+redis+filebeat+grok+geoip
我们还可以利用上面的环境,加入grok和geoip来定位客户端的IP地址地域
7.1 配置filebeat和nginx
7.1.1停止Logstash
如果是前台程序,直接ctrl+c停止,后台程序找到pid后停止
7.1.2 修改nginx的日志格式,恢复成原来的格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
7.1.3 重启nginx
[root@server5 nginx]# systemctl restart nginx
7.1.4 将nginx的日志清空
[root@server5 nginx]# >/var/log/nginx/access.log
[root@server5 nginx]# cat /var/log/nginx/access.log
192.168.1.1 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
7.1.5 修改filebeat的key的名称,我这里修改成nginx22_log
output.redis:
hosts: ["192.168.1.108:6379"]
key: nginx22_log
password: 123456
db: 1
datatype: list
7.1.6 重新启动filebeat
[root@server5 filebeat-6.8.20-linux-x86_64]# nohup ./filebeat -e -c filebeat.yml &
7.1.7 查看redis中是否有nginx22_log这个key
[root@server5 filebeat-6.8.20-linux-x86_64]# cd /root/redis-4.0.9/src/
[root@server5 src]# ./redis-cli -h 192.168.1.108
192.168.1.108:6379> auth 123456
OK
192.168.1.108:6379> select 1
OK
192.168.1.108:6379[1]> keys *
1) "nginx22_log"
192.168.1.108:6379[1]> LLEN nginx22_log
(integer) 15
192.168.1.108:6379[1]>
7.2 配置Logstash
7.2.1 编辑过滤配置文件
input {
redis {
data_type => "list"
host => "192.168.1.108"
db => "1"
port => "6379"
password => "123456"
key => "nginx22_log"
}
}
filter
{
grok {
match => [ "message", "%{IPV4:remote_addr} - (%{USERNAME:user}|-) \[%{HTTPDATE:log_timestamp}\] \"%{WORD:method} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} %{QS:agent} %{QS:xforward}"]
}
geoip {
source => "remote_addr"
target => "geoip"
database => "/opt/GeoLite2-City.mmdb"
add_field => ["[geoip][coordinates]", "%{[geoip][longitude]}"]
add_field => ["[geoip][coordinates]", "%{[geoip][latitude]}"]
}
date {
locale => "en"
match => ["time_local", "dd/MMM/yyyy:HH:mm:ss Z"]
}
mutate {
convert => ["[geoip][coordinates]", "float"]
}
}
output {
elasticsearch {
hosts => "192.168.1.106:9200"
index => "nginx22_logs-%{+YYYY.MM.dd}"
}
stdout {
}
7.2.2 启动logstash
[root@logstash conf.d]# /usr/local/src/logstash/bin/logstash -f /usr/local/src/logstash/conf.d/nginxlog.elk
7.2.3 向nginx的配置文件中导入测试日志数据
[root@server5 nginx]# systemctl restart nginx
[root@server5 nginx]# cat access.log
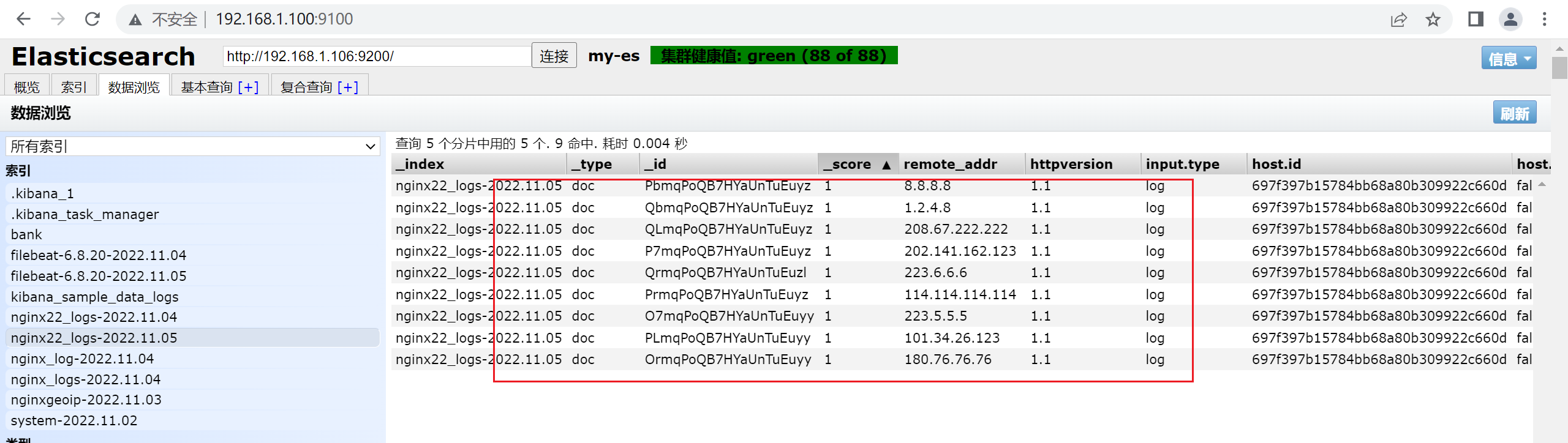
114.114.114.114 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
223.5.5.5 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
223.6.6.6 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
101.34.26.123 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
8.8.8.8 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36""-"
180.76.76.76 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
1.2.4.8 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36""-"
208.67.222.222 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
202.141.162.123 - - [05/Nov/2022:06:59:23 +0800] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36" "-"
7.2.4 查看ES中的数据