


PostgreSQL数据库
PostgreSQL数据库
一、PostgreSQL数据库
1.1 PostgreSQL数据库介绍
官方站点:https://www.postgresql.org/
PostgreSQL 起源于加州大学伯克利分校计算机系,最初设想于 1986 年,当时叫做 Berkley Postgres Project。1995 年,开发者 Andrew Yu 和 Jolly Chen 在 Postgres 中添加了一个 SQL 翻译程序,并在开源社区发布,称为 Postgres95。1996 年,开发者再次对 Postgres95 做了较大的改动,并将其作为 PostgresSQL 6.0 版正式发布。
PostgreSQL是一个强大的开源对象关系数据库系统,它使用并扩展了SQL语言,并结合了许多特性来安全存储和扩展最复杂的数据工作负载。凭借其经过验证的架构、可靠性、数据完整性、健壮的特性集、可扩展性,以及开源社区对该软件持续交付性能和创新解决方案的奉献,赢得了强大的声誉。PostgreSQL可以运行在所有主流的操作系统上,自2001年起就与acid兼容,并且拥有强大的插件,比如流行的PostGIS地理空间数据库扩展器。自从 MySQL 被 Oracle 收购以后,PostgreSQL 逐渐成为了开源关系型数据库的首选。
1.2 历史简介
1977 - 1985年:开发了一个名为INGRES的项目。
- 关系数据库的概念证明。
- 1980年成立Ingres公司。
- 1994年被Computer Associates购买。
1986-1994: POSTGRES
- 开发INGRES中的概念,重点是面向对象和查询语言Quel。
- INGRES的代码基础未被用作POSTGRES的基础。
- 商业化为Illustra(由Informix购买,之后由IBM购买)。
1994-1995: Postgres95
- 1994年增加了对SQL的支持。
- 1995年发布为Postgres95。
- 1996年重新发布为PostgreSQL 6.0。
- 建立PostgreSQL全球开发团队。
1.3 不同数据库对比
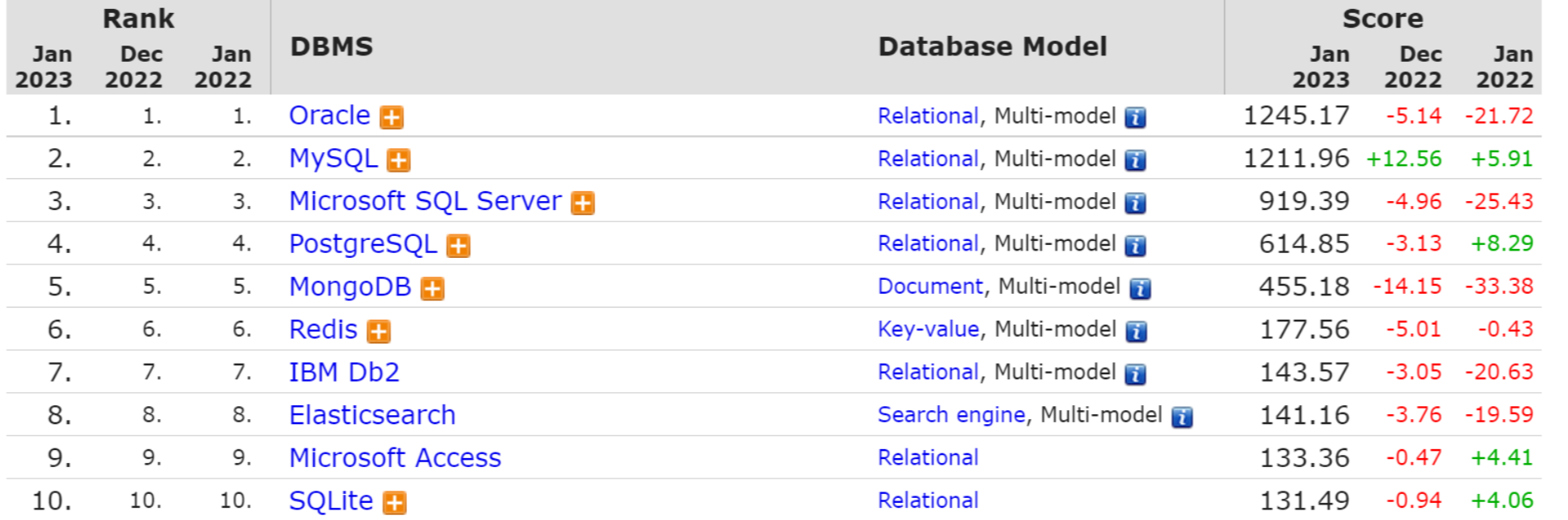
(1)Oracle是大型数据库,Oracle市场占有率达40%,oracle 能在所有主流平台上运行,oracle 安全性高,获得最高认证级别的ISO标准认证,Oracle 性能高,同样Oracle的价格非常高。Oracle安装所用的空间也是很大的Oracle有3G左右,对硬件要求很高,且使用的时候Oracle占用特别大的内存空间和其他机器性能。
(2)sql server 是Microsoft(微软)公司推出的数据库,SQL Server 只能windows上运行,使用最方便,开发最方便,运维最方便,但没有丝毫开放性,操作系统系统稳定对数据库十分重要,不开源,并且安全系数没有Oracle高,sql server没有获得任何安全证书,收费比oracer稍微低一点
(3)MySQL作为一款免费、开源的数据库,Mysql是中小型数据库,
软件体积小,安装使用简单,并且易于维护,安装及维护成本低,安装完后才152M,性能卓越,服务稳定,很少出现异常宕机;
mysql历史悠久,社区及用户非常活跃,遇到问题,可以寻求帮助;并且mysql开放源代码且无版权制约,自主性及使用成本低;
(4)PostgreSQL标榜自己是世界上最先进的开源数据库。PostgreSQL的一些粉丝说它能与Oracle相媲美,而且没有那么昂贵的价格和傲慢的客服。最初是1985年在加利福尼亚大学伯克利分校开发的,作为Ingres数据库的后继。PostgreSQL是完全由社区驱动的开源项目。它提供了单个完整功能的版本,而不像MySQL那样提供了多个不同的社区版、商业版与企业版。PostgreSQL基于自由的BSD/MIT许可,组织可以使用、复制、修改和重新分发代码,只需要提供一个版权声明即可。
PostgreSQl配合的开源软件很多,有很多分布式集群软件,如pgpool、pgcluster、slony、plploxy等等,很容易做读写分离、负载均衡、数据水平拆分等方案 ;
1.4 PostgreSQL优缺点
优点:
稳定可靠:PostgreSQL是唯一能做到数据零丢失的开源数据库。目前有报道称国内外有部分银行使用PostgreSQL数据库。
开源省钱: PostgreSQL数据库是开源的、免费的,而且使用的是类BSD协议,在使用和二次开发上基本没有限制。
支持广泛:PostgreSQL 数据库支持大量的主流开发语言,包括C、C++、Perl、Python、Java、Tcl以及PHP等。
PostgreSQL社区活跃:PostgreSQL基本上每3个月推出一个补丁版本,这意味着已知的Bug很快会被修复,有应用场景的需求也会及时得到响应。
PostgreSQL是跨平台的,可以在许多操作系统上运行,如Linux,FreeBSD,OS X,Solaris和Microsoft Windows等。
缺点:
1、学习的成本相对比较高
2.对于简单而繁重的读取操作,超过了PostgreSQL的杀伤力,可能会出现比同行(如MySQL)更低的性能。
3.按给出的该工具的性质,从普及度来说它还缺乏足够后台支撑,尽管有大量的部署——这可能会影响能够获得支持的容易程度
1.5 PostgreSQL的特点
- PostgreSQL可在所有主要操作系统(即Linux,UNIX(AIX,BSD,HP-UX,SGI IRIX,Mac OS X,Solaris,Tru64)和Windows等)上运行。
- PostgreSQL支持文本,图像,声音和视频,并包括用于C/C++,Java,Perl,Python,Ruby,Tcl和开放数据库连接(ODBC)的编程接口。
- PostgreSQL支持SQL的许多功能,例如复杂SQL查询,SQL子选择,外键,触发器,视图,事务,多进程并发控制(MVCC),流式复制(9.0),热备(9.0))。
- 在PostgreSQL中,表可以设置为从“父”表继承其特征。
- 可以安装多个扩展以向PostgreSQL添加附加功能。
1.6 PostgreSQL管理工具
有一些开放源码以及付费工具可用作PostgreSQL的前端工具。 这里列出几个被广泛使用的工具:
1)psql
它是一个命令行工具,也是管理PostgreSQL的主要工具。 pgAdmin是PostgreSQL的免费开源图形用户界面管理工具。
2)phpPgAdmin
它是用PHP编写的PostgreSQL的基于Web的管理工具。 它基于phpMyAdmin工具管理MySQL功能来开发。它可以用作PostgreSQL的前端工具。
3)Navicat
一个图形化管理工具,可以支持众多的数据库包括云数据库
二、安装 PostgreSQL数据库
PostgreSQL数据库安装可以分为二进制安装和源码安装的方式,也可以适应不同的系统平台安装,如Linux,FreeBSD,OS X,Solaris和Microsoft Windows等。这里我们以CentOS7.9平台为例
2.1 yum方式安装
#请在 RHEL6或者7上安装
[root@postgresql ~]# yum install postgresql-server
#或RHEL 8 和 Fedora 上的dnf命令
[root@postgresql ~]#dnf install postgresql-server
您获得哪个版本的 PostgreSQL 将取决于发行版的版本
| 分配 | 版本 |
|---|---|
| RHEL / 洛基 Linux 9 | 13 |
| RHEL / 洛基 Linux / OL 8 | 13、12、10 和 9.6 通过模块 |
| RHEL / CentOS / SL / OL 7 | 9.2(还通过 SCL 提供包 rh-postgresql10、rh-postgresql96、rh-postgresql95 和 rh-postgresql94) |
| RHEL / CentOS / SL / OL 6 | 8.4(还通过 SCL 提供包 rh-postgresql96) |
| 软呢帽 37 | 14 |
| 软呢帽 36 | 14 |
2.2 源码编译安装
源码下载地址:https://www.postgresql.org/ftp/source/
2.2.1 下载源码
2.2.2 上传源码包

2.2.3 创建用户及用户组
# 创建postgres用户组
[root@postgresql ~]# groupadd postgres
# 创建postgres用户,用户位于postgres组内
[root@postgresql ~]# useradd -g postgres postgres
# 为postgres用户设置密码
[root@postgresql ~]# passwd postgres
2.2.4 解压安装
[root@postgresql ~]# tar xf postgresql-12.3.tar.gz -C /home/postgres && cd /home/postgres
[root@postgresql postgres]# chown -R postgres.postgres postgresql-12.3
2.2.5 安装依赖
[root@postgresql postgres]# yum -y install make gcc
2.2.6 创建安装目录和数据目录
[root@postgresql postgres]# mkdir -p /data/pg12 /data/pgdata5432 && chown postgres.postgres /data/pg12 /data/pgdata5432
2.2.7 编译安装
[root@postgresql postgresql-12.3]$ su postgres
[postgres@postgresql postgresql-12.3]$ cd /home/postgres/postgresql-12.3/
[postgres@postgresql postgresql-12.3]$ ./configure --prefix=/data/pg12 --without-readline --without-zlib
[postgres@postgresql postgresql-12.3]$ make -j 4 && make install
安装完毕后目录下有这些文件
[postgres@postgresql pg12]$ ll
total 12
drwxrwxr-x 2 postgres postgres 4096 Jun 25 14:50 bin
drwxrwxr-x 4 postgres postgres 4096 Jun 25 14:50 include
drwxrwxr-x 4 postgres postgres 4096 Jun 25 14:50 lib
drwxrwxr-x 3 postgres postgres 24 Jun 25 14:50 share
2.2.8 配置用户环境变量
回到postgres用户的家目录
[postgres@postgresql ~]$ vim .bash_profile
PGHOME=/data/pg12
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$PGHOME/bin
[postgres@postgresql ~]$ source .bash_profile
2.3 初始化数据库
[postgres@postgresql ~]$ initdb /data/pgdata5432 #这个目录提前创建并授权给postgres
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.UTF-8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /data/pgdata5432 ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Asia/Shanghai
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
pg_ctl -D /data/pgdata5432 -l logfile start
[postgres@postgresql ~]$
初始化完毕后,pgdata5432有如下文件
[postgres@postgresql pgdata5432]$ ll
total 52
drwx------ 5 postgres postgres 41 Jun 25 14:59 base
drwx------ 2 postgres postgres 4096 Jun 25 14:59 global
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_commit_ts
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_dynshmem
-rw------- 1 postgres postgres 4513 Jun 25 14:59 pg_hba.conf
-rw------- 1 postgres postgres 1636 Jun 25 14:59 pg_ident.conf
drwx------ 4 postgres postgres 68 Jun 25 14:59 pg_logical
drwx------ 4 postgres postgres 36 Jun 25 14:59 pg_multixact
drwx------ 2 postgres postgres 18 Jun 25 14:59 pg_notify
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_replslot
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_serial
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_snapshots
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_stat
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_stat_tmp
drwx------ 2 postgres postgres 18 Jun 25 14:59 pg_subtrans
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_tblspc
drwx------ 2 postgres postgres 6 Jun 25 14:59 pg_twophase
-rw------- 1 postgres postgres 3 Jun 25 14:59 PG_VERSION
drwx------ 3 postgres postgres 60 Jun 25 14:59 pg_wal
drwx------ 2 postgres postgres 18 Jun 25 14:59 pg_xact
-rw------- 1 postgres postgres 88 Jun 25 14:59 postgresql.auto.conf
-rw------- 1 postgres postgres 26635 Jun 25 14:59 postgresql.conf
2.4 修改pg配置文件
修改监听地、服务端口、权限,pg配置文件是 postgresql.conf
[postgres@postgresql pgdata5432]$ vim postgresql.conf
#添加如下2项
listen_addresses = '*'
port = 5432
2.5 管理数据库
启动
[postgres@postgresql pgdata5432]$pg_ctl -D /data/pgdata5432 -l logfile start
停止
[postgres@postgresql pgdata5432]$pg_ctl -D /data/pgdata5432 -l logfile stop
重启
[postgres@postgresql pgdata5432]$pg_ctl -D /data/pgdata5432 -l logfile restart
查看状态
[postgres@postgresql pgdata5432]$pg_ctl -D /data/pgdata5432 -l logfile status
关闭数据库因为紧急程度,有多种模式
smart:等待活动事务结束,并且等待客户端主动断开连接后才关闭
fast:回滚所有活动的事务,并主动断开客户端的连接
immediate:立刻关闭数据库,下一次启动会进入到恢复模式
三种情况可以分别简写为:-ms -mf -mi
例如:
[postgres@postgresql pgdata5432]$ pg_ctl -D /data/pgdata5432 -ms stop
[postgres@postgresql pgdata5432]$ pg_ctl -D /data/pgdata5432 -mf stop
[postgres@postgresql pgdata5432]$ pg_ctl -D /data/pgdata5432 -mi stop
2.6 登录数据库
2.6.1 本地登录
[postgres@postgresql pgdata5432]$ psql -U postgres -p 5432
psql (12.3)
Type "help" for help.
postgres=# ALTER USER postgres WITH PASSWORD 'qwe123'; #修改用户密码
ALTER ROLE
或者
[postgres@postgresql pgdata5432]$ psql postgres://postgres:qwe123@192.168.1.20:5432/postgres
psql (12.3)
Type "help" for help.
postgres=#
username:连接数据的用户名,默认值是postgres
password:密码,默认值是postgres
host:主机名,默认值是localhost
port:端口,默认值是5432
dbname:要连接的数据库名,默认值是postgres
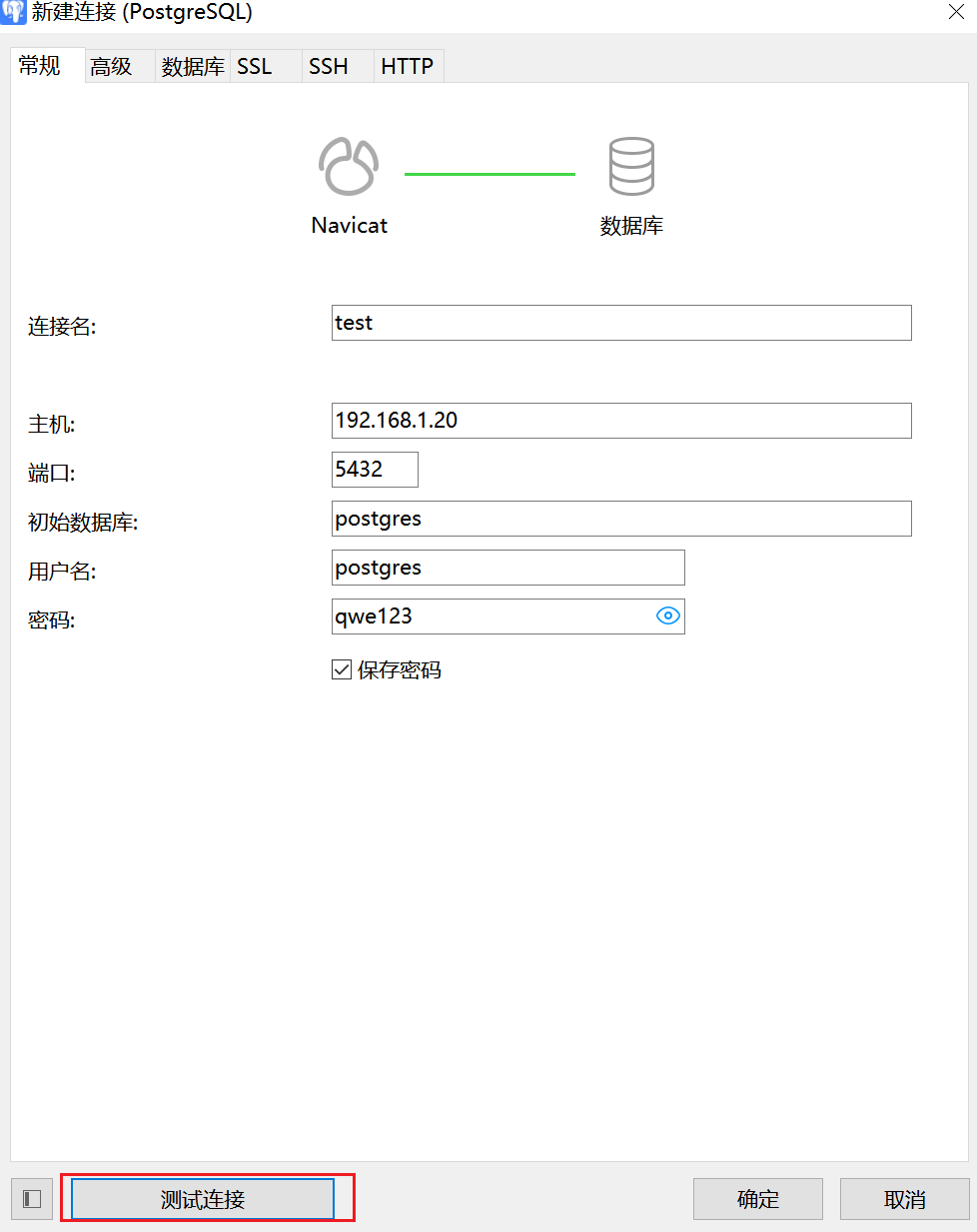
2.6.2 远程登录
[postgres@postgresql pgdata5432]$ vim pg_hba.conf
#添加如下行:
host all all 192.168.1.0/24 md5
2.7 SQL语法命令
2.7.1 控制台命令(元命令)
postgres=# \?
General
\copyright show PostgreSQL usage and distribution terms
\g [FILE] or ; execute query (and send results to file or |pipe)
\h [NAME] help on syntax of SQL commands, * for all commands
\q quit psql
Query Buffer
\e [FILE] [LINE] edit the query buffer (or file) with external editor
\ef [FUNCNAME [LINE]] edit function definition with external editor
\p show the contents of the query buffer
\r reset (clear) the query buffer
\s [FILE] display history or save it to file
\w FILE write query buffer to file
Input/Output
\copy ... perform SQL COPY with data stream to the client host
\echo [STRING] write string to standard output
\i FILE execute commands from file
\ir FILE as \i, but relative to location of current script
\o [FILE] send all query results to file or |pipe
\qecho [STRING] write string to query output stream (see \o)
Informational
(options: S = show system objects, + = additional detail)
\d[S+] list tables, views, and sequences
\d[S+] NAME describe table, view, sequence, or index
\da[S] [PATTERN] list aggregates
\db[+] [PATTERN] list tablespaces
\dc[S+] [PATTERN] list conversions
\dC[+] [PATTERN] list casts
\dd[S] [PATTERN] show object descriptions not displayed elsewhere
\ddp [PATTERN] list default privileges
\dD[S+] [PATTERN] list domains
\det[+] [PATTERN] list foreign tables
\des[+] [PATTERN] list foreign servers
\deu[+] [PATTERN] list user mappings
\dew[+] [PATTERN] list foreign-data wrappers
\df[antw][S+] [PATRN] list [only agg/normal/trigger/window] functions
\dF[+] [PATTERN] list text search configurations
\dFd[+] [PATTERN] list text search dictionaries
\dFp[+] [PATTERN] list text search parsers
\dFt[+] [PATTERN] list text search templates
\dg[+] [PATTERN] list roles
\di[S+] [PATTERN] list indexes
\dl list large objects, same as \lo_list
\dL[S+] [PATTERN] list procedural languages
\dn[S+] [PATTERN] list schemas
\do[S] [PATTERN] list operators
\dO[S+] [PATTERN] list collations
\dp [PATTERN] list table, view, and sequence access privileges
\drds [PATRN1 [PATRN2]] list per-database role settings
\ds[S+] [PATTERN] list sequences
\dt[S+] [PATTERN] list tables
\dT[S+] [PATTERN] list data types
\du[+] [PATTERN] list roles
\dv[S+] [PATTERN] list views
\dE[S+] [PATTERN] list foreign tables
\dx[+] [PATTERN] list extensions
\l[+] list all databases
\sf[+] FUNCNAME show a function's definition
\z [PATTERN] same as \dp
Formatting
\a toggle between unaligned and aligned output mode
\C [STRING] set table title, or unset if none
\f [STRING] show or set field separator for unaligned query output
\H toggle HTML output mode (currently off)
\pset NAME [VALUE] set table output option
(NAME := {format|border|expanded|fieldsep|fieldsep_zero|footer|null|
numericlocale|recordsep|recordsep_zero|tuples_only|title|tableattr|pager})
\t [on|off] show only rows (currently off)
\T [STRING] set HTML <table> tag attributes, or unset if none
\x [on|off|auto] toggle expanded output (currently off)
Connection
\c[onnect] {[DBNAME|- USER|- HOST|- PORT|-] | conninfo}
connect to new database (currently "postgres")
\encoding [ENCODING] show or set client encoding
\password [USERNAME] securely change the password for a user
\conninfo display information about current connection
Operating System
\cd [DIR] change the current working directory
\setenv NAME [VALUE] set or unset environment variable
\timing [on|off] toggle timing of commands (currently off)
\! [COMMAND] execute command in shell or start interactive shell
Variables
\prompt [TEXT] NAME prompt user to set internal variable
\set [NAME [VALUE]] set internal variable, or list all if no parameters
\unset NAME unset (delete) internal variable
Large Objects
\lo_export LOBOID FILE
\lo_import FILE [COMMENT]
\lo_list
\lo_unlink LOBOID large object operations
基本规则
- 使用\开头,后面接简写
- 简写命令,一般都可以加+,获得更加详细的信息
- \d命令指describe,是最重要的元命令。默认是显示表、视图和序列,但往往后面可以跟其他单字母,扩展命令的使用
- \d加S(大写),显示的是包括系统表的关系
- \d等命令后可以明确紧跟对象名,精确显示该对象
- 可以在psql里执行shell命令,改变当前目录等
常见案例:
-
查看所有数据库列表信息
postgres-# \l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows) -
列出当前数据库所有表格
postgres-# \t Tuples only is on. -
查看表空间
postgres-# \db pg_default | postgres | pg_global | postgres | -
列出所有用户
postgres-# \du postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {} -
连接数据库
postgres-# \c postgres You are now connected to database "postgres" as user "postgres". -
退出
postgres-# \q
2.7.2 基础 SQL命令
2.7.2.1 创建数据库
postgres=# create database t1;
CREATE DATABASE
2.7.2.2 创建表
t1=# create table u1(id int primary key NOT NULL,name varchar(50));
CREATE TABLE
2.7.2.3 插值
单行插入
t1=# insert into u1 values(1,'zhangsan');
INSERT 0 1
多行插入
t1=# insert into u1 (id,name) values (2,'lisi'),(3,'wangwu');
INSERT 0 2
2.7.2.4 查询
t1=# select * from u1;
1 | zhangsan
2 | lisi
3 | wangwu
2.7.2.5 删除表
DROP TABLE 语法格式如下:
DROP TABLE table_name;
t1=# \d
public | u1 | table | postgres
t1=# drop table u1;
DROP TABLE
2.7.2.6 删除数据库
删除数据库可以使用如下2种办法删除
- 1、使用 DROP DATABASE SQL 语句来删除。
- 2、使用 dropdb 命令来删除
注意:dropdb只是drop database的包装器, 命令只能由超级管理员或数据库拥有者执行。
postgres=# drop database t1;
DROP DATABASE
2.7.3 PostgreSQL 运算符
2.7.3.1 算术运算符
假设变量 a 为 2,变量 b 为 3,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | a + b 结果为 5 |
| - | 减 | a - b 结果为 -1 |
| * | 乘 | a * b 结果为 6 |
| / | 除 | b / a 结果为 1 |
| % | 模(取余) | b % a 结果为 1 |
| ^ | 指数 | a ^ b 结果为 8 |
| |/ | 平方根 | |/ 25.0 结果为 5 |
| ||/ | 立方根 | ||/ 27.0 结果为 3 |
| ! | 阶乘 | 5 ! 结果为 120 |
| !! | 阶乘(前缀操作符) | !! 5 结果为 120 |
实例
t1=# select 2+3;
?column?
----------
5
(1 row)
t1=# select 2*3;
?column?
----------
6
(1 row)
t1=# select 10/5;
?column?
----------
2
(1 row)
t1=# select 12%5;
?column?
----------
2
(1 row)
t1=# select 2^3;
?column?
----------
8
(1 row)
t1=# select |/ 25.0;
?column?
----------
5
(1 row)
t1=# select ||/ 27.0;
?column?
----------
3
(1 row)
t1=# select 5 !;
?column?
----------
120
(1 row)
t1=# select !!5;
?column?
----------
120
(1 row)
2.7.3.2 比较运算符
假设变量 a 为 10,变量 b 为 20,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 等于 | (a = b) 为 false。 |
| != | 不等于 | (a != b) 为 true。 |
| <> | 不等于 | (a <> b) 为 true。 |
| > | 大于 | (a > b) 为 false。 |
| < | 小于 | (a < b) 为 true。 |
| >= | 大于等于 | (a >= b) 为 false。 |
| <= | 小于等于 | (a <= b) 为 true。 |
实例
创建 COMPANY 表,数据内容如下(SQL文件见附件):
t1=# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
读取 SALARY 字段大于 50000 的数据:
t1=# SELECT * FROM COMPANY WHERE SALARY > 50000;
id | name | age |address | salary
----+-------+-----+-----------+--------
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(2 rows)
读取 SALARY 字段等于 20000 的数据:
t1=# SELECT * FROM COMPANY WHERE SALARY = 20000;
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
(2 rows)
读取 SALARY 字段不等于 20000 的数据:
t1=# SELECT * FROM COMPANY WHERE SALARY != 20000;
id | name | age | address | salary
----+-------+-----+-------------+--------
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(5 rows)
t1=# SELECT * FROM COMPANY WHERE SALARY <> 20000;
id | name | age | address | salary
----+-------+-----+------------+--------
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(5 rows)
读取 SALARY 字段大于等于 65000 的数据:
t1=# SELECT * FROM COMPANY WHERE SALARY >= 65000;
id | name | age | address | salary
----+-------+-----+-----------+--------
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(2 rows)
2.7.3.3 逻辑运算符
PostgreSQL 逻辑运算符有以下几种:
| 序号 | 运算符 & 描述 |
|---|---|
| 1 | AND逻辑与运算符。如果两个操作数都非零,则条件为真。PostgresSQL 中的 WHERE 语句可以用 AND 包含多个过滤条件。 |
| 2 | NOT逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。PostgresSQL 有 NOT EXISTS, NOT BETWEEN, NOT IN 等运算符。 |
| 3 | OR逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。PostgresSQL 中的 WHERE 语句可以用 OR 包含多个过滤条件。 |
SQL 使用三值的逻辑系统,包括 true、false 和 null,null 表示"未知"。
a | b | a AND b | a OR b |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| TRUE | FALSE | FALSE | TRUE |
| TRUE | NULL | NULL | TRUE |
| FALSE | FALSE | FALSE | FALSE |
| FALSE | NULL | FALSE | NULL |
| NULL | NULL | NULL | NULL |
a | NOT*a* |
|---|---|
| TRUE | FALSE |
| FALSE | TRUE |
| NULL | NULL |
实例
创建 COMPANY 表,数据内容如下:
t1=# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
读取 AGE 字段大于等于 25 且 SALARY 字段大于等于 6500 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 6500;
id | name | age | address | salary
----+-------+-----+-----------------------------------------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(4 rows)
读取 AGE 字段大于等于 25 或 SALARY 字段大于 6500 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 6500;
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
8 | Paul | 24 | Houston | 20000
9 | James | 44 | Norway | 5000
10 | James | 45 | Texas | 5000
(10 rows)
读取 SALARY 字段不为 NULL 的数据:
t1=# SELECT * FROM COMPANY WHERE SALARY IS NOT NULL;
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
8 | Paul | 24 | Houston | 20000
9 | James | 44 | Norway | 5000
10 | James | 45 | Texas | 5000
(10 rows)
2.7.3.4 位运算符
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示:
| p | q | p & q | p| q | | :- | :- | :---- | :---- | | 0 | 0 | 0 | 0 | | 0 | 1 | 0 | 1 | | 1 | 1 | 1 | 1 | | 1 | 0 | 0 | 1 |
假设如果 A = 60,且 B = 13,现在以二进制格式表示,它们如下所示:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
下表显示了 PostgreSQL 支持的位运算符。假设变量 A 的值为 60,变量 B 的值为 13,则:
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与操作,按二进制位进行"与"运算。运算规则:0&0=0; 0&1=0; 1&0=0; 1&1=1; | (A & B) 将得到 12,即为 0000 1100 |
| | | 按位或运算符,按二进制位进行"或"运算。运算规则:`0 | 0=0; 0 |
| # | 异或运算符,按二进制位进行"异或"运算。运算规则:0#0=0; 0#1=1; 1#0=1; 1#1=0; | (A # B) 将得到 49,即为 0011 0001 |
| ~ | 取反运算符,按二进制位进行"取反"运算。运算规则:~1=0; ~0=1; | (~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
| << | 二进制左移运算符。将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。 | A >> 2 将得到 15,即为 0000 1111 |
实例
t1=# select 60 | 13;
?column?
----------
61
(1 row)
t1=# select 60 & 13;
?column?
----------
12
(1 row)
t1=# select (~60);
?column?
----------
-61
(1 row)
t1=# select (60 << 2);
?column?
----------
240
(1 row)
t1=# select (60 >> 2);
?column?
----------
15
(1 row)
t1=# select 60 # 13;
?column?
----------
49
(1 row)
2.7.4 PostgreSQL WHERE 子句
在 PostgreSQL 中,当我们需要根据指定条件从单张表或者多张表中查询数据时,就可以在 SELECT 语句中添加 WHERE 子句,从而过滤掉我们不需要数据。
WHERE 子句不仅可以用于 SELECT 语句中,同时也可以用于 UPDATE,DELETE 等等语句中。
语法:
SELECT column1, column2, columnN
FROM table_name
WHERE [condition1]
我们可以在 WHERE 子句中使用比较运算符或逻辑运算符,例如 >, <, =, LIKE, NOT 等等。
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
以下几个实例我们使用逻辑运算符来读取表中的数据。
2.7.4.1 AND
找出 AGE(年龄) 字段大于等于 25,并且 SALARY(薪资) 字段大于等于 65000 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;
id | name | age | address | salary
----+-------+-----+------------+--------
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(2 rows)
2.7.4.2 OR
找出 AGE(年龄) 字段大于等于 25,或者 SALARY(薪资) 字段大于等于 65000 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(4 rows)
2.7.4.3 NOT NULL
在公司表中找出 AGE(年龄) 字段不为空的记录:
t1=# SELECT * FROM COMPANY WHERE AGE IS NOT NULL;
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(7 rows)
2.7.4.4 LIKE
在 COMPANY 表中找出 NAME(名字) 字段中以 Pa 开头的的数据:
t1=# SELECT * FROM COMPANY WHERE NAME LIKE 'Pa%';
id | name | age |address | salary
----+------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2.7.4.5 IN
以下 SELECT 语句列出了 AGE(年龄) 字段为 25 或 27 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );
id | name | age | address | salary
----+-------+-----+------------+--------
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(3 rows)
2.7.4.6 NOT IN
以下 SELECT 语句列出了 AGE(年龄) 字段不为 25 或 27 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(4 rows)
2.7.4.7 BETWEEN
以下 SELECT 语句列出了 AGE(年龄) 字段在 25 到 27 的数据:
t1=# SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;
id | name | age | address | salary
----+-------+-----+------------+--------
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(3 rows)
2.7.4.8 子查询
以下的 SELECT 语句使用了 SQL 的子查询,子查询语句中读取 SALARY(薪资) 字段大于 65000 的数据,然后通过 EXISTS 运算符判断它是否返回行,如果有返回行则读取所有的 AGE(年龄) 字段。
t1=# SELECT AGE FROM COMPANY
WHERE EXISTS (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
age
-----
32
25
23
25
27
22
24
(7 rows)
以下的 SELECT 语句同样使用了 SQL 的子查询,子查询语句中读取 SALARY(薪资) 字段大于 65000 的 AGE(年龄) 字段数据,然后用 > 运算符查询大于该 AGE(年龄) 字段数据:
t1=# SELECT * FROM COMPANY
WHERE AGE > (SELECT AGE FROM COMPANY WHERE SALARY > 65000);
id | name | age | address | salary
----+------+-----+------------+--------
1 | Paul | 32 | California | 20000
2.7.5 PostgreSQL UPDATE 语句
如果我们要更新在 PostgreSQL 数据库中的数据,我们可以用 UPDATE 来操作。
语法:
以下是 UPDATE 语句修改数据的通用 SQL 语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
- 我们可以同时更新一个或者多个字段。
- 我们可以在 WHERE 子句中指定任何条件。
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
以下实例将更新 COMPANY 表中 id 为 3 的 salary 字段值:
t1=# UPDATE COMPANY SET SALARY = 15000 WHERE ID = 3;
得到结果如下:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
3 | Teddy | 23 | Norway | 15000
从结果上看,COMPANY 表中的 id 为 3 的 salary 字段值已被修改。
以下实例将同时更新 salary 字段和 address 字段的值:
t1=# UPDATE COMPANY SET ADDRESS = 'Texas', SALARY=20000;
得到结果如下:
id | name | age | address | salary
----+-------+-----+---------+--------
1 | Paul | 32 | Texas | 20000
2 | Allen | 25 | Texas | 20000
4 | Mark | 25 | Texas | 20000
5 | David | 27 | Texas | 20000
6 | Kim | 22 | Texas | 20000
7 | James | 24 | Texas | 20000
3 | Teddy | 23 | Texas | 20000
(7 rows)
2.7.6 PostgreSQL DELETE 语句
你可以使用 DELETE 语句来删除 PostgreSQL 表中的数据。
语法:以下是 DELETE 语句删除数据的通用语法:
DELETE FROM table_name WHERE [condition];
如果没有指定 WHERE 子句,PostgreSQL 表中的所有记录将被删除。
一般我们需要在 WHERE 子句中指定条件来删除对应的记录,条件语句可以使用 AND 或 OR 运算符来指定一个或多个。
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
以下 SQL 语句将删除 ID 为 2 的数据:
t1=# DELETE FROM COMPANY WHERE ID = 2;
得到结果如下:
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
(6 rows)
从上面结果可以看出,id 为 2 的数据已被删除。
以下语句将删除整张 COMPANY 表:
DELETE FROM COMPANY;
2.7.7 PostgreSQL LIMIT 子句
PostgreSQL 中的 limit 子句用于限制 SELECT 语句中查询的数据的数量。
带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows]
下面是 LIMIT 子句与 OFFSET 子句一起使用时的语法:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
下面实例将找出限定的数量的数据,即读取 4 条数据:
t1=# SELECT * FROM COMPANY LIMIT 4;
得到以下结果:
id | name | age | address | salary
----+-------+-----+-------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
(4 rows)
但是,在某些情况下,可能需要从一个特定的偏移开始提取记录。
下面是一个实例,从第三位开始提取 3 个记录:
t1=# SELECT * FROM COMPANY LIMIT 3 OFFSET 2;
得到以下结果:
id | name | age | address | salary
----+-------+-----+-----------+--------
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
(3 rows)
2.7.8 PostgreSQL ORDER BY 语句
在 PostgreSQL 中,ORDER BY 用于对一列或者多列数据进行升序(ASC)或者降序(DESC)排列。
语法:ORDER BY 子句的基础语法如下:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
您可以在 ORDER BY 中使用一列或者多列,但是必须保证要排序的列必须存在。
ASC 表示升序,DESC 表示降序。
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
下面实例将对结果根据 AGE 字段值进行升序排列:
t1=# SELECT * FROM COMPANY ORDER BY AGE ASC;
得到以下结果:
id | name | age | address | salary
----+-------+-----+----------------------------------------------------+--------
6 | Kim | 22 | South-Hall | 45000
3 | Teddy | 23 | Norway | 20000
7 | James | 24 | Houston | 10000
4 | Mark | 25 | Rich-Mond | 65000
2 | Allen | 25 | Texas | 15000
5 | David | 27 | Texas | 85000
1 | Paul | 32 | California | 20000
(7 rows)
下面实例将对结果根据 NAME 字段值和 SALARY 字段值进行升序排序:
t1=# SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;
得到以下结果:
id | name | age | address | salary
----+-------+-----+----------------------------------------------------+--------
2 | Allen | 25 | Texas | 15000
5 | David | 27 | Texas | 85000
7 | James | 24 | Houston | 10000
6 | Kim | 22 | South-Hall | 45000
4 | Mark | 25 | Rich-Mond | 65000
1 | Paul | 32 | California | 20000
3 | Teddy | 23 | Norway | 20000
(7 rows)
下面实例将对结果根据NAME字段值进行降序排列:
t1=# SELECT * FROM COMPANY ORDER BY NAME DESC;
得到以下结果:
id | name | age | address | salary
----+-------+-----+----------------------------------------------------+--------
3 | Teddy | 23 | Norway | 20000
1 | Paul | 32 | California | 20000
4 | Mark | 25 | Rich-Mond | 65000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
5 | David | 27 | Texas | 85000
2 | Allen | 25 | Texas | 15000
(7 rows)
2.7.9 PostgreSQL GROUP BY 语句
在 PostgreSQL 中,GROUP BY 语句和 SELECT 语句一起使用,用来对相同的数据进行分组。
GROUP BY 在一个 SELECT 语句中,放在 WHRER 子句的后面,ORDER BY 子句的前面。
语法:
下面给出了 GROUP BY 子句的基本语法:
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
GROUP BY 子句必须放在 WHERE 子句中的条件之后,必须放在 ORDER BY 子句之前。
在 GROUP BY 子句中,你可以对一列或者多列进行分组,但是被分组的列必须存在于列清单中。
实例:
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
下面实例将根据 NAME 字段值进行分组,找出每个人的工资总额:
t1=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME;
得到以下结果:
name | sum
-------+-------
Teddy | 20000
Paul | 20000
Mark | 65000
David | 85000
Allen | 15000
Kim | 45000
James | 10000
(7 rows)
现在我们添加使用下面语句在 CAMPANY 表中添加三条记录:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00);
INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00);
INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
现在 COMPANY 表中存在重复的名称,数据如下:
id | name | age | address | salary
----+-------+-----+--------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
8 | Paul | 24 | Houston | 20000
9 | James | 44 | Norway | 5000
10 | James | 45 | Texas | 5000
(10 rows)
现在再根据 NAME 字段值进行分组,找出每个客户的工资总额:
t1=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME;
这时的得到的结果如下:
name | sum
-------+-------
Allen | 15000
David | 85000
James | 20000
Kim | 45000
Mark | 65000
Paul | 40000
Teddy | 20000
(7 rows)
下面实例将 ORDER BY 子句与 GROUP BY 子句一起使用:
t1=# SELECT NAME, SUM(SALARY) FROM COMPANY GROUP BY NAME ORDER BY NAME DESC;
得到以下结果:
name | sum
-------+-------
Teddy | 20000
Paul | 40000
Mark | 65000
Kim | 45000
James | 20000
David | 85000
Allen | 15000
(7 rows)
2.7.10 PostgreSQL HAVING 子句
HAVING 子句可以让我们筛选分组后的各组数据。
WHERE 子句在所选列上设置条件,而 HAVING 子句则在由 GROUP BY 子句创建的分组上设置条件。
语法
下面是 HAVING 子句在 SELECT 查询中的位置:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
HAVING 子句必须放置于 GROUP BY 子句后面,ORDER BY 子句前面,下面是 HAVING 子句在 SELECT 语句中基础语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
下面实例将找出根据 NAME 字段值进行分组,并且 name(名称) 字段的计数少于 2 数据:
SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) < 2;
得到以下结果:
name
-------
Teddy
Paul
Mark
David
Allen
Kim
James
(7 rows)
我们往表里添加几条数据:
INSERT INTO COMPANY VALUES (8, 'Paul', 24, 'Houston', 20000.00);
INSERT INTO COMPANY VALUES (9, 'James', 44, 'Norway', 5000.00);
INSERT INTO COMPANY VALUES (10, 'James', 45, 'Texas', 5000.00);
此时,COMPANY 表的记录如下:
id | name | age | address | salary
----+-------+-----+--------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
8 | Paul | 24 | Houston | 20000
9 | James | 44 | Norway | 5000
10 | James | 45 | Texas | 5000
(10 rows)
下面实例将找出根据 name 字段值进行分组,并且名称的计数大于 1 数据:
t1-# SELECT NAME FROM COMPANY GROUP BY name HAVING count(name) > 1;
得到结果如下:
name
-------
Paul
James
(2 rows)
2.7.11 PostgreSQL DISTINCT 关键字
在 PostgreSQL 中,DISTINCT 关键字与 SELECT 语句一起使用,用于去除重复记录,只获取唯一的记录。
我们平时在操作数据时,有可能出现一种情况,在一个表中有多个重复的记录,当提取这样的记录时,DISTINCT 关键字就显得特别有意义,它只获取唯一一次记录,而不是获取重复记录。
语法
用于去除重复记录的 DISTINCT 关键字的基本语法如下:
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
实例
创建 COMPANY 表,数据内容如下:
t1# select * from COMPANY;
id | name | age | address | salary
----+-------+-----+-----------+--------
1 | Paul | 32 | California| 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall| 45000
7 | James | 24 | Houston | 10000
(7 rows)
让我们插入两条数据:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (8, 'Paul', 32, 'California', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
现在数据如下:
id | name | age | address | salary
----+-------+-----+------------+--------
1 | Paul | 32 | California | 20000
2 | Allen | 25 | Texas | 15000
3 | Teddy | 23 | Norway | 20000
4 | Mark | 25 | Rich-Mond | 65000
5 | David | 27 | Texas | 85000
6 | Kim | 22 | South-Hall | 45000
7 | James | 24 | Houston | 10000
8 | Paul | 32 | California | 20000
9 | Allen | 25 | Texas | 15000
(9 rows)
接下来我们找出 COMPANY 表中的所有 NAME:
t1=# SELECT name FROM COMPANY;
得到结果如下:
name
-------
Paul
Allen
Teddy
Mark
David
Kim
James
Paul
Allen
(9 rows)
现在我们在 SELECT 语句中使用 DISTINCT 子句:
t1=# SELECT DISTINCT name FROM COMPANY;
得到结果如下:
name
-------
Teddy
Paul
Mark
David
Allen
Kim
James
(7 rows)
从结果可以看到,重复数据已经被过滤
三、本章小结
本章给大家介绍了一下postgresql的安装和历史,同时重点学习了一些关于postgresql的基础操作,包含数据库的增删改查和基础的逻辑运行,排序等功能,需要重点掌握。

